AgentSociety AgentSociety是由清华大学开发的基于大语言模型的社会模拟平台,通过构建具有“类人心智”的智能体,模拟复杂的社会行为与现象。平台支持城市环境建模、大规模社会模拟和科研工具集成,适用于社会舆论传播、政策评估、社会极化分析及灾害响应研究。其技术特点包括异步模拟架构、分布式计算和MQTT通信,具备高度可扩展性和实时交互能力。 AI项目与工具 2025年06月12日 21 点赞 0 评论 818 浏览
o3 o3-pro 是 OpenAI 开发的高级推理模型,继承并优化了 o3 的功能,在复杂问题解决和精确答案提供上表现出色。它集成了 ChatGPT 的多种工具,如网页搜索、文件分析、图像推理和编程等,适合科学研究、编程、教育和写作等领域。尽管响应速度稍慢,但在表达清晰度、逻辑准确性和答案完整性方面表现优异,并在数学、科学和编程等领域的性能上超越了前代模型。 AI项目与工具 2025年06月12日 44 点赞 0 评论 817 浏览
WebDesignAgent WebDesignAgent是一款基于AI技术的自动化网页设计工具,支持文本到网站、图像到网站等多种输入方式,可生成功能齐全、设计精美的网页。它支持多页面设计、用户自定义及迭代优化,适用于个人博客、企业官网、电商页面等多种场景。通过集成自然语言处理、计算机视觉以及大型语言模型,WebDesignAgent能够智能化地完成从内容理解到网页生成的全过程。 AI项目与工具 2025年06月12日 85 点赞 0 评论 817 浏览
