Amazon Bedrock Amazon Bedrock是一款由AWS推出的完全托管型AI服务平台,集成了多家顶级AI公司的基础模型,支持企业通过单一API访问高性能模型。它提供了从基础模型接入、微调到代理构建的一系列功能,包括检索增强生成(RAG)、自动推理检查及多Agent协作等特性。此外,其模型蒸馏技术能够有效提升效率并降低运行成本,广泛适用于文本生成、虚拟助手、图像生成等多种应用场景。 AI项目与工具 2025年06月12日 88 点赞 0 评论 789 浏览
AISEO Art AISEO Art是一款基于AI技术的艺术生成平台,支持用户通过文本提示生成个性化视觉艺术作品。平台提供包括AI头像生成、图像变体、艺术模板选择及滤镜应用在内的多项功能,适用于广告设计、数字艺术创作、游戏开发及社交媒体营销等多个场景,助力用户高效产出高质量视觉内容。 AI项目与工具 2025年06月12日 81 点赞 0 评论 790 浏览
Freeflo.ai Freeflo.ai 是一个多功能的 AI 绘画辅助平台,它通过提供丰富的风格提示词和直观的样例图像,极大地丰富了 AI 绘画的创作可能性。 创作工具 2026年06月14日 0 点赞 0 评论 790 浏览
Boow Boow-VTON是一种基于先进图像生成技术和数据增强方法的虚拟试衣技术,无需精确遮罩即可实现高质量试穿效果。该工具通过试穿定位损失和注意力机制,精准识别试穿区域并确保服装自然贴合人体,支持多服装试穿且操作简便。其应用场景包括在线购物、时尚零售、个性化推荐、社交媒体互动及服装设计等多个领域,具有广泛的商业应用价值。 AI项目与工具 2025年06月12日 49 点赞 0 评论 791 浏览
Chatbox AI Chatbox AI是一款开源跨平台AI助手,支持多语言模型集成与本地部署,提供图像生成、代码辅助、文档交互等功能。用户可自由定制并参与社区开发,确保数据安全与隐私保护,适用于办公、学习、开发等多种场景,提升工作效率与创意表达。 AI项目与工具 2025年06月12日 66 点赞 0 评论 791 浏览
Ideogram AI Ideogram AI通过其在线应用程序ideogram.ai,允许用户通过文字提示以多种艺术风格生成图像。 Ai绘画生成 2025年06月05日 22 点赞 0 评论 791 浏览
ComfyGen ComfyGen是一款基于大型语言模型(LLM)的文本到图像生成系统,能够根据用户提供的文本提示自动生成高质量图像。它通过结合多种专业组件如微调基础模型、LoRAs、嵌入技术和超分辨率处理等构建复杂工作流,并采用两种基于LLM的方法优化图像生成质量,适用于艺术创作、游戏开发、广告设计、电影制作等多个领域。 AI项目与工具 2025年06月12日 54 点赞 0 评论 792 浏览
LatentLM LatentLM是一款由微软与清华大学合作开发的多模态生成模型,能够统一处理文本、图像、音频等多种数据类型。它基于变分自编码器(VAE)和因果Transformer架构,支持自回归生成与跨模态信息共享,特别擅长图像生成、多模态语言模型及文本到语音合成等任务,其提出的σ-VAE进一步提升了模型的鲁棒性。 AI项目与工具 2025年06月12日 67 点赞 0 评论 795 浏览
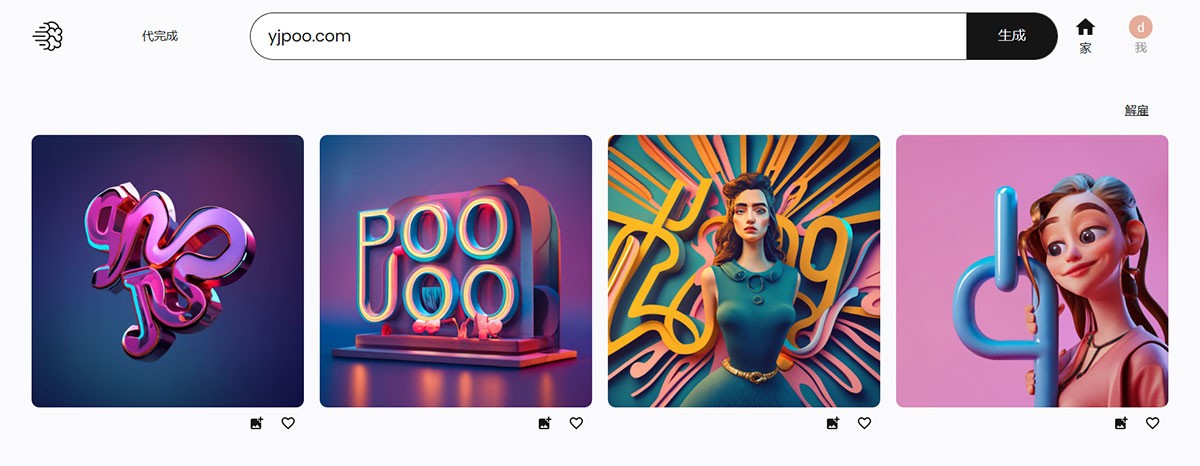
CogView CogView-3-Plus是智谱AI研发的AI文生图模型,采用Transformer架构替代传统的UNet,优化了扩散模型中的噪声规划。它能够根据用户指令生成高质量、高美学评分的图像,支持多种分辨率,并具有实时生成图像的能力。该模型已被集成到“智谱清言”APP中,并提供API服务,适用于艺术创作、游戏设计、广告制作等多个图像生成领域。 AI项目与工具 2025年06月12日 64 点赞 0 评论 795 浏览
Publer AI Assist Publer AI Assist 使用最新的人工智能技术帮助您在几秒钟内生成内容、创建令人惊叹的图像并像专业人士一样回复评论。 裂变增长 2025年06月05日 66 点赞 0 评论 796 浏览