Animate Anyone 2 Animate Anyone 2 是由阿里巴巴通义实验室开发的高保真角色动画生成技术,能基于输入图像和运动信号生成高质量、自然流畅的角色动画。通过环境感知、形状无关掩码策略、物体交互增强等技术,实现角色与环境的深度融合,提升动画的真实感与稳定性。支持复杂动作处理、多角色互动及跨身份动画生成,适用于影视、广告、VR/AR、游戏及教育等多个领域。 AI项目与工具 2025年06月12日 50 点赞 0 评论 868 浏览
FacePoke FacePoke是一款基于AI的开源实时面部编辑工具,支持通过简单拖拽操作调整人物头部姿态和面部表情,使静态图像更加生动。其采用深度学习技术,具备高分辨率输出和精确控制能力,适用于数字艺术、内容创作及影视制作等领域。工具基于LivePortrait技术开发,支持本地和Docker部署,便于用户灵活使用。 AI项目与工具 2025年06月12日 86 点赞 0 评论 868 浏览
OmniSync OmniSync是由中国人民大学、快手科技和清华大学联合开发的通用对口型框架,基于扩散变换器实现视频中人物口型与语音的精准同步。它采用无掩码训练范式,直接编辑视频帧,支持无限时长推理,保持自然面部动态和身份一致性。通过渐进噪声初始化和动态时空分类器自由引导(DS-CFG)机制,提升音频条件下的口型同步效果。OmniSync适用于影视配音、虚拟现实、AI内容生成等多个场景。 AI项目与工具 2025年06月11日 27 点赞 0 评论 868 浏览
Dubbing AI DubbingAI 语音生成器作为实时变声器,可以将任何语音转换为优质语音和克隆语音。从游戏玩家到直播主播和内容创作者。每个人都可以使用 Dubbing AI 生成跨年龄、语言和口音的逼真配音。 Ai语音工具 2025年06月05日 19 点赞 0 评论 867 浏览
PIXMAKER PIXMAKER是一款基于AI技术的图像生成与编辑平台,主要服务于电商行业。其核心功能涵盖AI生成产品背景、虚拟试穿效果、多姿势模特照片生成、动态产品视频制作以及背景移除等。用户无需具备专业设计技能即可快速生成高质量的产品图片和视频,从而提升商品展示效果并促进销售转化。该工具广泛应用于电商、市场营销、时尚服装等多个领域,助力企业高效完成产品视觉内容创作。 AI项目与工具 2025年06月12日 52 点赞 0 评论 866 浏览