RDT RDT是清华大学AI研究院推出的一款双臂机器人操作任务扩散基础模型,拥有十亿参数量,可自主完成复杂任务,如调酒和遛狗。该模型基于模仿学习,具备强大的泛化能力和操作精度,支持多种模态输入和少样本学习。RDT已在餐饮、家庭、医疗、工业及救援等领域展现广泛应用前景,推动机器人技术发展。 AI项目与工具 2025年06月12日 83 点赞 0 评论 817 浏览
FaceSwap FaceSwap是一款开源AI换脸软件,利用深度学习技术实现人脸检测、提取及替换。它支持跨平台操作,包括Windows、macOS和Linux,并可借助GPU加速提升处理效率。FaceSwap还允许用户自定义模型训练以优化换脸效果,广泛应用于影视制作、教育、游戏开发以及虚拟现实等领域。 AI项目与工具 2025年06月12日 45 点赞 0 评论 816 浏览
sCM sCM是一种由OpenAI开发的基于扩散模型的连续时间一致性模型,通过简化理论框架与优化采样流程,实现了图像生成速度的大幅提升。该模型仅需两步采样即可生成高质量图像,且速度比传统扩散模型快50倍。得益于连续时间框架和多项技术改进,sCM不仅提高了训练稳定性,还提升了生成质量。其应用场景广泛,包括视频生成、3D建模、音频处理及跨媒介内容创作,适用于艺术设计、游戏开发、影视制作等多个行业。 AI项目与工具 2025年06月12日 50 点赞 0 评论 816 浏览
MinMo MinMo是阿里巴巴通义实验室推出的多模态语音交互大模型,具备高精度语音识别与生成能力。支持情感表达、方言转换、音色模仿及全双工交互,适用于智能客服、教育、医疗等多个领域,提升人机对话的自然度与效率。 AI项目与工具 2025年06月12日 59 点赞 0 评论 816 浏览
