语音





Slides Orator
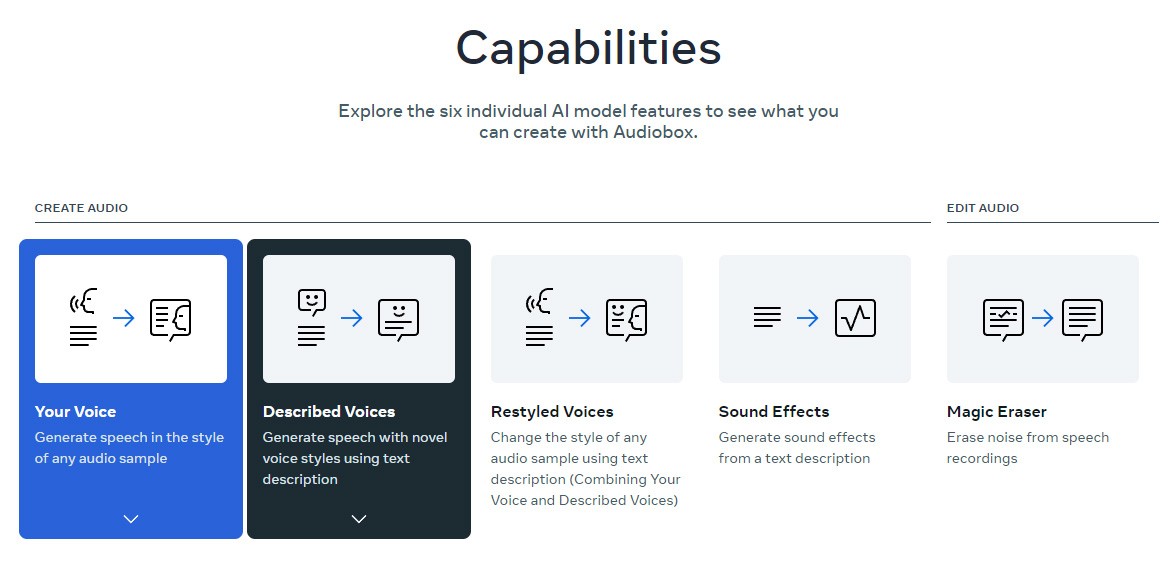
Slides Orator是一款基于AI技术的演示工具,支持用户通过创建虚拟形象实现幻灯片的实时解说。其核心功能包括语音旁白生成、实时聊天互动及模拟演示场景,广泛应用于企业培训、产品推介、在线教育和会议演讲等领域,旨在提升信息传递效率和观众参与度。通过简化操作流程,该工具帮助用户高效完成高质量演示内容的准备。


PengChengStarling
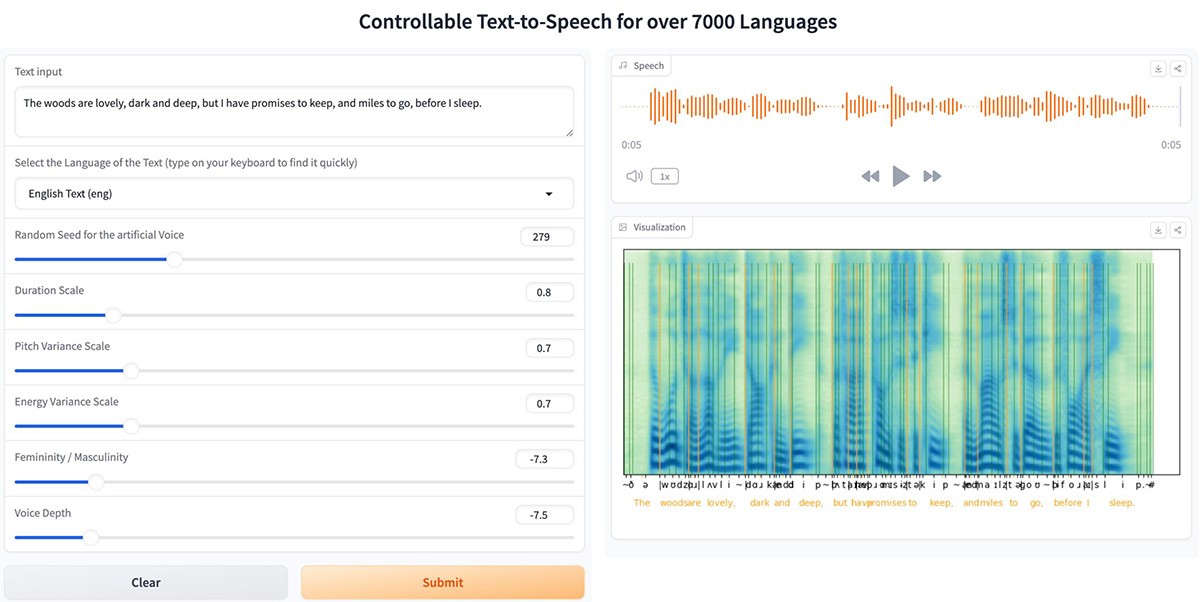
鹏城实验室开源的一款多语言语音识别系统开发工具包,PengChengStarling可以在统一的框架内处理多种语言语音输入,支持实时语音识别,边说边识别。

Reachout.ai
Reachout.ai是一个人工智能驱动的视频开发平台,专为忙碌的企业家和销售团队打造,他们希望突破收件箱的噪音,大规模生成个性化视频,并获得更高的电子邮件回复率和更多与理想客户...

