Omni Reference Omni Reference 是 Midjourney V7 提供的一项图像生成辅助功能,允许用户将特定人物、物体或场景嵌入生成图像中。通过 `--oref` 和 `--ow` 参数,用户可灵活控制参考图像的权重与风格融合程度,提升创作精度与多样性。支持 Web 和 Discord 两种平台操作,适用于角色嵌入、产品展示、场景构建等多种应用场景。 AI项目与工具 2025年06月11日 48 点赞 0 评论 806 浏览
Cobra Cobra是由清华大学、香港中文大学和腾讯ARC实验室联合开发的漫画线稿上色框架,采用因果稀疏注意力机制和局部可复用位置编码技术,实现高精度、高效率的自动上色。支持颜色提示调整,提升灵活性与个性化。适用于漫画、动画、插画等多种场景,具有高效的推理能力和良好的扩展性。项目已开源,包含技术论文与模型资源。 AI项目与工具 2025年06月11日 21 点赞 0 评论 806 浏览
OmniCam OmniCam 是一种基于多模态输入的高级视频生成框架,结合大型语言模型与视频扩散模型,实现高质量、时空一致的视频内容生成。支持文本、视频或图像作为输入,精确控制摄像机运动轨迹,具备帧级操作、复合运动、速度调节等功能。采用三阶段训练策略提升生成效果,并引入 OmniTr 数据集增强模型性能。适用于影视、广告、教育及安防等多个领域,提高视频创作效率与质量。 AI项目与工具 2025年06月12日 18 点赞 0 评论 806 浏览
EasyVideoTrans EasyVideoTrans是一款开源的AI视频翻译工具,支持从视频中提取音频并翻译字幕,同时提供多样化的声音风格以实现自然的配音效果。它适用于视频创作者、教育机构、企业培训及品牌宣传等领域,能够快速生成高质量的中文版本视频,满足跨语言沟通的需求。 AI项目与工具 2025年06月12日 39 点赞 0 评论 806 浏览
