SpatialVLA SpatialVLA是一款由多机构联合研发的空间具身通用操作模型,具备强大的3D空间理解能力与跨平台泛化控制能力。通过Ego3D位置编码和自适应动作网格技术,实现精准的环境感知与动作生成。支持零样本任务执行与快速微调,适用于工业、物流、医疗等多个领域,推动机器人技术的发展与应用。 AI项目与工具 2025年06月12日 39 点赞 0 评论 696 浏览
CodePal AI CodePal是一个提供一系列编码助手和工具,帮助开发人员的平台。它适用于学生、初学者、经验丰富的开发人员以及希望改进开发流程的公司。 Ai编程建站 2025年06月05日 20 点赞 0 评论 698 浏览
StableAnimator StableAnimator是一款由复旦大学、微软亚洲研究院、虎牙公司及卡内基梅隆大学联合开发的高质量身份保持视频生成框架。它能够根据参考图像和姿态序列,直接生成高保真度、身份一致的视频内容,无需后处理工具。框架集成了图像与面部嵌入计算、全局内容感知面部编码器、分布感知ID适配器以及Hamilton-Jacobi-Bellman方程优化技术,确保生成视频的流畅性和真实性。StableAnimato AI项目与工具 2025年06月12日 14 点赞 0 评论 706 浏览
混元DiT 混元DiT(Hunyuan-DiT)是腾讯混元团队开源的高性能文本到图像的扩散Transformer模型,具备细粒度的中英文理解能力,能够生成多分辨率的高质量图像。该模型结合了双语CLIP和多语言T5编码器,通过精心设计的数据管道进行训练和优化。混元DiT的主要功能包括双语文本到图像生成、细粒度中文元素理解、长文本处理能力、多尺寸图像生成、多轮对话和上下文理解、高一致性和艺术性。此外,混元DiT在 AI项目与工具 2024年01月01日 64 点赞 0 评论 713 浏览
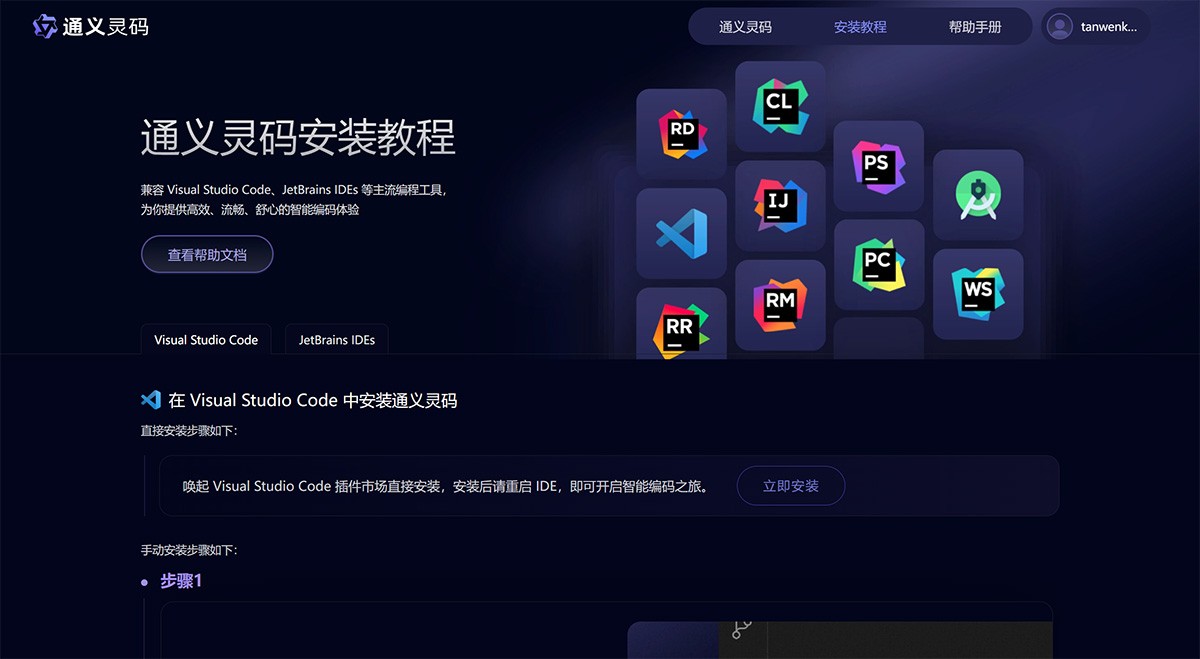
通义灵码 通义灵码,你的智能编码助手,为开发者提供行级和函数级代码续写、单元测试生成、代码注释生成、研发智能问答等能力,助你高质高效地完成编码工作。 Ai编程建站 2025年06月05日 88 点赞 0 评论 726 浏览
MEXMA MEXMA是一种由Meta AI研发的预训练跨语言句子编码器,通过结合句子级和词语级目标优化句子表示质量。它支持80种语言,广泛应用于跨语言信息检索、机器翻译、多语言文本分类、语义文本相似度评估及跨语言问答系统等领域,并展现出卓越的性能。 AI项目与工具 2025年06月12日 39 点赞 0 评论 729 浏览
Seed1.5 Seed1.5-Embedding 是由字节跳动推出的高性能向量模型,基于 Seed1.5 训练优化,具有强大的语义编码和检索能力。模型采用 Siamese 双塔结构,支持多种向量维度,并通过两阶段训练提升表征能力。它适用于信息检索、文本分类、推荐系统、聚类分析等多种任务,尤其在复杂查询和推理任务中表现突出,具备良好的灵活性和可扩展性。 AI项目与工具 2025年06月11日 37 点赞 0 评论 729 浏览
DefinityLegend DefinityLegend是一个创新的游戏平台,它通过提供无代码的游戏构建工具,降低了游戏开发的门槛,使得任何有创意的人都可以成为游戏开发者 创作工具 2026年07月29日 0 点赞 0 评论 734 浏览