虚拟

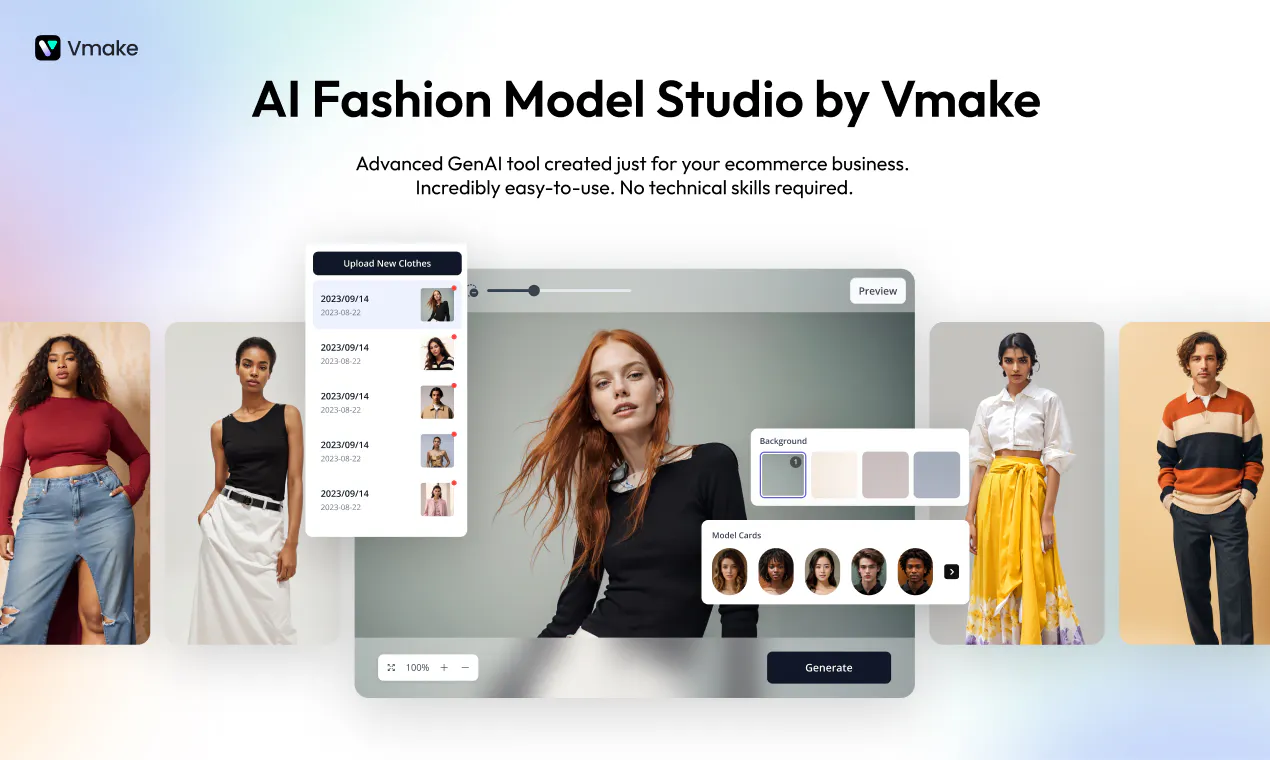








Symphony Creative Studio
Symphony Creative Studio是一款由TikTok开发的AI视频创作工具,专注于简化广告主和内容创作者的视频制作流程。它具备视频生成、转换、扩展以及虚拟人物创作等功能,支持多语言翻译与配音,并可基于品牌IP定制虚拟形象。通过整合多种智能技术,该工具显著提升了内容创作效率与质量。

