WarriorCoder WarriorCoder是由华南理工大学与微软联合开发的代码生成大语言模型,采用专家对抗机制生成高质量训练数据,无需依赖专有模型或数据集。它具备代码生成、优化、调试、推理及多语言支持等功能,在代码生成、库使用等任务中达到SOTA性能,适用于自动化开发、教育辅助及跨语言转换等场景。模型通过Elo评分系统和裁判评估确保训练数据质量,提升泛化能力与多样性。 AI项目与工具 2025年06月12日 27 点赞 0 评论 619 浏览
思必驰 DFM-2 大模型 思必驰 DFM-2 大模型作为思必驰的自研对话式语言大模型,展现了其在多模态交互和行业应用中的潜力。它通过结合先进的AI技术,为用户提供了更加智能化和个性化的体验,推动了智能语... Ai平台模型 1970年01月01日 0 点赞 0 评论 620 浏览
R1 R1-Onevision 是一款基于 Qwen2.5-VL 微调的开源多模态大语言模型,擅长处理图像与文本信息,具备强大的视觉推理能力。它在数学、科学、图像理解等领域表现优异,支持多模态融合与复杂逻辑推理。模型采用形式化语言和强化学习技术,提升推理准确性与可解释性,适用于科研、教育、医疗及自动驾驶等场景。 AI项目与工具 2025年06月12日 92 点赞 0 评论 620 浏览
琴乐大模型 琴乐大模型是一款由腾讯AI Lab与腾讯TME天琴实验室联合开发的人工智能音乐创作工具。该工具能够根据用户输入的关键词、描述性语句或音频,生成高质量的立体声音频或多轨乐谱,并支持自动编辑功能。琴乐大模型采用先进的技术框架,包括音频文本对齐、乐谱/音频表征提取、大语言模型预测以及流匹配和声码器技术,确保生成的音乐符合音乐理论和人类审美标准。 AI项目与工具 2025年06月12日 33 点赞 0 评论 621 浏览
LongWriter LongWriter是一款由清华大学与智谱AI合作开发的长文本生成模型,能够生成超过10,000字的连贯文本。该模型基于增强的长上下文大型语言模型,采用了直接偏好优化(DPO)技术和AgentWrite方法,能够处理超过100,000个token的历史记录。LongWriter适用于多种应用场景,包括学术研究、内容创作、出版行业、教育领域和新闻媒体等。 AI项目与工具 2025年06月12日 67 点赞 0 评论 625 浏览
