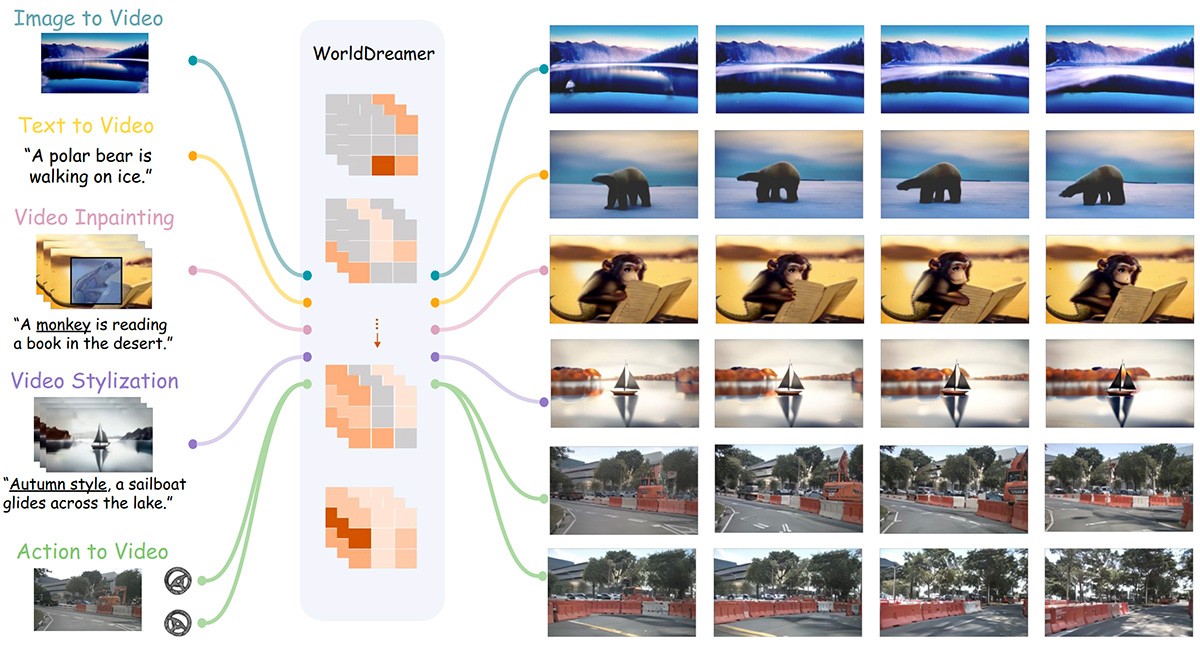
ToonCrafter ToonCrafter是一个展示平台,它利用先进的生成对抗网络(GAN)技术,将用户的原始动漫帧转化为一系列风格一致、过渡自然的画面。 Ai视频生成 1970年01月01日 0 点赞 0 评论 499 浏览
ClipZap AI ClipZap AI 是一款基于人工智能的视频创作与编辑工具,提供视频剪辑、多语言翻译、AI 换脸、视频生成与增强等多种功能,帮助用户高效制作高质量视频内容,适用于社交媒体推广、产品营销、教育及多语言内容制作等多个场景。 AI项目与工具 2025年06月11日 61 点赞 0 评论 499 浏览
Hula Hula 是一款 AI 视频生成工具,支持将静态照片或视频转换为动态内容,提供多种风格转换功能,如复古、动漫、童话等。用户可生成未来宝宝形象、制作聊天贴纸,并体验“时间旅行”功能,展现不同时代的自我形象。适用于社交媒体内容创作、创意视频制作和个人形象设计等多种场景。 AI项目与工具 2025年06月11日 76 点赞 0 评论 500 浏览
FlashVideo FlashVideo是由字节跳动团队研发的高分辨率视频生成框架,采用两阶段方法优化计算效率。第一阶段在低分辨率下生成高质量内容,第二阶段通过流匹配技术提升至1080p,仅需4次函数评估。其特点包括高效计算、细节增强、快速预览及多场景应用,适用于广告、影视、教育等领域。 AI项目与工具 2025年06月12日 26 点赞 0 评论 500 浏览
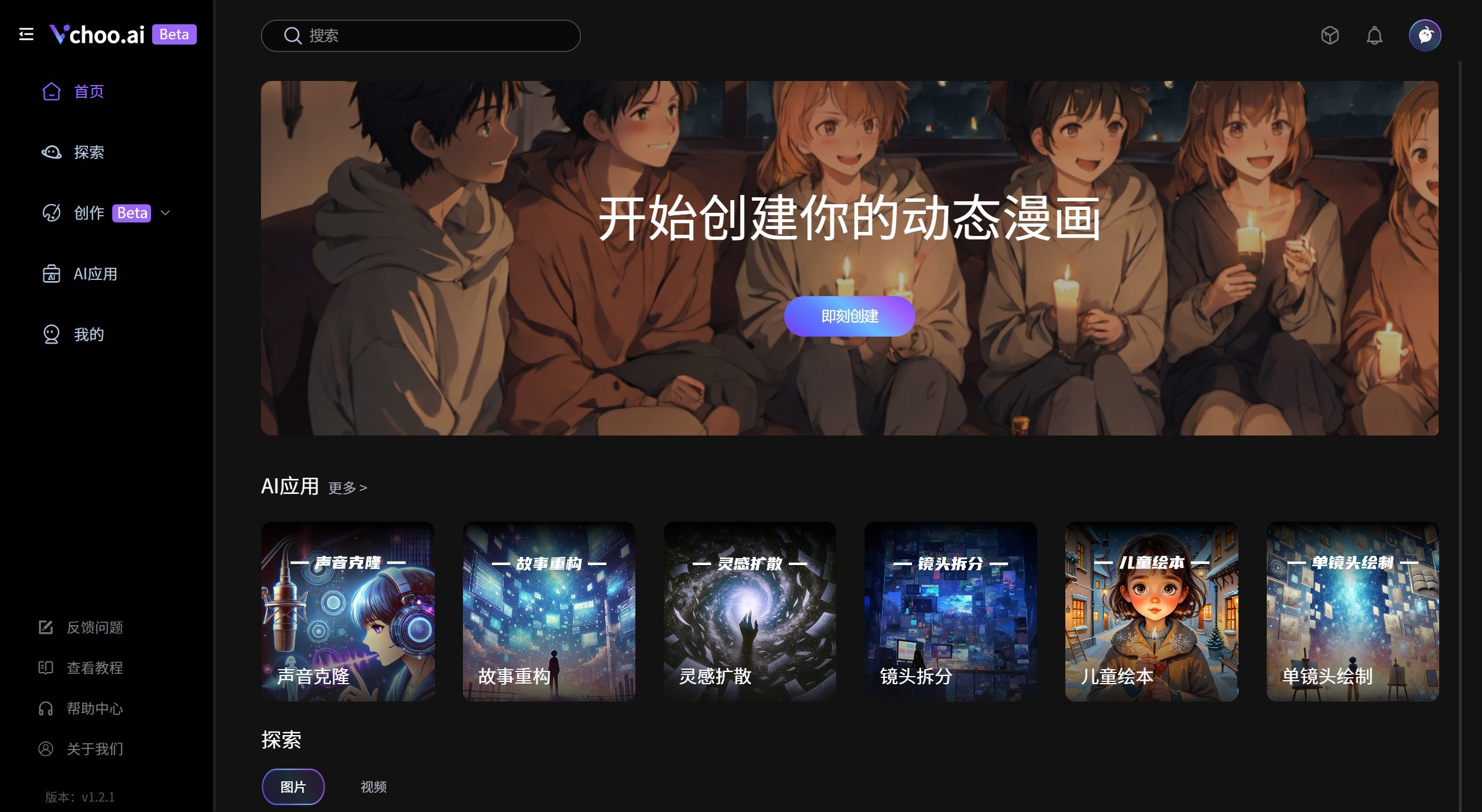