MetaStone MetaStone-L1-7B 是一款轻量级推理模型,具备强大的数学和代码推理能力,性能达到行业领先水平。基于 DeepSeek-R1-Distill-Qwen-7B 架构,采用 GRPO 训练方式,支持多种计算架构并具备高效的云原生部署能力。适用于数学解题、编程辅助、智能客服、内容创作等多个场景,具有广泛的应用价值。 AI项目与工具 2025年06月12日 43 点赞 0 评论 815 浏览
OminiControl OminiControl是一款高效且参数节约的图像生成框架,专为扩散变换器模型设计,支持主题驱动和空间控制。通过增加少量参数,它能够生成高质量图像并保持主题一致性,适用于多种应用场景,包括艺术创作、游戏开发和广告设计等。其强大的多模态注意力机制和灵活的架构使其成为图像生成领域的创新工具。 AI项目与工具 2025年06月12日 94 点赞 0 评论 815 浏览
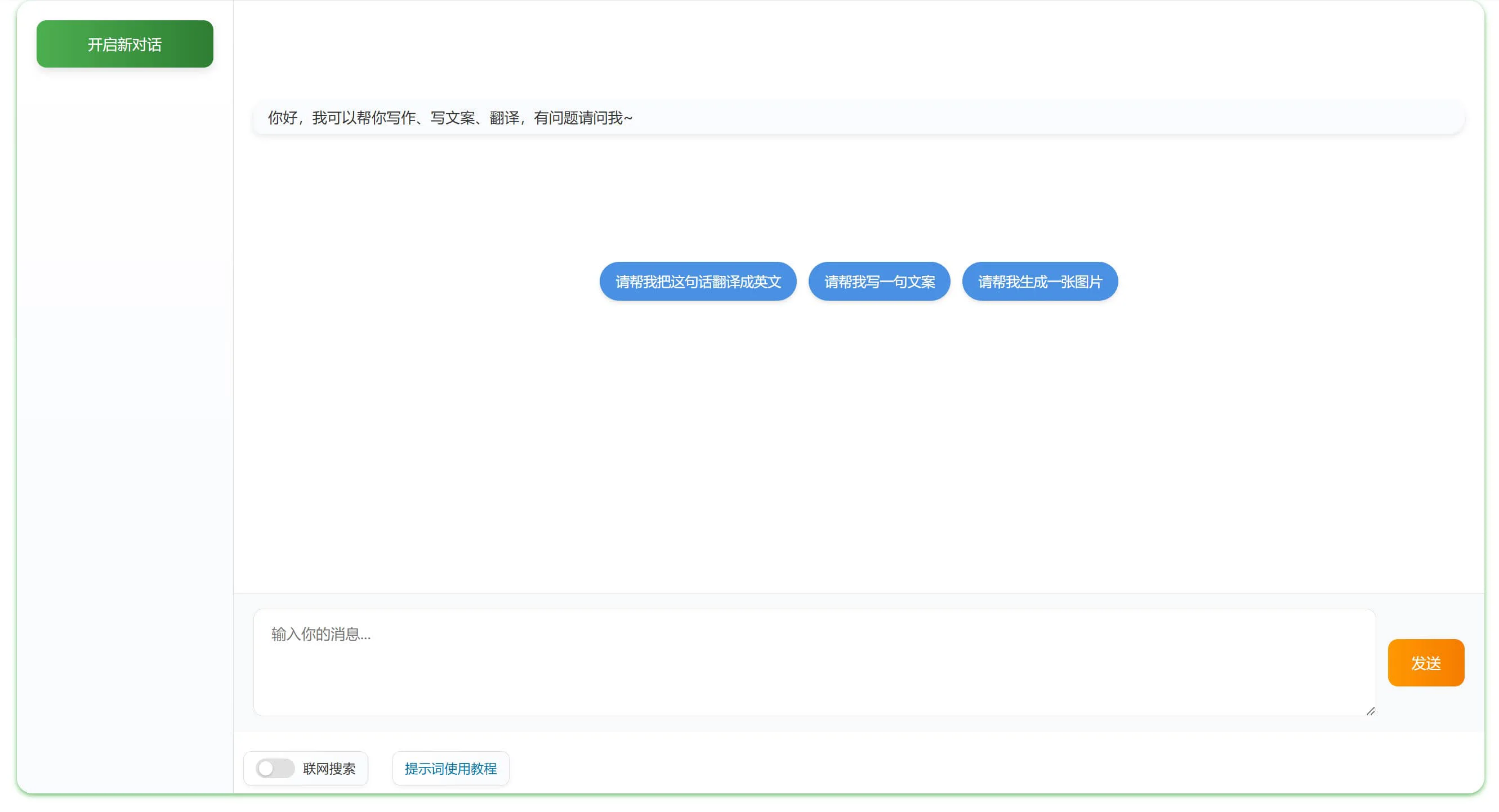
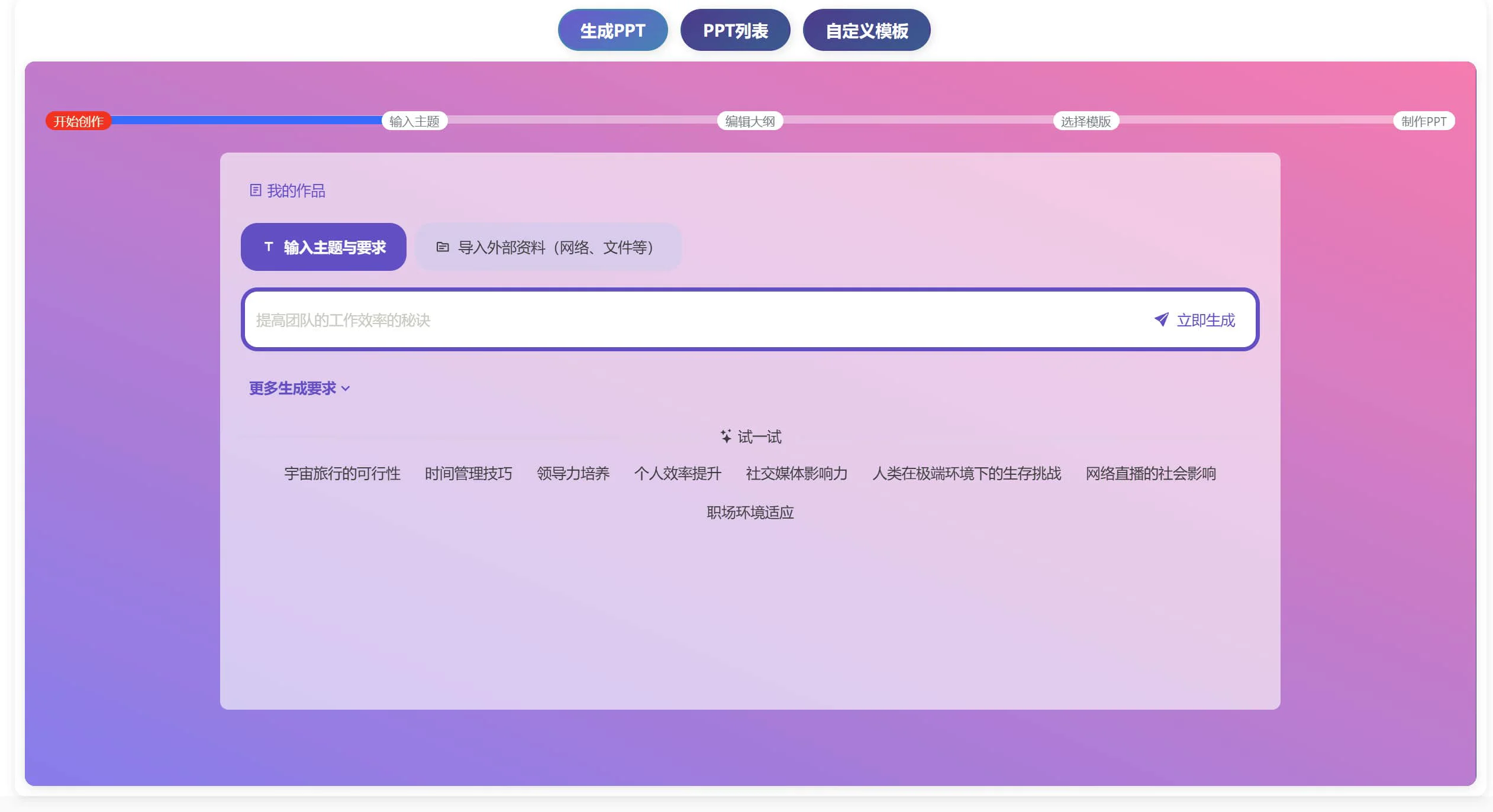
小半WordPress Ai助手 一个全免费开源WordPress插件,支持AI对话聊天、文章生成、文章总结、文章翻译、生成PPT等功能,此外它还能对接DeepSeek、豆包和通义千问等模型。 Ai编程建站 2025年06月05日 19 点赞 0 评论 814 浏览