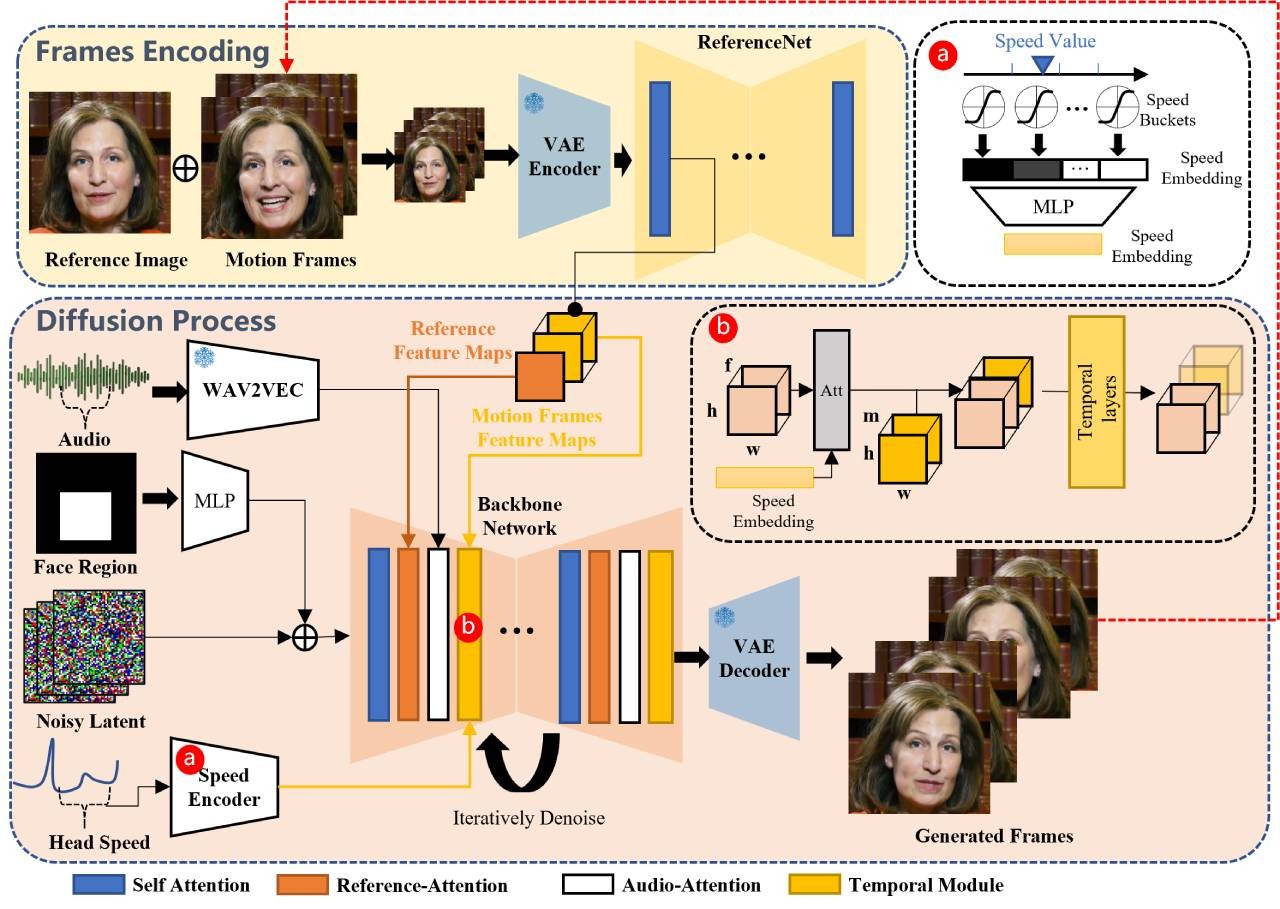
音频驱动




HunyuanCustom
HunyuanCustom是腾讯混元团队开发的多模态视频生成框架,支持图像、音频、视频和文本等多种输入条件,生成高质量定制化视频。采用文本-图像融合与图像ID增强技术,提升身份一致性和视频真实性。适用于虚拟人广告、虚拟试穿、视频编辑等场景,具备音频驱动和视频驱动两种生成方式,展现强大可控性与灵活性。




ChatAnyone
ChatAnyone是阿里巴巴通义实验室开发的实时风格化肖像视频生成工具,基于音频输入生成高保真、自然流畅的上半身动态视频。采用分层运动扩散模型和混合控制融合生成模型,支持实时交互与风格化控制,适用于虚拟主播、视频会议、内容创作等多种场景,具备高度可扩展性和实用性。