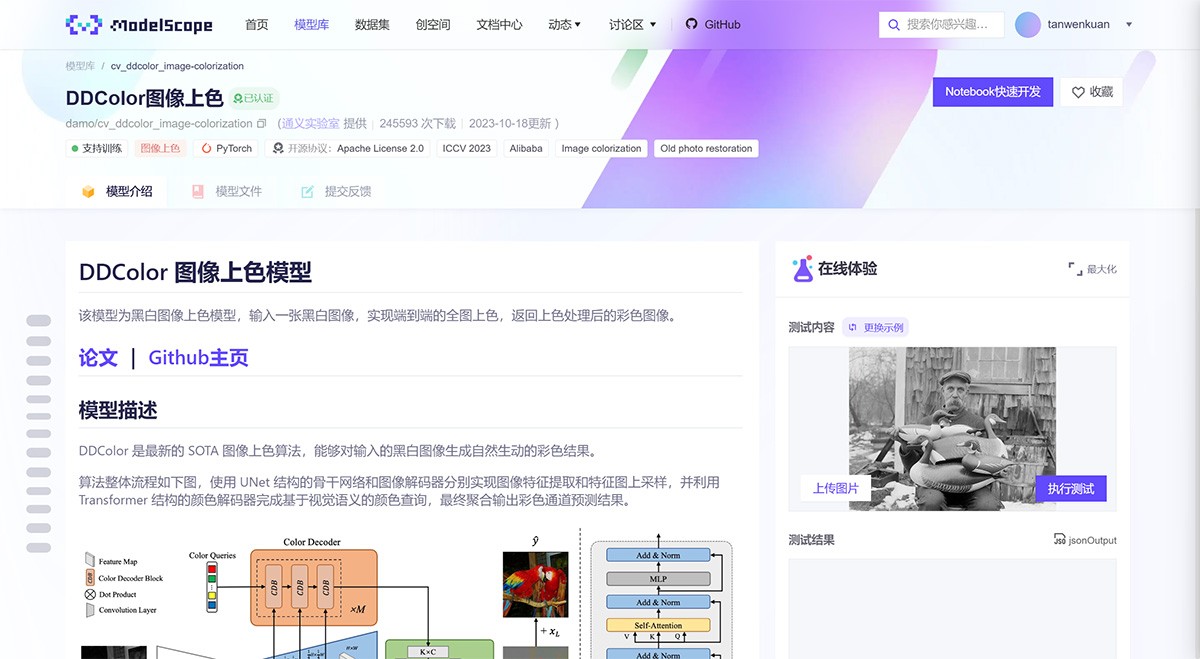
解码器







The Language of Motion
The Language of Motion是一款由斯坦福大学李飞飞团队开发的多模态语言模型,能够处理文本、语音和动作数据,生成对应的输出模态。该模型在共同语音手势生成任务上表现出色,且支持情感预测等创新任务。它采用编码器-解码器架构,并通过端到端训练实现跨模态信息对齐。The Language of Motion广泛应用于游戏开发、电影制作、虚拟现实、增强现实及社交机器人等领域,推动了虚拟角色自