模型


Reflection AI
Reflection AI是一个零代码AI Agent开发平台,用户可以创建个性化的AI聊天机器人,模仿真人的沟通风格。该平台基于生成式AI技术,尤其是大型语言模型(LLMs),允许用户通过个人数据训练AI,使其能够以独特方式进行交流。主要功能包括个性化AI Agent创建、快速部署、学习和适应、自定义和微调以及多渠道集成。应用场景广泛,涵盖客户服务、个人助理、社交媒体管理、教育和医疗咨询等领域。


Shining Yourself
Shining Yourself是商汤科技推出的高保真饰品虚拟试戴技术,基于扩散模型实现逼真试戴效果。支持多饰品、个性化调整、多场景模拟及动态展示,适用于电商、设计、社交及品牌推广等场景,提升用户体验与决策效率。


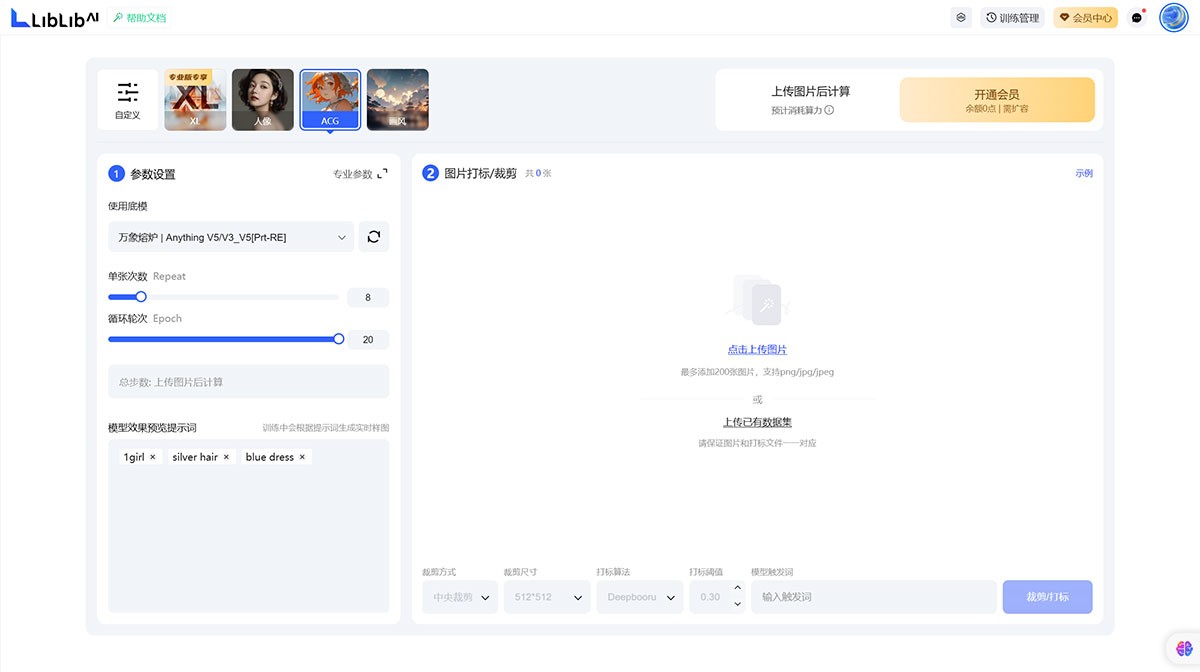

Genie Studio
Genie Studio 是一款面向具身智能的全链路开发平台,涵盖数据采集、模型训练、仿真评测和部署。支持多模态数据采集、高保真仿真环境、自动化评测及一键真机部署,适用于机器人研发、工业自动化、物流仓储和服务机器人等多种场景,提升开发效率与应用落地速度。



