Show Show-o 是一款基于统一 Transformer 架构的多模态 AI 工具,集成了自回归和离散扩散建模技术,可高效处理视觉问答、文本到图像生成、图像修复与扩展以及混合模态生成等多种任务。其创新性技术显著提高了生成效率,减少了采样步骤,适用于社交媒体内容创作、虚拟助手、教育与培训、广告营销、游戏开发及影视制作等多个领域。 AI项目与工具 2025年06月12日 86 点赞 0 评论 517 浏览
HiDream AI HiDream AI的目标是帮助用户零基础掌握AIGC的一站式能力,唤醒创造力、赋予作品生命感和价值感,同时解放生产力,提升全流程工作效率。 创作工具 1970年01月01日 0 点赞 0 评论 516 浏览
S2V S2V-01是MiniMax研发的视频生成模型,基于单图主体参考架构,可快速生成高质量视频。它能精准还原图像中的面部特征,保持角色一致性,并通过文本提示词灵活控制视频内容。支持720p、25fps高清输出,具备电影感镜头效果,适用于短视频、广告、游戏、教育等多种场景,具有高效、稳定和高自由度的特点。 AI项目与工具 2025年06月12日 100 点赞 0 评论 515 浏览
Second Me Second Me 是由心识宇宙开发的开源 AI 身份模型,支持创建个性化且私有的 AI 代理,代表用户的真实自我。它提供 Chat Mode 和 Bridge Mode 两种交互模式,适用于不同场景下的沟通与信息反馈。支持本地运行,保障数据隐私。Second Me 采用分层记忆模型、个性化对齐架构等技术,具备多角色适应、智能记忆管理和链式推理能力,广泛应用于个人助理、职业发展、社交互动、学习辅导 AI项目与工具 2025年06月12日 67 点赞 0 评论 515 浏览
Genesis Genesis是一款基于开源架构的生成式物理引擎,具备高度准确的物理模拟能力,涵盖物体运动、流体力学、碰撞检测等领域。其显著特点包括超高速模拟、轻量级机器人仿真平台、照片级真实感渲染以及支持自然语言输入的数据生成功能。Genesis旨在推动通用机器人、具身AI及物理AI的发展,适用于机器人训练、游戏开发、影视特效制作等多个领域。 AI项目与工具 2025年06月12日 66 点赞 0 评论 514 浏览
GPTBiz GPTBiz代表着在人工智能领域的一次重要创新,它不仅仅是一个产品,而是一个为中国市场量身定制的大语言模型应用平台。随着人工智能技术的迅猛发展,对于能够快速、 AI写作对话 2025年06月05日 92 点赞 0 评论 513 浏览
MedRAX MedRAX是一款面向胸部X光检查的医学推理AI系统,结合多模态大模型与专业工具,实现复杂医疗问题的动态处理。支持多步骤推理、精准诊断与多种影像分析功能,适用于临床支持、教育培训及远程医疗等场景。系统具备良好的扩展性与部署灵活性,已在多项基准测试中表现优异。 AI项目与工具 2025年06月12日 68 点赞 0 评论 513 浏览
Magma Magma是微软研究院开发的多模态AI基础模型,具备理解与执行多模态任务的能力,覆盖数字与物理环境。它融合语言、空间与时间智能,支持从UI导航到机器人操作的复杂任务。基于大规模视觉-语言和动作数据预训练,Magma在零样本和微调设置下表现优异,适用于网页操作、机器人控制、视频理解及智能助手等多个领域。 AI项目与工具 2025年06月12日 100 点赞 0 评论 513 浏览
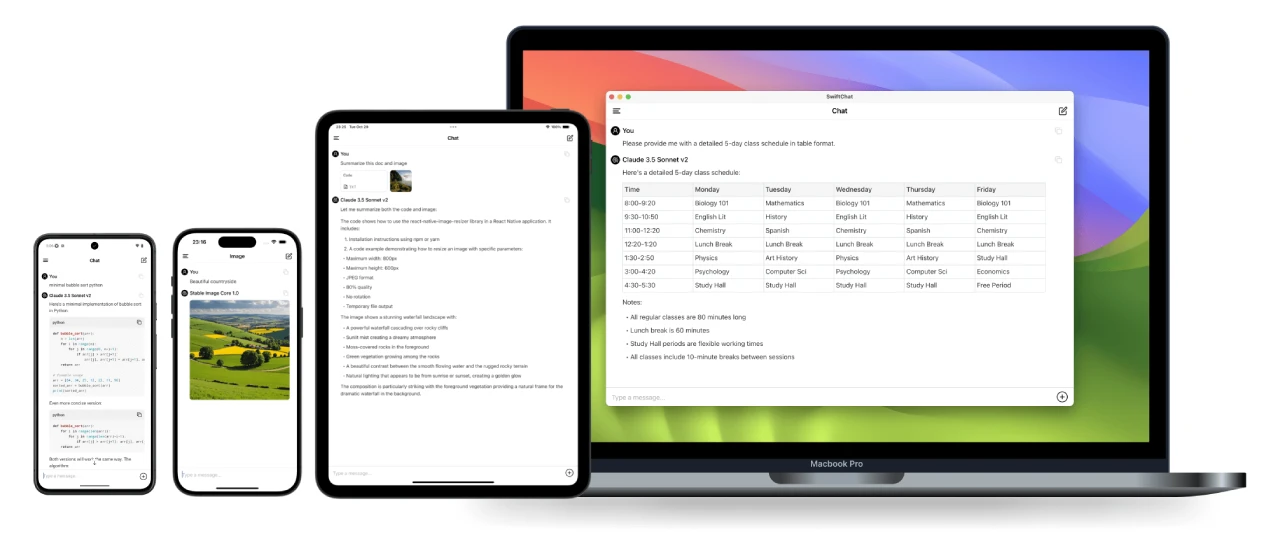
SwiftChat 一款基于React Native开发的快速、安全、跨平台聊天应用,支持实时流式聊天功能和Markdown语法,还可以生成AI图像,兼容DeepSeek、Amazon Bedrock、Ollama和OpenAI等模型。 Ai开源项目 2025年06月05日 44 点赞 0 评论 511 浏览
Liquid Liquid是由华中科技大学、字节跳动和香港大学联合开发的多模态生成框架,通过VQGAN将图像编码为离散视觉token并与文本共享词汇空间,使大型语言模型无需修改结构即可处理视觉任务。该框架降低训练成本,提升视觉生成与理解性能,并在多模态任务中表现出色。支持图像生成、视觉问答、多模态融合等应用,适用于创意设计、内容创作及智能交互等领域。 AI项目与工具 2025年06月12日 82 点赞 0 评论 511 浏览