生成



Agent TARS
Agent TARS 是字节跳动推出的开源多模态 AI 代理工具,支持浏览器、命令行和文件系统的集成,实现复杂任务的自动化执行。其核心功能包括代理工作流、数据处理、代码生成与解释等。基于事件流和模型上下文协议(MCP),Agent TARS 能高效分解任务并实时反馈结果,适用于网页自动化、任务管理、数据分析和代码辅助等多种场景。目前支持 macOS 平台,处于技术预览阶段。



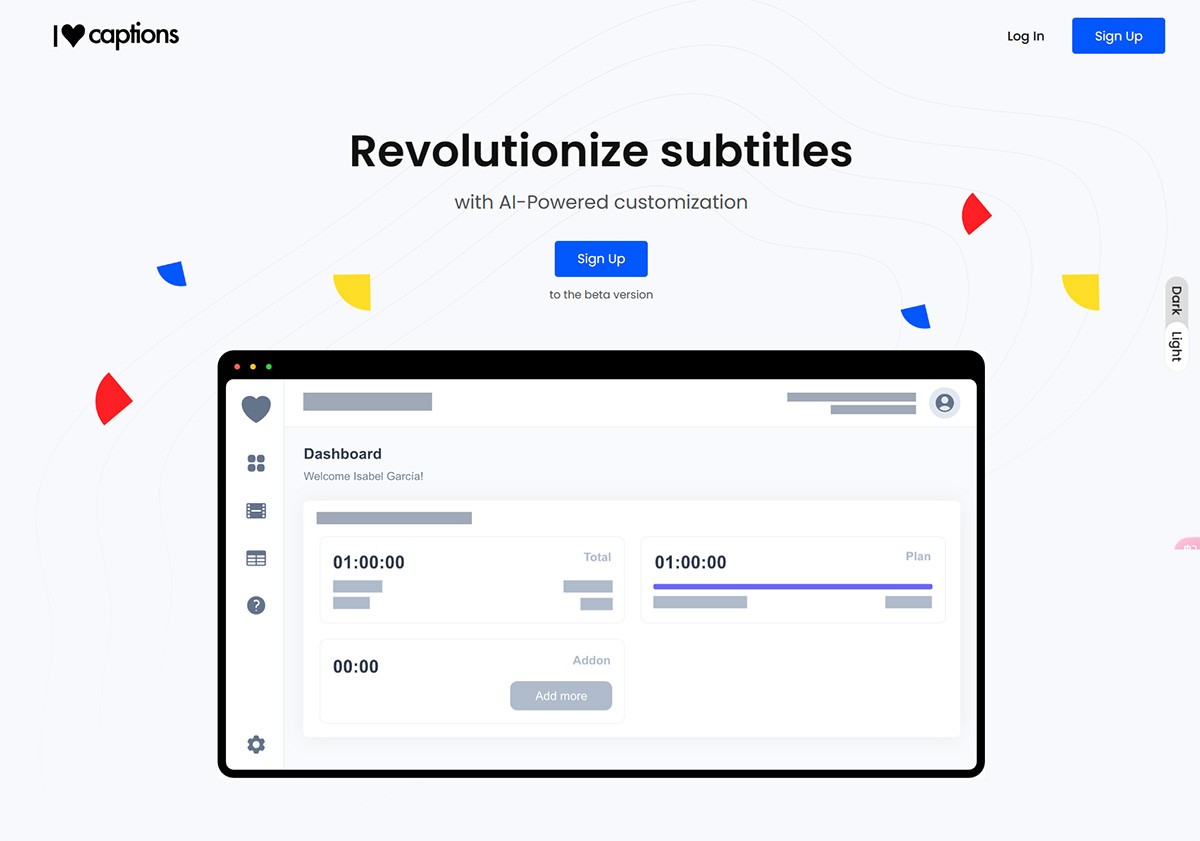
I ♡ Captions
I ♡ Captions轻松为视频和音频创建高质量的字幕。上传您的内容,根据渠道的具体要求生成精确的字幕,将字幕工作量减少高达75%。

