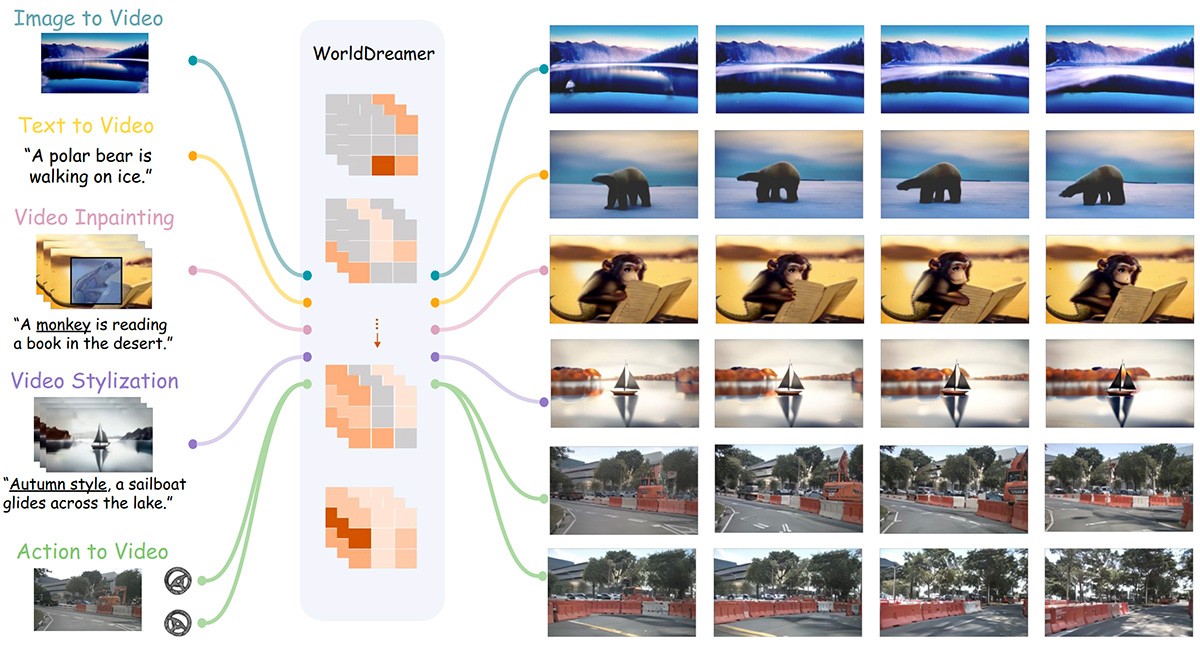
CustomVideoX CustomVideoX是一种基于视频扩散变换器的个性化视频生成框架,能够根据参考图像和文本描述生成高质量视频。其核心技术包括3D参考注意力机制、时间感知注意力偏差(TAB)和实体区域感知增强(ERAE),有效提升视频的时间连贯性和语义一致性。支持多种应用场景,如艺术设计、广告营销、影视制作等,具备高效、精准和可扩展的特点。 AI项目与工具 2025年06月12日 98 点赞 0 评论 660 浏览
Hallo3 Hallo3是由复旦大学与百度联合开发的基于扩散变换器网络的肖像动画生成技术,能够生成多视角、动态且逼真的视频内容。其核心功能包括身份一致性保持、语音驱动动画、动态对象渲染和沉浸式背景生成。技术上采用预训练变换器模型,结合身份参考网络与音频条件机制,实现高质量视频生成。适用于游戏开发、影视制作、社交媒体及VR/AR等多个领域。 AI项目与工具 2025年06月12日 80 点赞 0 评论 658 浏览
AutomateClips AutomateClips是一款人工智能视频生成器,专为社交媒体平台如TikTok、Instagram和YouTube设计,以自动化创建吸引人的视频内容。 Ai视频生成 2026年07月27日 0 点赞 0 评论 658 浏览
Loopy AI 字节跳动和浙江大学联合开发的音频驱动的AI视频生成模型,能够将静态图像转化为动态视频,实现音频与面部表情、头部动作的完美同步。 Ai视频生成 2025年06月05日 93 点赞 0 评论 656 浏览
商汤如影 商汤如影是一款由商汤科技开发的AI数字人视频生成平台,通过先进大模型技术创建高度逼真的数字人形象,应用于教育、金融、营销等领域。平台具备数字人创建、声音克隆、视频生成、自动化数据标注、图片生成、实时互动等功能,并支持多语言及多种服务形式,以满足个性化和专业化的服务需求。 AI项目与工具 2025年06月12日 93 点赞 0 评论 656 浏览
Gen Gen-3 Alpha是一款由Runway公司研发的AI视频生成模型,能够生成长达10秒的高清视频片段,支持文本到视频、图像到视频的转换,并具备精细的时间控制及多种高级控制模式。其特点在于生成逼真的人物角色、复杂的动作和表情,提供运动画笔、高级相机控制和导演模式等高级控制工具,确保内容的安全性和合规性。 AI项目与工具 2025年06月12日 93 点赞 0 评论 656 浏览
Deepfakes Creator Deepfakes Creator,可以通过文本输入生成逼真的会说话的真人视频。用户只需要上传想要化身模仿的人的照片,并写一个剧本,工具就能创建出逼真的人物化身视频,模拟人物说话。 Ai开源项目 2025年06月05日 62 点赞 0 评论 656 浏览
Q.AI视频生成工具 支持一分钟生成专业级短视频,多种生成方式,AI视频脚本,在线云编辑,画面自由替换,热门配音媲美真人音色,更多强大功能尽在Q.AI Ai视频生成 2026年07月27日 0 点赞 0 评论 655 浏览