Vchoo.ai 一个故事转视频的AI故事短片创作AIGC工具,Vchoo.ai简化从故事创作到视频生成的过程,丰富的故事题材、多元的画面风格、稳定可控的角色和场景,轻松地将故事视觉化。 Ai视频生成 2025年06月05日 97 点赞 0 评论 502 浏览
绘蛙·多图成片 绘蛙·多图成片是一款基于AI技术的视频生成工具,通过上传2-4张连贯图片并配合文字描述,快速生成高质量视频。支持多种视频尺寸,具备智能文案生成能力,适用于创意视频、广告、电商展示等多种场景,显著降低视频制作门槛和成本。 AI项目与工具 2025年06月12日 18 点赞 0 评论 504 浏览
Stable Video 3D (SV3D) Stable Video 3D(SV3D)是一款由Stability AI公司开发的多视角合成和3D生成模型,能够从单张图片生成一致的多视角图像,并进一步优化生成高质量的3D网格模型。该模型在视频扩散模型基础上进行改进,提供更好的质量和多视角体验。主要功能包括多视角视频生成、3D网格创建、轨道视频生成、相机路径控制以及新视角合成。SV3D在新视角合成方面取得显著进展,能够生成逼真且一致的视图,提升 AI项目与工具 2024年01月01日 39 点赞 0 评论 506 浏览
Wan2.1 Wan2.1是阿里云推出的开源AI视频生成模型,支持文生视频与图生视频,具备复杂运动生成和物理模拟能力。采用因果3D VAE与视频Diffusion Transformer架构,性能卓越,尤其在Vbench评测中表现领先。提供专业版与极速版,适应不同场景需求,已开源并支持多种框架,便于开发与研究。 AI项目与工具 2025年06月12日 47 点赞 0 评论 508 浏览