生成


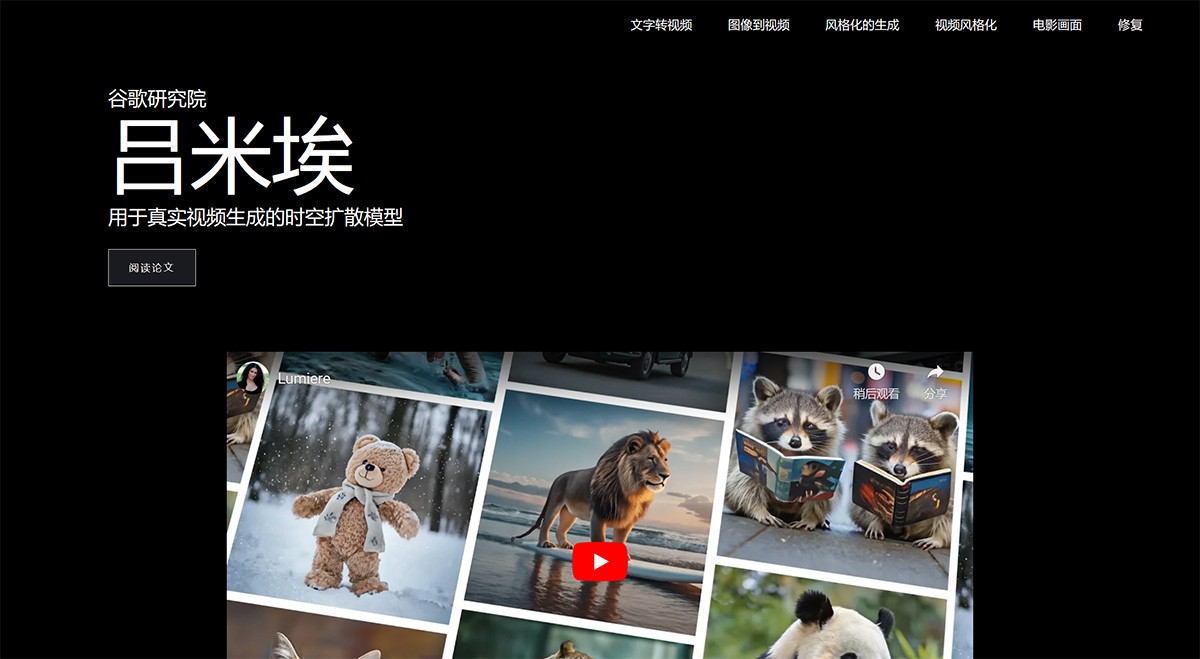








DiffusionGPT
DiffusionGPT是一款基于大型语言模型的开源文本到图像生成系统,由字节跳动与中山大学联合开发。它采用思维树和优势数据库技术,能够解析和处理多样化的文本提示,生成高质量图像。系统通过多模型的选择与集成、基于人类反馈的优化以及高效的图像生成执行,实现了从文本到图像的无缝转换。DiffusionGPT适用于多种应用场景,具有广泛适用性和灵活性。