GPT-SoVITS 一个强大的语音合成工具,特别适合需要快速生成特定人声的场景。它通过先进的技术实现了高质量的语音克隆和文本到语音转换,支持多种语言,并提供了易于使用的WebUI工具。 Ai平台模型 2026年06月30日 0 点赞 0 评论 865 浏览
Shining Yourself Shining Yourself是商汤科技推出的高保真饰品虚拟试戴技术,基于扩散模型实现逼真试戴效果。支持多饰品、个性化调整、多场景模拟及动态展示,适用于电商、设计、社交及品牌推广等场景,提升用户体验与决策效率。 AI项目与工具 2025年06月12日 58 点赞 0 评论 865 浏览
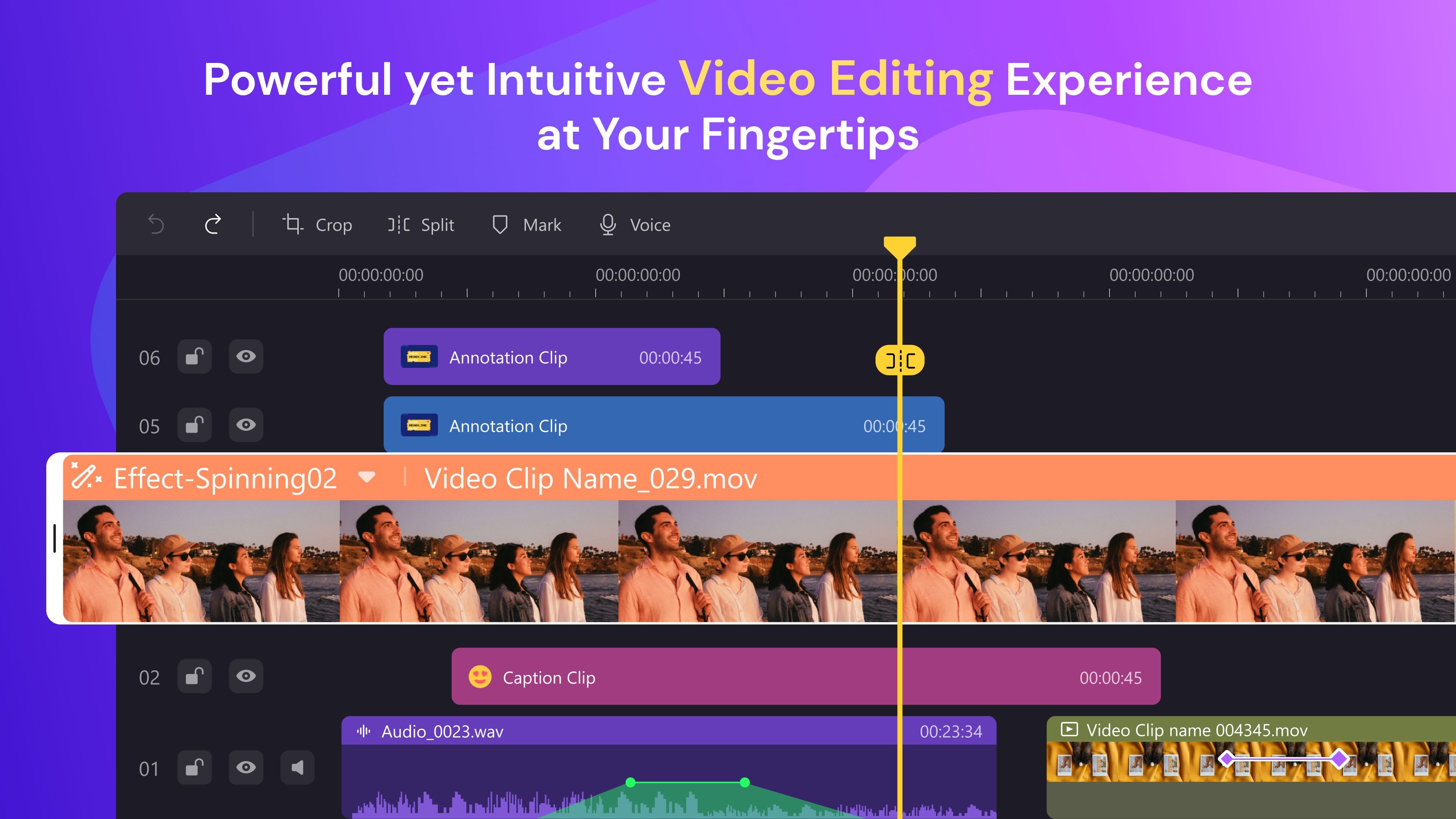
DemoCreator 一款适用于教育工作者、视频会议演示者、企业主和游戏玩家的屏幕录像机和视频编辑器,DemoCreator是制作演示视频和解说视频的一站式解决方案。 视频剪辑 2025年06月05日 60 点赞 0 评论 863 浏览
星火陪练 星火陪练是一款基于AI技术的企业员工培训平台,集智能配置、自然对话、虚拟陪练及多维评分于一体。其主要功能包括快速生成课程内容、场景模拟对话、沉浸式虚拟陪练以及多维度评价反馈,广泛应用于企业培训、新员工入职、技能提升及在线教育等领域,助力员工高效掌握专业知识与实践技能。 AI项目与工具 2025年06月12日 61 点赞 0 评论 863 浏览
Neural4D Neural4D是一款由DreamTech团队开发的AI驱动型3D模型生成平台,利用Direct3D-5B大模型实现从文字或图片到高精度3D模型的自动化生成。其主要功能包括文本生成3D、图片生成3D、CuteMe Q版化身转换以及高精度模型输出。平台支持多种应用场景,如游戏开发、动画制作、虚拟现实设计、产品可视化及3D打印等,推动了3D内容创作领域的快速发展。 AI项目与工具 2025年06月12日 90 点赞 0 评论 862 浏览