生成模型


Stable Diffusion 3
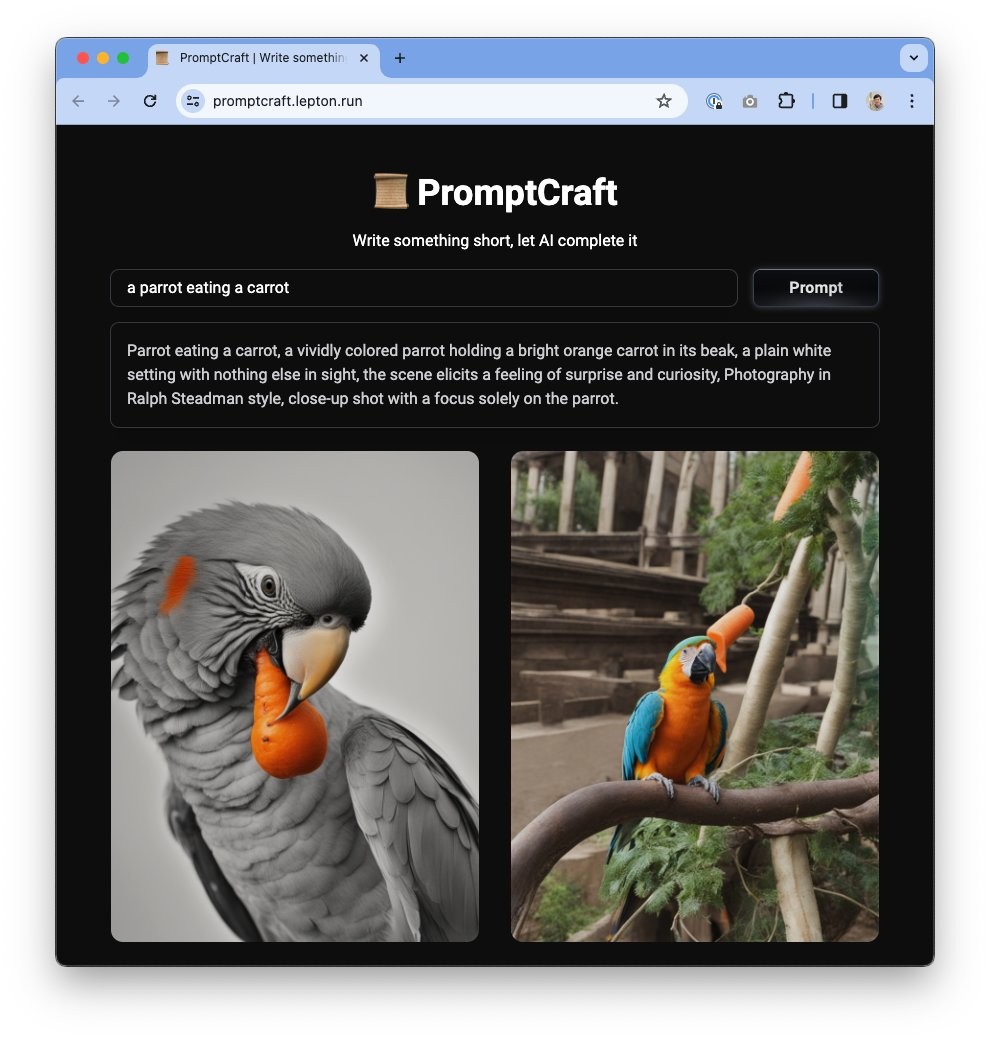
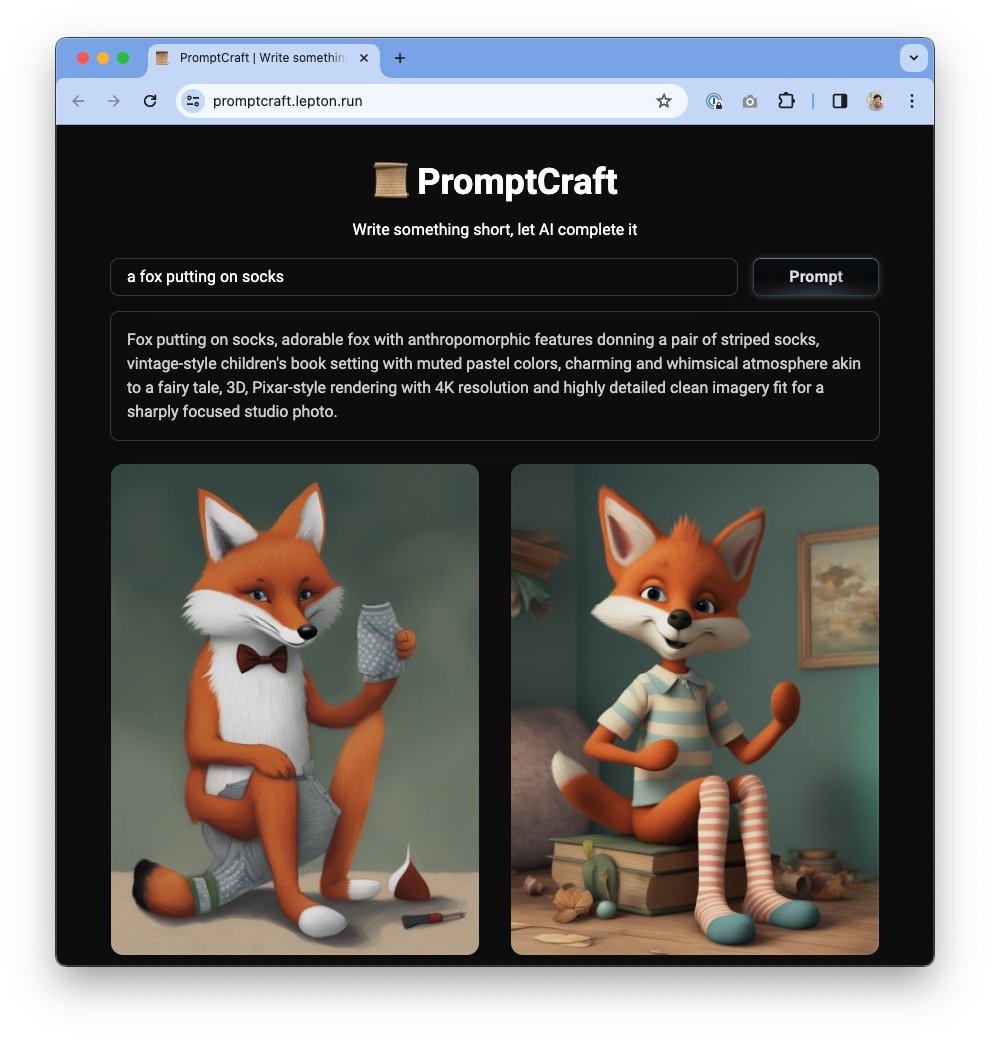
Stable Diffusion 3 是一款由 Stability AI 开发的先进文本到图像生成模型,通过改进的文本渲染能力、多主题提示支持、可扩展的参数量、图像质量提升及先进的架构技术,实现了高质量和多样性的图像生成。该模型在图像生成和文本理解方面取得了显著进展,并通过 Diffusion Transformer 架构和 Flow Matching 技术提升了模型效率和图像质量。





PartCrafter
PartCrafter是一款先进的3D生成模型,能够从单张RGB图像中生成多个语义明确且几何形态各异的3D网格。通过组合潜在空间表示每个3D部件,并利用层次化注意力机制确保全局一致性。该模型基于预训练的3D网格扩散变换器(DiT),支持多部件联合生成、端到端生成和部件级编辑,适用于游戏开发、建筑设计、影视制作等多个领域。


千影QianYing
巨人网络发布的有声游戏生成大模型,主要包括游戏视频生成大模型YingGame和视频配音大模型YingSound。
