Creatify AI Creatify AI是一款由人工智能驱动的应用,只需输入产品链接或上传您自己的视觉和描述,Creatify将为您生成高质量的营销视频。 Ai视频生成 2025年06月05日 68 点赞 0 评论 984 浏览
MagicVideo MagicVideo-V2是一款由字节跳动公司团队开发的AI视频生成模型和框架。该模型通过集成文本到图像模型、视频运动生成器、参考图像嵌入模块和帧插值模块,实现了从文本到高保真视频的转换。生成的视频不仅具有高分辨率,而且在视觉质量和运动流畅度方面表现出色,为用户提供卓越的观看体验。 AI项目与工具 2024年01月01日 56 点赞 0 评论 981 浏览
JoyVASA JoyVASA是一个基于扩散模型的音频驱动数字人头项目,能够生成与音频同步的面部动态和头部运动。其主要功能包括唇形同步、表情控制及动物面部动画生成,支持多语言和跨物种动画化。项目采用两阶段训练方法,结合解耦面部表示与扩散模型技术,生成高质量动画视频,广泛应用于虚拟助手、娱乐媒体、教育、广告等多个领域。 AI项目与工具 2025年06月12日 17 点赞 0 评论 980 浏览
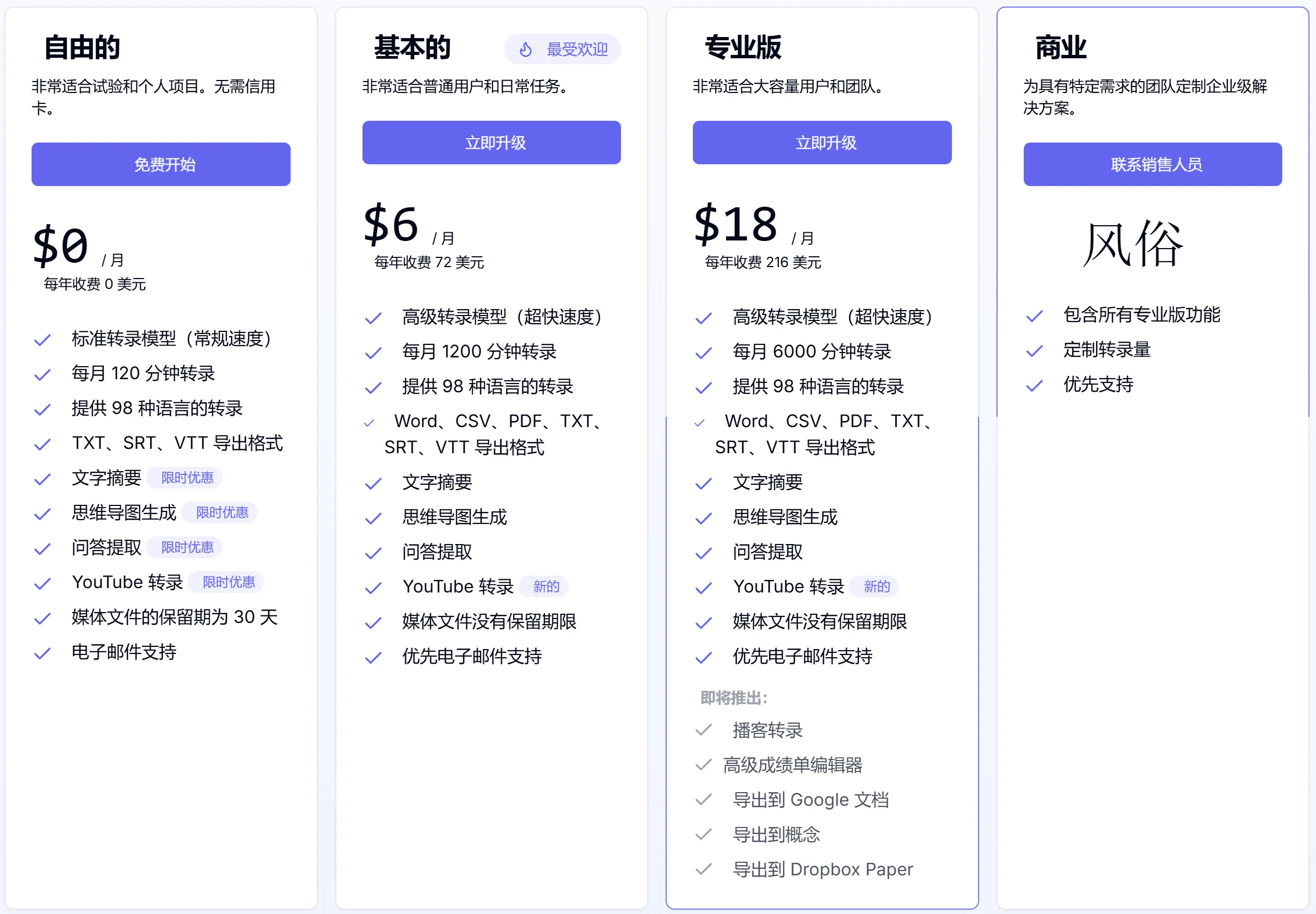
UniScribe 一个帮你更快的从音视频中获取信息的音视频转录和翻译工具。UniScribe能快速将本地音频、视频文件或 YouTube 视频转化为简短摘要,帮助您轻松掌握要点,支持98种语言。 Ai办公效率 2025年06月05日 33 点赞 0 评论 980 浏览
DanceGRPO DanceGRPO 是由字节跳动与香港大学联合开发的视觉生成强化学习框架,支持文本到图像、文本到视频、图像到视频等多种任务,兼容多种生成模型与奖励机制。其通过强化学习优化生成过程,提升视觉内容质量与一致性,降低显存压力,提高训练效率与稳定性,适用于视频生成和多模态内容创作。 AI项目与工具 2025年06月11日 45 点赞 0 评论 979 浏览
Creatus.AI Creatus.ai 是一个允许您使用人工智能从文本输入生成引人入胜的视频内容的平台。无论您是想为社交媒体渠道、网站、博客还是在线课程制作视频,Creatus.ai 都可以帮助您轻松高效地完成。 Ai视频生成 2025年06月05日 26 点赞 0 评论 976 浏览
I2V I2V-01-Live是一款基于深度学习技术的图生视频工具,可将静态二维图像转化为动态视频,具有高度流畅的动作表现和多样化的艺术风格适配能力。其核心功能包括动态呈现、动作效果增强及稳定的表情管理,广泛应用于社交媒体、广告营销、动画制作、教育培训以及游戏开发等领域。 AI项目与工具 2024年12月06日 82 点赞 0 评论 974 浏览
gling Gling是一款集成了先进AI技术的视频编辑工具,主要功能涵盖自动去除不良拍摄片段、消除沉默及填充词、生成AI字幕、自动缩放画面、降低背景噪音等。它还能够为视频生成优化标题与章节,适用于个人视频博主、播客制作人、在线教育者及企业培训等多个领域,助力提升视频质量和效率。 AI项目与工具 2025年06月12日 78 点赞 0 评论 973 浏览
悦灵犀AI 悦灵犀AI是一款基于先进AI技术的创作平台,支持文生图、文生视频、背景替换、证件照生成及照片修复等多种功能。其智能助手和丰富工具使用户能够高效创作艺术作品,并广泛应用于艺术设计、广告营销、教育等领域。 AI项目与工具 2025年06月12日 51 点赞 0 评论 973 浏览