DeepClaude DeepClaude 是一款高性能开源 AI 工具,融合 DeepSeek R1 和 Claude 模型,具备推理、创造力和代码生成能力。它提供零延迟响应、端到端加密和本地 API 管理,保障数据安全。支持高度自定义,适用于智能客服、代码生成、推理分析及教育等多场景,满足多样化需求。 AI项目与工具 2025年06月12日 71 点赞 0 评论 1014 浏览
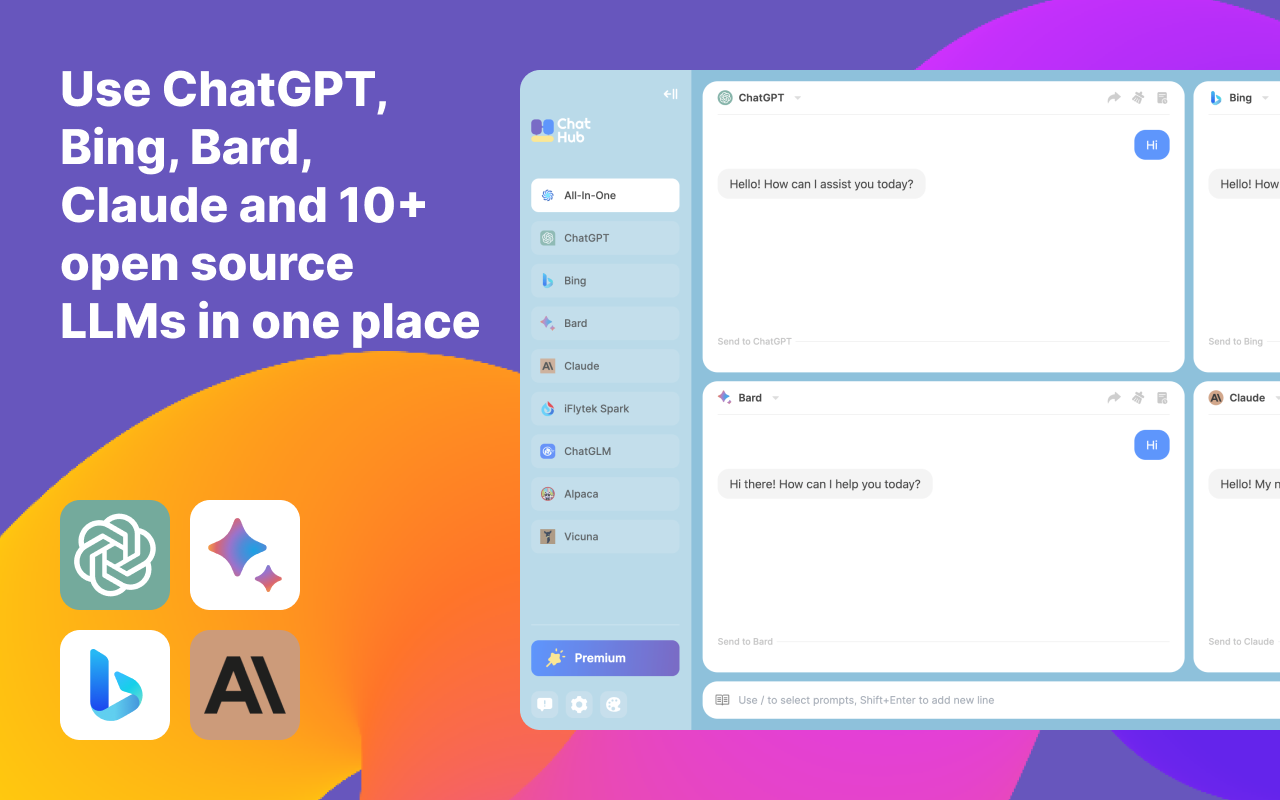
ChatHub 一个创新的浏览器扩展插件和应用,ChatHub设计的目的是为了让用户能够在一个统一的界面中与多个聊天机器人进行交互。 AI写作对话 2025年06月05日 98 点赞 0 评论 1014 浏览
Kokoro Kokoro-TTS是一款由hexgrad开发的轻量级文本转语音工具,基于StyleTTS 2与ISTFTNet架构,支持多种语音风格和自然语调,具备实时处理能力。支持美式与英式英语,提供10种语音包,适用于教育、游戏、客服等多种场景。支持本地部署与API集成,确保数据安全与高效运行。 AI项目与工具 2025年06月12日 33 点赞 0 评论 1009 浏览
Wonderland Wonderland是一项由多伦多大学、Snap和UCLA联合开发的技术,能够基于单张图像生成高质量的3D场景,并支持精确的摄像轨迹控制。它结合了视频扩散模型和大规模3D重建模型,解决了传统3D重建技术中的视角失真问题,实现了高效的三维场景生成。Wonderland在多个基准数据集上的3D场景重建质量均优于现有方法,广泛应用于建筑设计、虚拟现实、影视特效、游戏开发等领域。 AI项目与工具 2025年06月12日 23 点赞 0 评论 1007 浏览
ILLUME ILLUME是一款基于大型语言模型的统一多模态大模型,集成了视觉理解与生成能力,采用“连续图像输入 + 离散图像输出”架构,通过语义视觉分词器和三阶段训练流程,实现了高效的数据利用和多模态任务处理能力。模型能够无缝整合视觉理解与生成功能,广泛应用于视频分析、医疗诊断、自动驾驶及艺术创作等领域。 AI项目与工具 2025年06月12日 54 点赞 0 评论 1004 浏览
Shakker AI 一个专注于AI图像生成和编辑的在线平台,Shakker AI汇集了数千个高质量的Stable Diffusion模型,利用稳定扩散模型为用户提供高质量的图像和视频生成服务。 Ai绘画生成 2025年06月05日 94 点赞 0 评论 1003 浏览
Aibiye Aibiye是一款基于先进语言模型的AI论文辅助工具,支持从选题建议、结构生成到内容填充的全流程写作服务。用户可输入关键词、选择专业及字数,生成符合学术规范的论文初稿,支持中英文文献引用和图表插入,具备降重与改写功能,助力提升论文质量。 AI项目与工具 2025年06月12日 61 点赞 0 评论 1002 浏览
智谱AI开放平台 智谱AI开放平台是一个面向开发者的大模型开发平台,集成了多种先进模型和技术资源。该平台支持统一API接入,涵盖AI视频生成、文生图、多模态视觉、长文本等多种大模型。平台还提供定制化知识解决方案和互动体验,支持云上私有化部署。适用于软件开发者、数据科学家、AI研究者、企业决策者和创业者等人群。 AI项目与工具 2025年06月12日 76 点赞 0 评论 1001 浏览
GenCast GenCast是一款基于扩散模型的AI气象预测工具,可提供长达15天的高精度全球天气预报,尤其擅长预测极端天气事件。它采用0.25°纬度-经度分辨率生成高精度集合预报,并通过并行计算在8分钟内完成预测。GenCast已开源,支持学术界和行业用户进一步研究与应用。 AI项目与工具 2025年06月12日 25 点赞 0 评论 997 浏览