VILA-U 是一款由 MIT 汉实验室开发的统一基础模型,整合了视频、图像和语言的理解与生成能力。它通过自回归框架简化模型结构,支持视觉理解、视觉生成、多模态学习和零样本学习等功能。VILA-U 在预训练阶段采用混合数据集,利用残差向量量化和深度变换器提升表示能力,适用于图像生成、内容创作辅助、自动化设计、教育和残障人士辅助等多种场景。
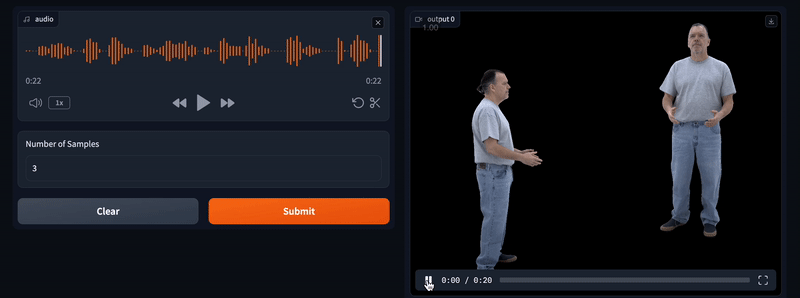
Fish Speech 1.5是一款基于深度学习的文本转语音(TTS)工具,支持多语言文本输入,通过Transformer、VITS、VQVAE和GPT等技术实现高质量语音合成。它具备零样本和少样本语音合成能力,延迟时间短,无需依赖音素,泛化性强,且支持本地化部署。Fish Speech 1.5可应用于有声读物、辅助技术、语言学习及客户服务等多个领域。