视频理解



StreamBridge
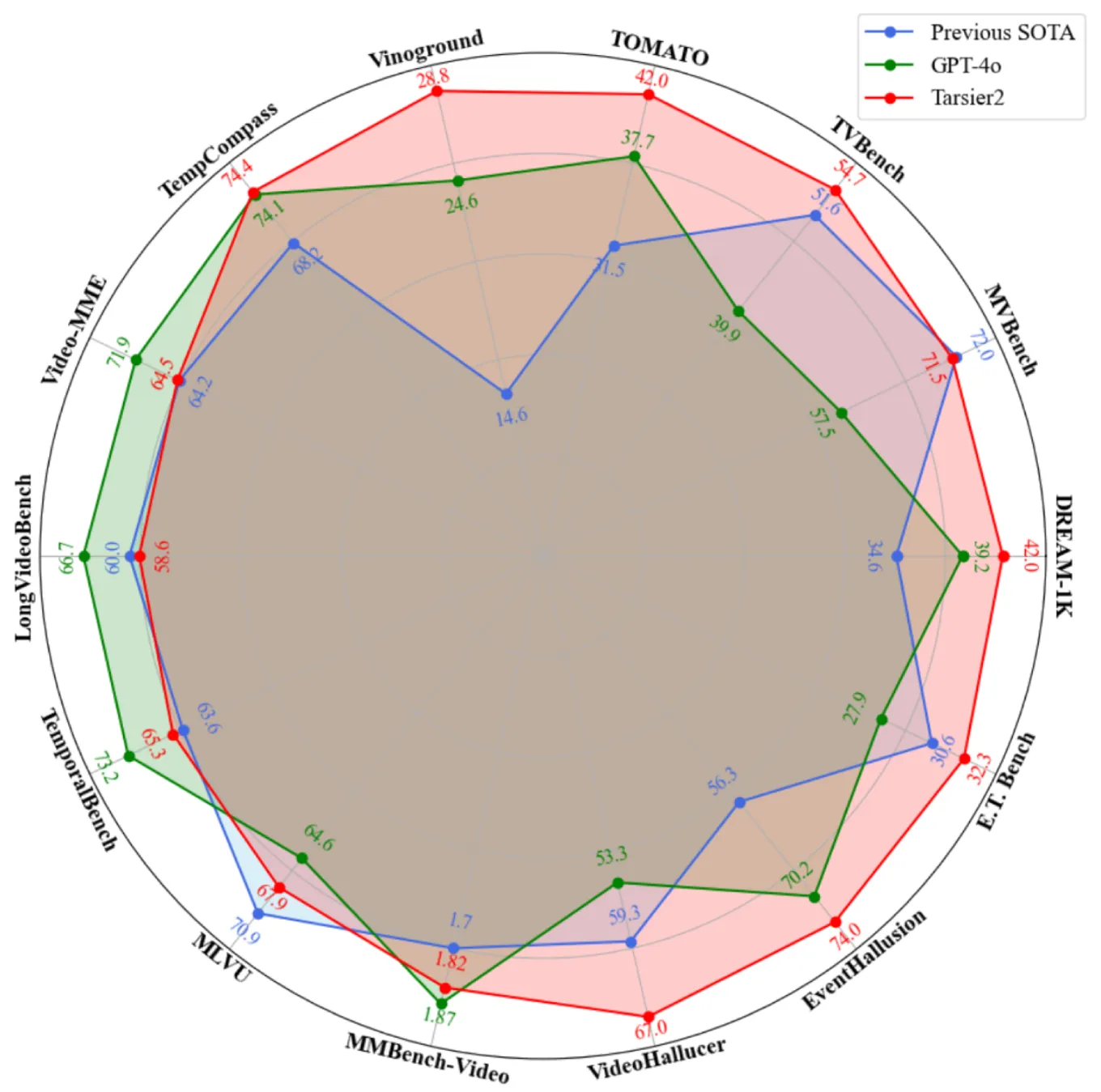
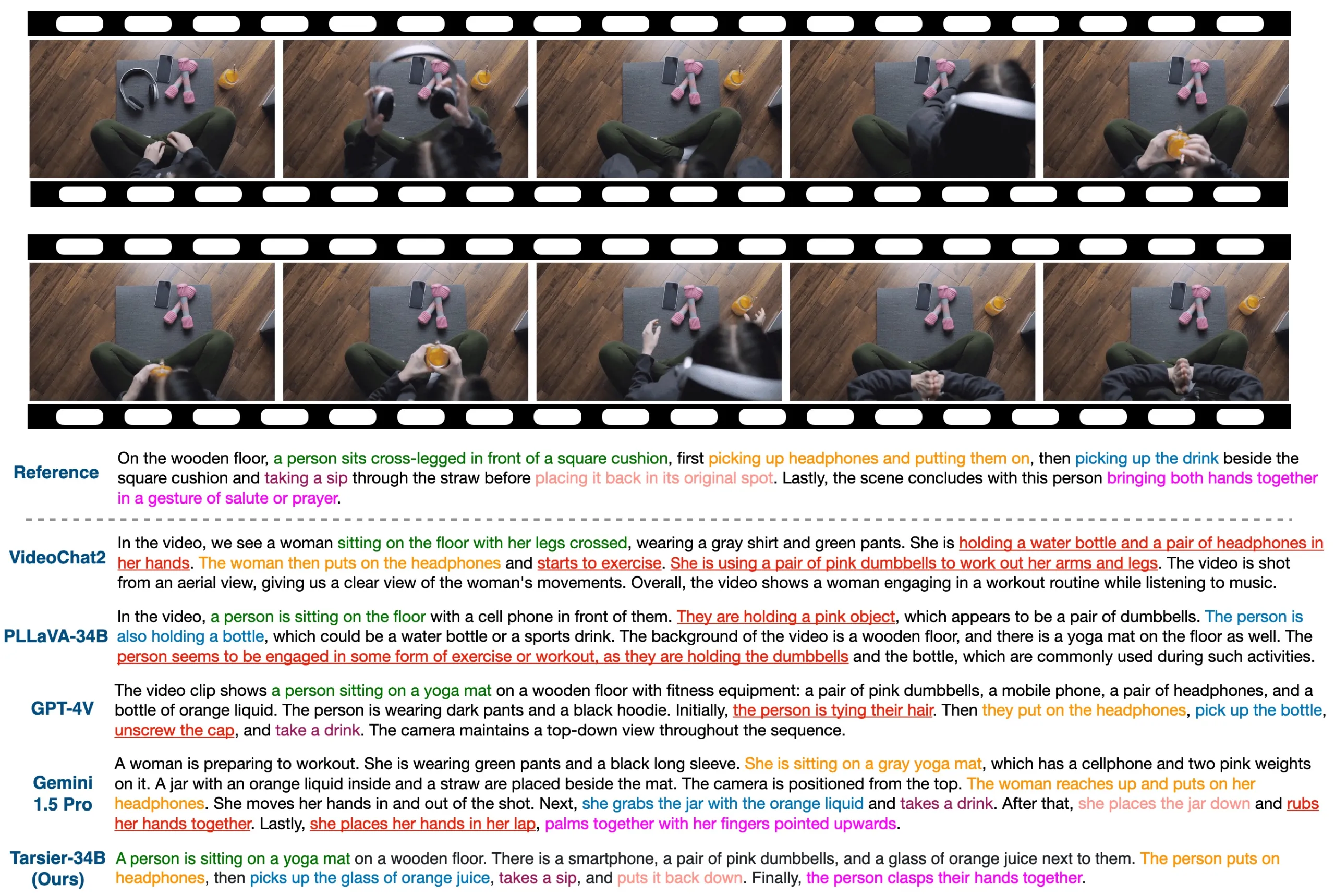
StreamBridge是一款由苹果与复旦大学联合开发的端侧视频大语言模型框架,支持实时视频流的理解与交互。通过内存缓冲区和轮次衰减压缩策略,实现长上下文处理与主动响应。项目配套发布Stream-IT数据集,包含60万样本,适用于多种视频理解任务,展现出在视频交互、自动驾驶、智能监控等领域的应用前景。




InternVideo2.5
InternVideo2.5是一款由上海人工智能实验室联合多机构开发的视频多模态大模型,具备超长视频处理能力和细粒度时空感知。它支持目标跟踪、分割、视频问答等专业视觉任务,适用于视频检索、编辑、监控及自动驾驶等多个领域。模型通过多阶段训练和高效分布式系统实现高性能与低成本。

VideoLLaMA3
VideoLLaMA3 是阿里巴巴开发的多模态基础模型,支持视频与图像的深度理解和分析。基于 Qwen 2.5 架构,结合先进视觉编码器与语言生成能力,具备高效时空建模与多语言处理能力。适用于视频内容分析、视觉问答、字幕生成等场景,提供多种参数版本,支持灵活部署。


VideoWorld
VideoWorld是由北京交通大学、中国科学技术大学与字节跳动合作开发的深度生成模型,能够通过未标注视频数据学习复杂知识,包括规则、推理和规划能力。其核心技术包括自回归视频生成、潜在动态模型(LDM)和逆动态模型(IDM),支持长期推理和跨环境泛化。该模型在围棋和机器人控制任务中表现优异,且具备向自动驾驶、智能监控等场景扩展的潜力。