Tesseract Tesseract是一款开源的光学字符识别(OCR)引擎,支持多语言识别和多种图像格式。其具备高精度的文字识别能力,适用于文档数字化、表格数据提取、发票识别及移动OCR应用等多个场景。支持跨平台运行,并提供丰富的编程接口和自定义训练功能,便于开发者集成和优化识别效果。 AI项目与工具 2025年06月12日 12 点赞 0 评论 806 浏览
华为盘古AI大模型 华为的盘古ai大模型是华为云推出的一项人工智能技术。该大模型包含了多个领域的大型模型,包括自然语言处理(NLP)大模型、计算机视觉(CV)大模型、多模态大模型、预测大模型和科学计算大模型。 Ai平台模型 2025年06月05日 26 点赞 0 评论 806 浏览
PaliGemma 2 PaliGemma 2是一款由Google DeepMind研发的视觉语言模型(VLM),结合了SigLIP-So400m视觉编码器与Gemma 2语言模型,支持多种分辨率的图像处理。该模型具备强大的知识迁移能力和出色的学术任务表现,在OCR、音乐乐谱识别以及医学图像报告生成等方面实现了技术突破。它能够处理多模态任务,包括图像字幕生成、视觉推理等,并支持量化和CPU推理以提高计算效率。 AI项目与工具 2025年06月12日 10 点赞 0 评论 805 浏览
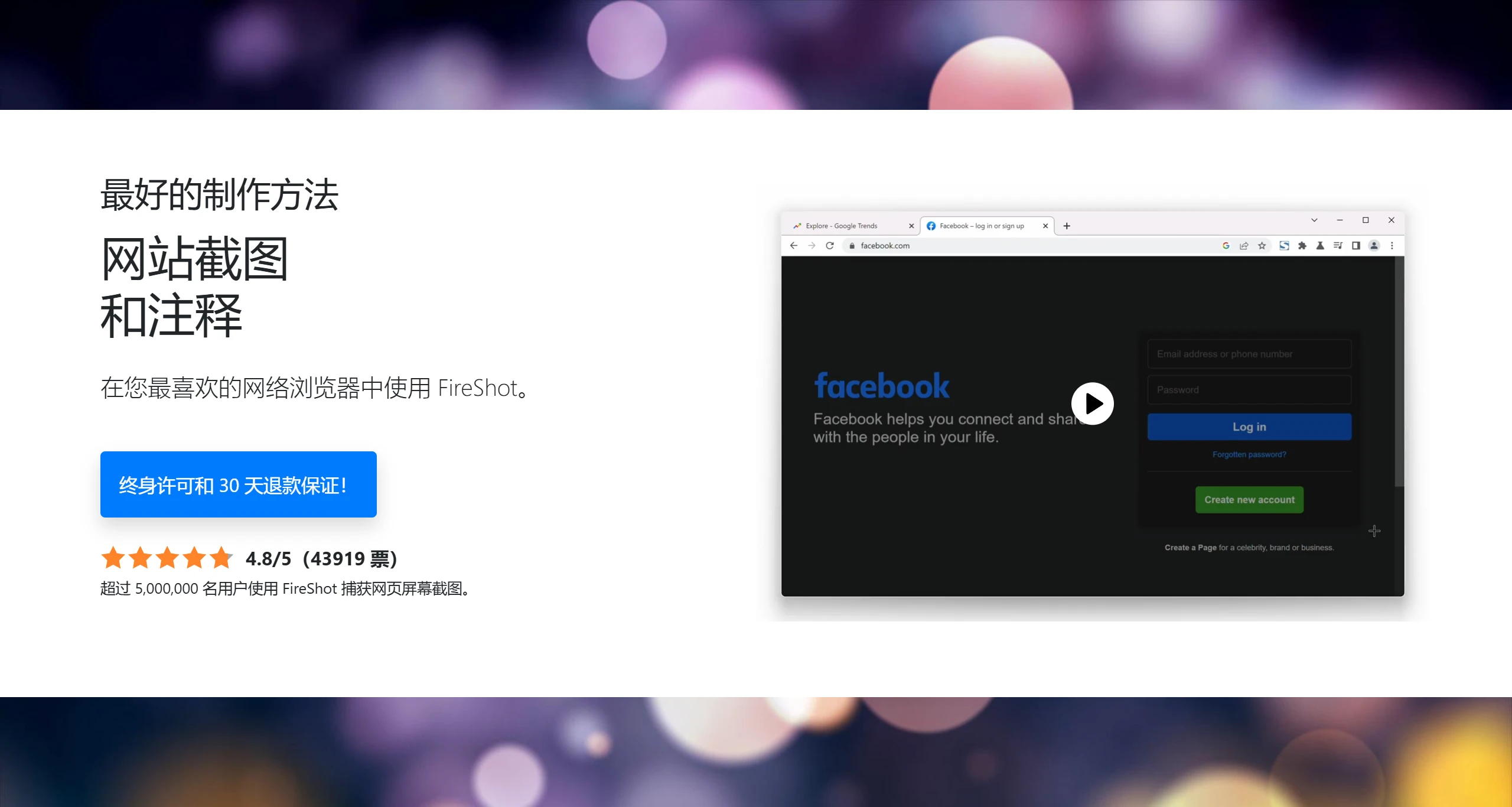
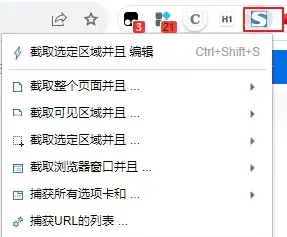
FireShot 一款功能强大的网页截图浏览器插件。用户可以使用FireShot截取整个网页、可视部分或选定区域,并将截图保存为PDF、JPEG、GIF、PNG、BMP等格式。 图片处理 2025年06月05日 84 点赞 0 评论 805 浏览
AI绘画箱 AI绘画箱收录近千个AI绘画工具网站,提供Midjourney、Stable Diffusion等一站式AI绘画工具、AI图片处理工具、AI素材下载、AI视频音频等工具,只做最好的AI绘画工具网址导航站。 Ai学习资源 2025年06月05日 16 点赞 0 评论 805 浏览