语音合成



All Voice Lab
All Voice Lab是一款基于AI技术的语音创作平台,提供文本转语音、声音克隆、视频翻译、变声等多种功能,支持多语言及多音色转换。平台具备高精度的语音生成能力,可应用于内容创作、视频制作、教育及娱乐等领域,提升内容表现力与国际化传播效率。

ElevenLabs Flash
ElevenLabs Flash是一款专为对话型AI设计的低延迟语音合成模型,支持多种语言,能够以极短的延迟(75毫秒)生成高质量语音,广泛应用于虚拟助手、客户服务、语音播报、教育及娱乐等领域,为用户提供即时反馈和沉浸式体验。该工具以其高效性和灵活性成为超低延迟语音合成领域的领先解决方案。
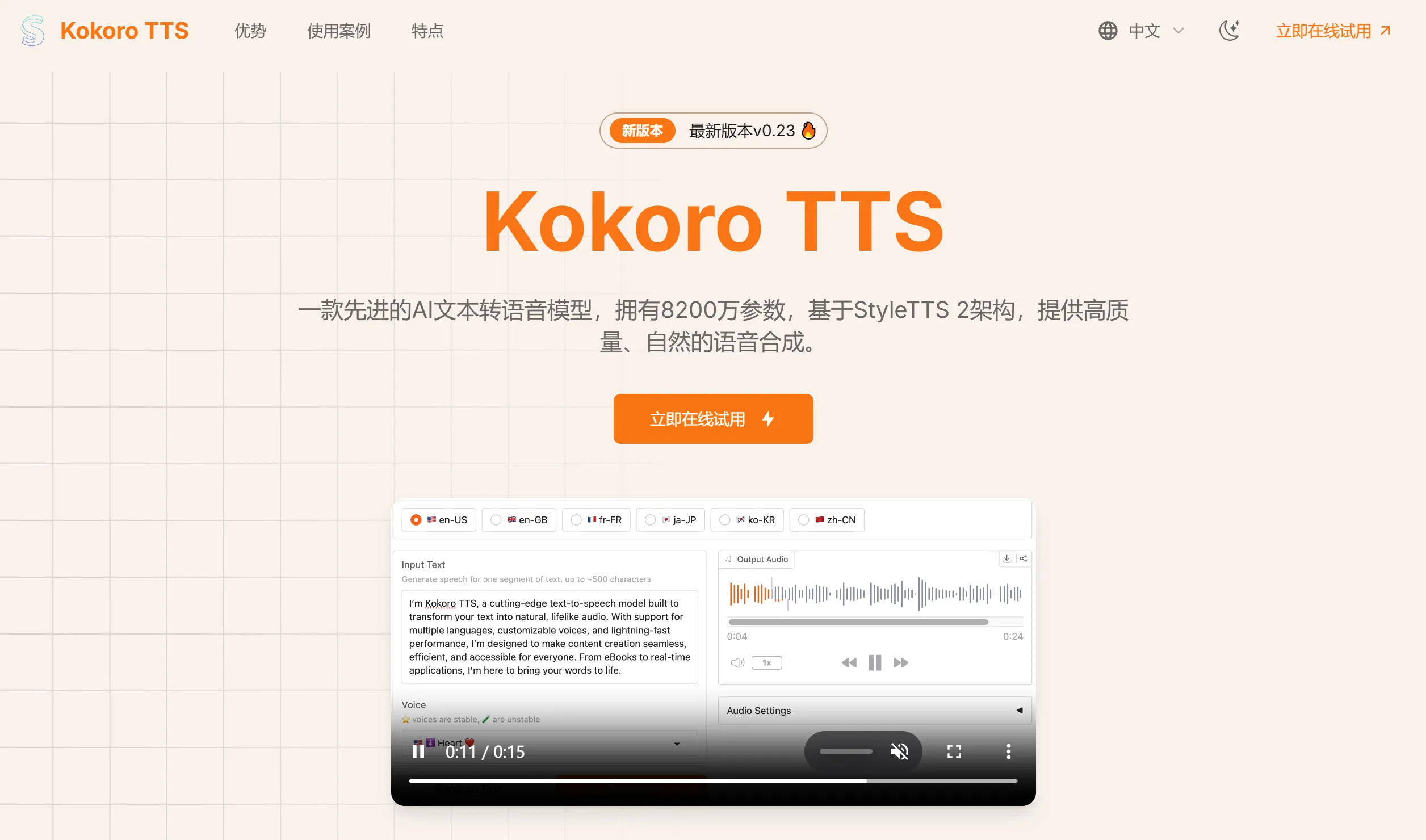

Freestyler
Freestyler是一款由多机构合作开发的AI工具,专注于说唱音乐的自动化生成。它通过结合语言模型、条件流匹配技术和神经声码器,实现了从歌词和伴奏到高质量说唱音频的全流程转化。Freestyler还推出了RapBank数据集,并支持零样本音色控制,广泛应用于音乐创作、现场表演、游戏音效及教育等领域。



OmniTalker
OmniTalker 是一款由阿里巴巴开发的实时多模态交互技术,支持文本、图像、音频和视频的同步处理,并能生成自然流畅的语音响应。其核心技术包括 Thinker-Talker 架构和 TMRoPE 时间对齐技术,实现音视频精准同步与高效流式处理。适用于智能语音助手、内容创作、教育、客服及工业质检等场景,具有高实时性与稳定性。

