Operator Operator是由OpenAI开发的AI工具,基于Computer-Using Agent(CUA)模型,能够模拟人类操作网页浏览器,完成如预订、购物、表单填写等任务。它结合了GPT-4o的视觉识别能力和强化学习的推理能力,支持多任务处理和个性化设置。具备自我纠错、安全防护及隐私保护机制,在涉及敏感信息时会请求用户接管。适用于自动化购物、数据分析、日程安排等多种场景。 AI项目与工具 2025年06月12日 10 点赞 0 评论 805 浏览
Universal Universal-1是一款由AssemblyAI开发的多语言语音识别和转录模型,经过大量多语种音频数据训练,支持英语、西班牙语、法语和德语等。该模型在各种复杂环境中提供高精度的语音转文字服务,具备快速响应能力和改进的时间戳准确性。Universal-1在准确率、响应时间、时间戳估计和用户偏好等方面表现优异,适用于对话智能平台、AI记事本、创作者工具和远程医疗平台等多个应用场景。 AI项目与工具 2024年01月01日 88 点赞 0 评论 805 浏览
提示精灵小富贵 一个旨在简化并增强为AI模型创建和优化提示词(Prompts)过程的开源项目,会帮你写Prompt提示词的GPTs应用。 GPTs应用 2025年06月05日 27 点赞 0 评论 804 浏览
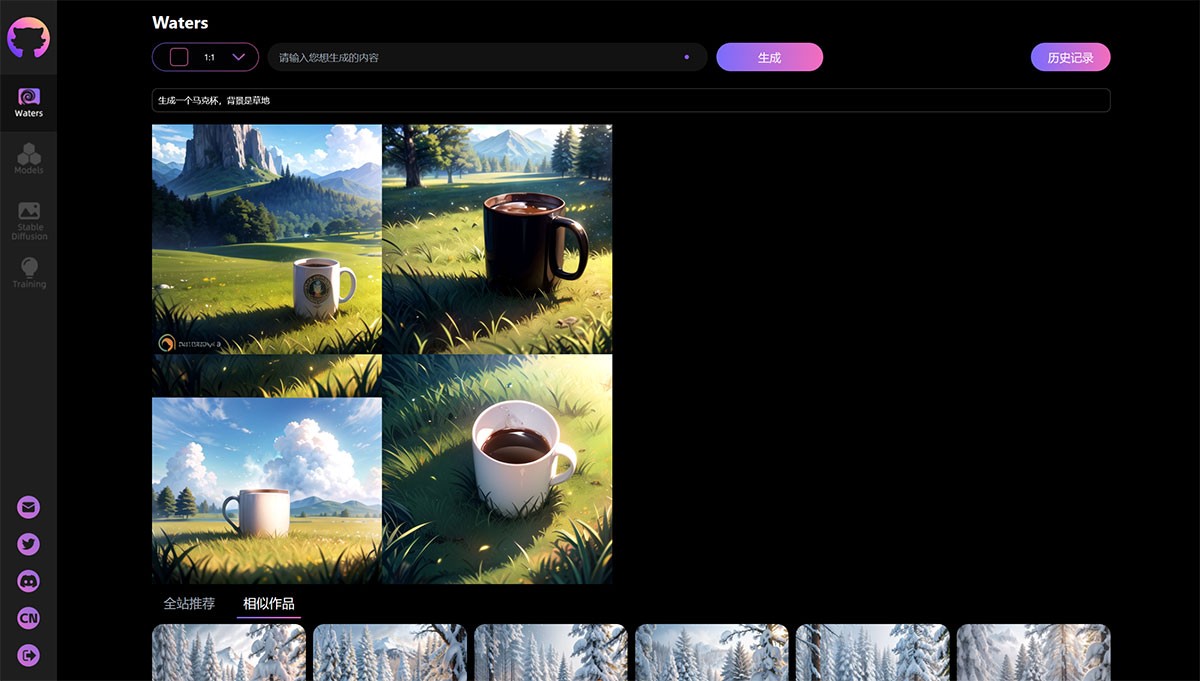
Waters AI WATERS作为Minister AI旗下的头部产品,仅需输入简单的关键词,即可在几秒钟内创造出令人惊叹的 AI 艺术作品。 Ai绘画生成 2025年06月05日 56 点赞 0 评论 803 浏览
光语大模型 无限光年公司发布的一款结合大语言模型与符号推理的AI大模型,光语大模型目的是解决大模型在行业应用中的幻觉问题,提高了模型的可信度和专业性。 Ai平台模型 2025年06月05日 89 点赞 0 评论 803 浏览
超算互联网 超算互联网是国家级算力服务平台,整合全国超算与智算资源,提供算力调度、AI模型服务、SaaS平台、数据支持及技术支持。支持DeepSeek、Qwen等AI模型的在线推理、API部署和私有化开发,适用于科研、工业、企业数字化、人工智能及教育等多个领域,推动算力普惠与科技创新。 AI项目与工具 2025年06月12日 25 点赞 0 评论 803 浏览
Edify 3D Edify 3D 是 NVIDIA 推出的一款高效3D资产生成工具,能够从文本或图像输入快速生成高质量的3D模型。其主要功能包括支持文本到3D、图像到3D的转换,生成高分辨率纹理与 PBR 材质,并具备快速生成、UV贴图和材质图生成等特性。该工具通过多视图扩散模型、Transformer 模型及跨视图注意力机制实现精准建模,适用于游戏开发、虚拟现实、影视制作及建筑可视化等多个领域。 AI项目与工具 2025年06月12日 40 点赞 0 评论 803 浏览
Voiceflow Voiceflow 是一款面向非技术用户的无代码对话式 AI 平台,具备直观的拖放界面和强大的自然语言处理能力。它支持复杂对话流程的设计、多渠道部署及团队协作,适用于客户服务自动化、虚拟助手开发、语音交互系统构建等多个领域,为企业和个人提供灵活且高效的解决方案。 AI项目与工具 2025年06月12日 21 点赞 0 评论 803 浏览
TPO TPO(Test-Time Preference Optimization)是一种在推理阶段优化语言模型输出的框架,通过将奖励模型反馈转化为文本形式,实现对模型输出的动态调整。该方法无需更新模型参数,即可提升模型在多个基准测试中的性能,尤其在指令遵循、偏好对齐、安全性和数学推理等方面效果显著。TPO具备高效、轻量、可扩展的特点,适用于多种实际应用场景。 AI项目与工具 2025年06月12日 83 点赞 0 评论 802 浏览
Chat Nio Chat Nio 是一款集成了丰富 AI 功能的一站式服务管理平台,支持文本、图像、音频和视频处理,兼容 OpenAI、Anthropic Claude 等多种 AI 模型。其主要功能包括文件解析、对话记忆、云端同步、多端适配等,同时提供开源版本以满足开发者的个性化需求。适用于个人用户、开发者及企业,支持多种应用场景,如客户服务、内容创作、数据分析和教育领域。 AI项目与工具 2025年06月12日 42 点赞 0 评论 802 浏览