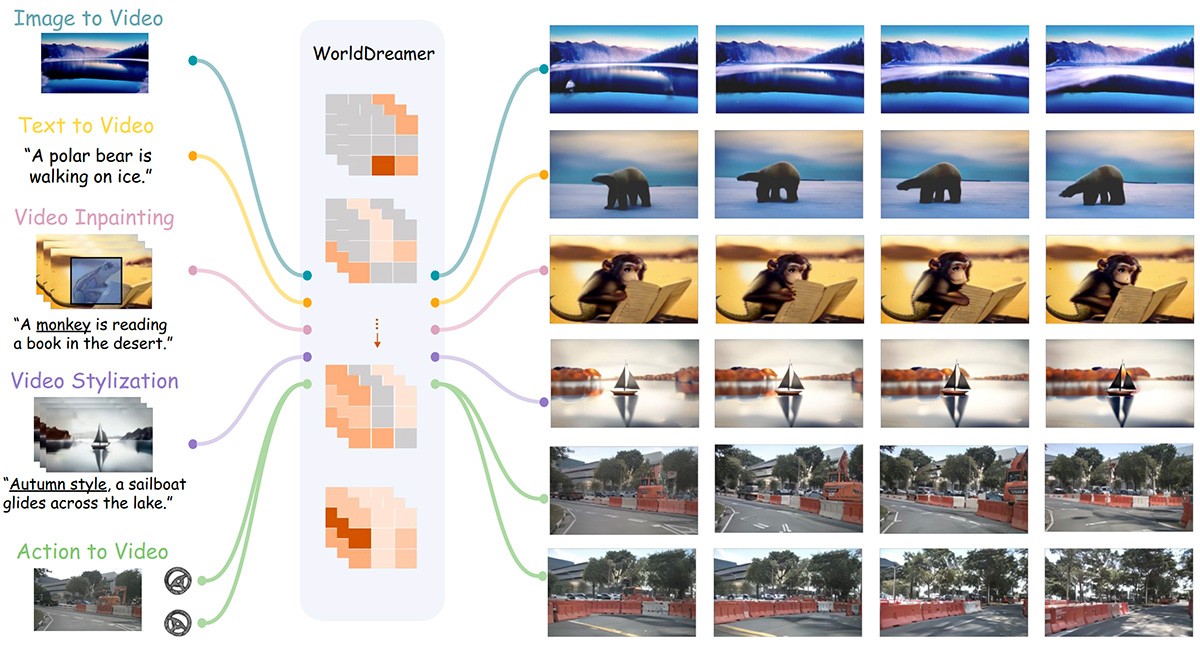
扩散模型

VideoDrafter
一个高质量视频生成的开放式扩散模型,相比之前的生成视频模型,VideoDrafter最大的特点是能在主体不变的基础上,一次性生成多个场景的视频。



PixelDance
字节跳动研发的一种视频生成模型,PixelDance通过结合文本指导和首尾帧图片指导的方式,能够生成具有复杂场景与动作的视频。

Sonauto AI
一款AI音乐生成器,允许用户通过将文本提示、歌词或旋律转换为完整的不同风格的歌曲。它采用了潜在扩散模型,这使得它与其他人工智能音乐生成模型相比更加可控。