Tripo3D AI 一个由VAST发布的在线3D建模平台,利用先进的AI技术,可以在几秒钟内生成高质量的3D模型。用户可以通过文本描述或上传图片来生成模型。 3D&游戏 2025年06月05日 63 点赞 0 评论 822 浏览
Kandinsky Kandinsky-3是一款基于潜在扩散模型的文本到图像生成框架,支持文本到图像生成、图像修复、图像融合、文本-图像融合、图像变化生成及视频生成等多种功能。其核心优势在于简洁高效的架构设计,能够快速生成高质量图像并提升推理效率。 AI项目与工具 2025年06月12日 84 点赞 0 评论 685 浏览
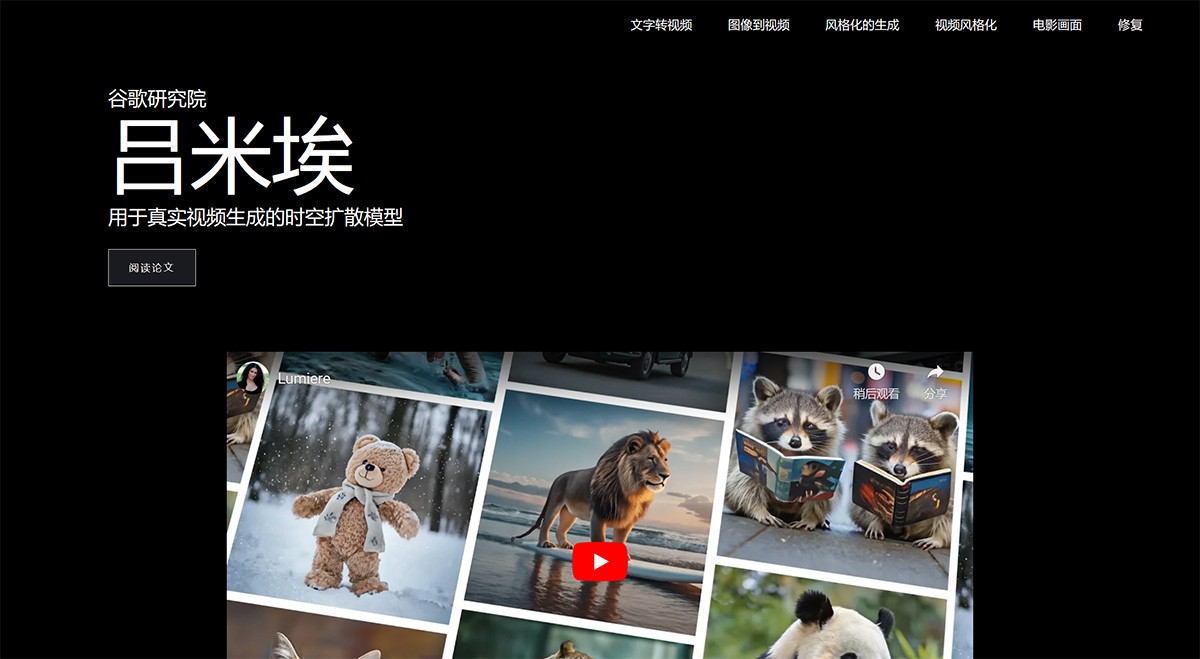
Lumiere 谷歌研究院开发的基于空间时间的文本到视频扩散模型。采用了创新的空间时间U-Net架构,能够一次性生成整个视频的时间长度,确保了生成视频的连贯性和逼真度。 Ai开源项目 2025年06月05日 74 点赞 0 评论 657 浏览
Perception Perception-as-Control是由阿里巴巴通义实验室开发的图像动画框架,支持对相机和物体运动的细粒度控制。它基于3D感知运动表示,结合U-Net架构的扩散模型,实现多种运动相关的视频合成任务,如运动生成、运动克隆、转移和编辑。通过三阶段训练策略,提升运动控制精度和稳定性,适用于影视、游戏、VR/AR、广告及教育等多个领域。 AI项目与工具 2025年06月12日 20 点赞 0 评论 616 浏览
CogSound CogSound是一款基于AI的音效生成工具,能够为无声视频添加与内容匹配的高质量音效,涵盖多种复杂场景。该工具通过先进的音视频特征匹配技术和优化的生成算法,提升了视频的沉浸感和真实感,广泛应用于视频创作、广告制作及影视后期等多个领域。 AI项目与工具 2025年06月12日 12 点赞 0 评论 555 浏览
ELLA ELLA(Efficient Large Language Model Adapter)是一种由腾讯研究人员开发的方法,旨在提升文本到图像生成模型的语义对齐能力。它通过引入时序感知语义连接器(TSC),动态提取预训练大型语言模型(LLM)中的时序依赖条件,从而提高模型对复杂文本提示的理解能力。ELLA无需重新训练,可以直接应用于预训练的LLM和U-Net模型,且能与现有模型和工具无缝集成,显著提升 AI项目与工具 2024年01月01日 74 点赞 0 评论 488 浏览
MimicMotion MimicMotion是一款由腾讯研究团队开发的高质量人类动作视频生成框架。该框架利用置信度感知的姿态引导技术,确保视频帧的高质量和时间上的平滑过渡。通过区域损失放大和手部区域增强,显著减少了图像失真,增强了手部动作的细节表现。该框架还支持长视频生成,通过渐进式潜在融合策略,确保视频生成时的时间连贯性和细节丰富度。 AI项目与工具 2025年06月12日 62 点赞 0 评论 475 浏览
Real 一个强大的图像超分辨率工具,它利用深度学习和生成对抗网络,在没有真实高分辨率图像作为参考的情况下,通过合成退化过程来提升低分辨率图像的质量。 Ai平台模型 1970年01月01日 0 点赞 0 评论 271 浏览