Wan2.1 Wan2.1是阿里云推出的开源AI视频生成模型,支持文生视频与图生视频,具备复杂运动生成和物理模拟能力。采用因果3D VAE与视频Diffusion Transformer架构,性能卓越,尤其在Vbench评测中表现领先。提供专业版与极速版,适应不同场景需求,已开源并支持多种框架,便于开发与研究。 AI项目与工具 2025年06月12日 47 点赞 0 评论 672 浏览
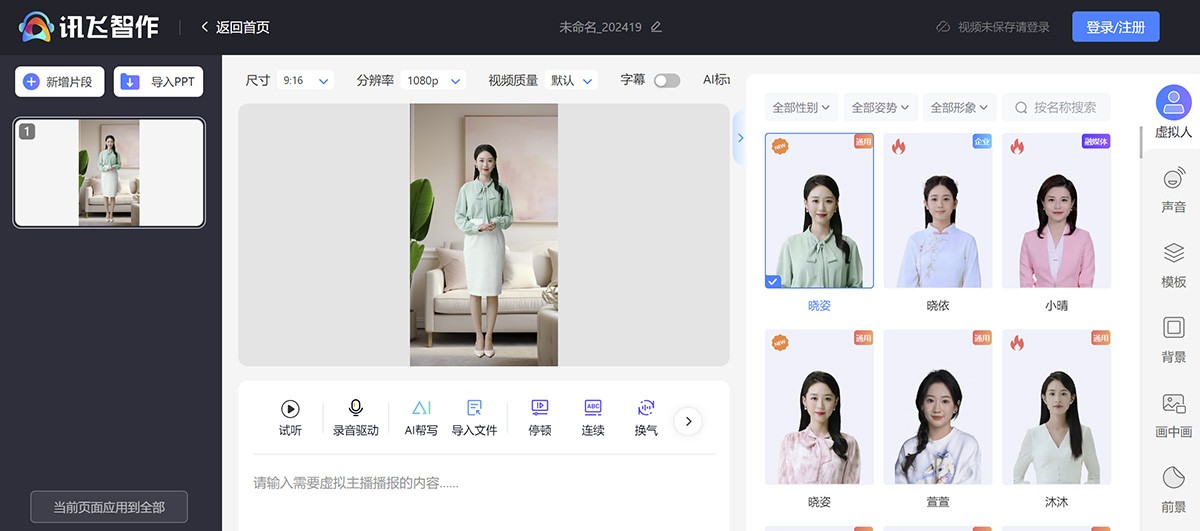
讯飞智作 一款集AI配音、虚拟数字人视频生成、PPT生成视频、数字人定制等多功能的AI音视频生产平台。已广泛应用于媒体、教育、短视频等领域。 Ai视频生成 2025年06月05日 64 点赞 0 评论 671 浏览
HermitAI 一款专为外贸/跨境人员打造的营销文案撰写工具,可以智能生成多场景跨境外贸营销文案,解决邮件、社媒平台、跨境平台、翻译等多种工作场景。 AI写作对话 2025年06月05日 88 点赞 0 评论 668 浏览
幻图AI 幻图AI是一款基于AI技术的免费图像处理工具,支持文生图、图片和视频换脸、换装、头像定制等功能。用户通过简单的操作即可生成高质量的创意图像和视频,广泛应用于社交媒体、电商、广告设计和教育培训等领域,提供高效且个性化的视觉创作体验。 AI项目与工具 2025年06月12日 70 点赞 0 评论 668 浏览
熊猫字幕 一款专业的在线字幕网站,提供自动在线字幕生成,视频音频字幕生成,字幕制作,语音转字幕,语音自动生成字幕,字幕翻译,字幕格式转换等各种字幕功能。 字幕配音 2025年06月05日 80 点赞 0 评论 667 浏览