Open Avatar Chat Open Avatar Chat是阿里开源的模块化实时数字人对话系统,支持低延迟交互与多模态输入输出。系统采用模块化架构,允许灵活配置语音识别、语言模型和语音合成等组件,兼容本地与云服务。支持2D/3D数字人渲染,适用于客户服务、教育、娱乐及企业应用等多个场景,为开发者提供高效、灵活的AI对话解决方案。 AI项目与工具 2025年06月11日 81 点赞 0 评论 627 浏览
WiS WiS是一个基于“谁是卧底”游戏规则的在线AI竞赛平台,专为评估和分析大型语言模型(LLMs)在多智能体系统中的行为而设计。平台提供统一的模型评估接口、实时排行榜、全面的行为评估功能以及详尽的数据可视化支持,旨在为研究人员和开发者提供一个直观且高效的工具,用于测试和优化智能体在复杂交互环境中的表现。 AI项目与工具 2025年06月12日 20 点赞 0 评论 630 浏览
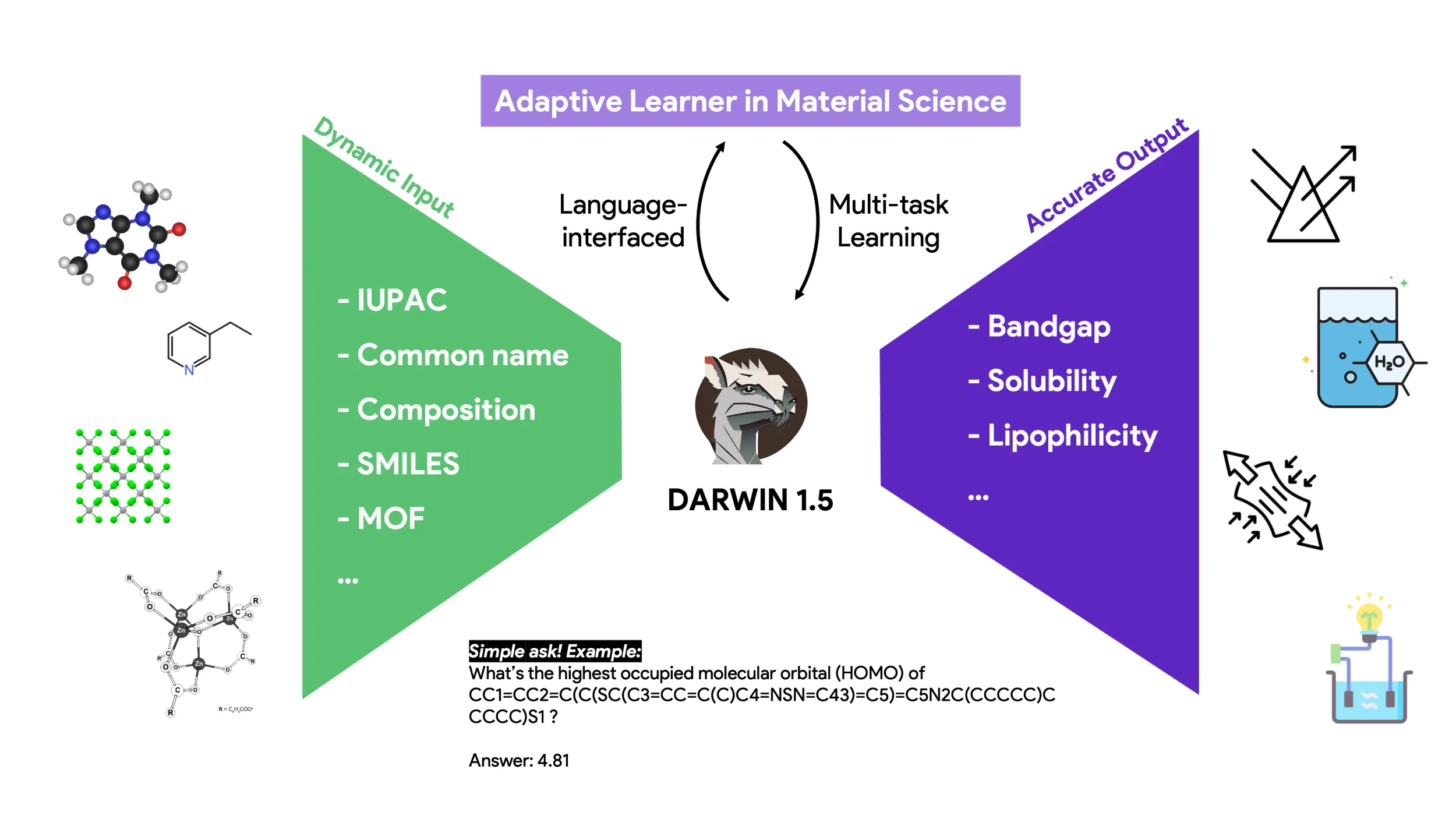
Darwin模型 Darwin模型是一个专门为自然科学领域(尤其是物理、化学和材料科学)设计的大语言模型(LLM),只要通过整合结构化和非结构化的科学知识,提升语言模型在科学研究 Ai平台模型 2025年06月05日 19 点赞 0 评论 631 浏览
dots.llm1 dots.llm1 是小红书 hi lab 开源的中等规模 Mixture of Experts(MoE)文本大模型,拥有 1420 亿参数,激活参数为 140 亿。模型在 11.2T 高质量 token 数据上预训练,采用高效的 Interleaved 1F1B 流水并行和 Grouped GEMM 优化技术,提升训练效率。该模型支持多语言文本生成、复杂指令遵循、知识问答、数学与代码推理以及多轮 AI项目与工具 2025年06月11日 78 点赞 0 评论 632 浏览
DeepSeek服务器繁忙怎么解决?16个免费R1满血版平替 本文介绍了16款可替代DeepSeek R1满血版的AI工具,涵盖本地部署、API调用及多平台解决方案。这些工具支持深度思考、联网搜索、多模态交互等功能,部分平台还提供高速专线、文档解析、图片识别等增强特性,满足不同场景下的AI需求。 AI项目与工具 2025年06月12日 62 点赞 0 评论 633 浏览