Freepik Mystic Freepik Mystic是一款由Magnific AI和Freepik合作开发的AI图像生成工具,它能够生成高分辨率(1,664 x 2,432)的全高清图像,涵盖写实肖像、动物、风景、奇幻场景、室内设计、建筑概念、像素艺术、游戏元素和表情包等多种类型。图像由顶尖艺术家策划并经过微调优化,确保高质量输出。用户可以通过Freepik Premium订阅使用该工具,并期待其未来集成到Magnifi AI项目与工具 2025年06月12日 95 点赞 0 评论 652 浏览
FunGPT FunGPT 是一款基于 InternLM2.5 大模型开发的开源工具,专注于情感互动与情绪调节。它包含“甜言蜜语模式”和“犀利怼语模式”,分别用于提升用户情绪和释放压力。项目采用轻量化模型与 AWQ 量化技术,兼顾性能与效率。适用于创意启发、娱乐互动等多种场景,适合对情感交互感兴趣的开发者和用户。 AI项目与工具 2025年06月11日 86 点赞 0 评论 652 浏览
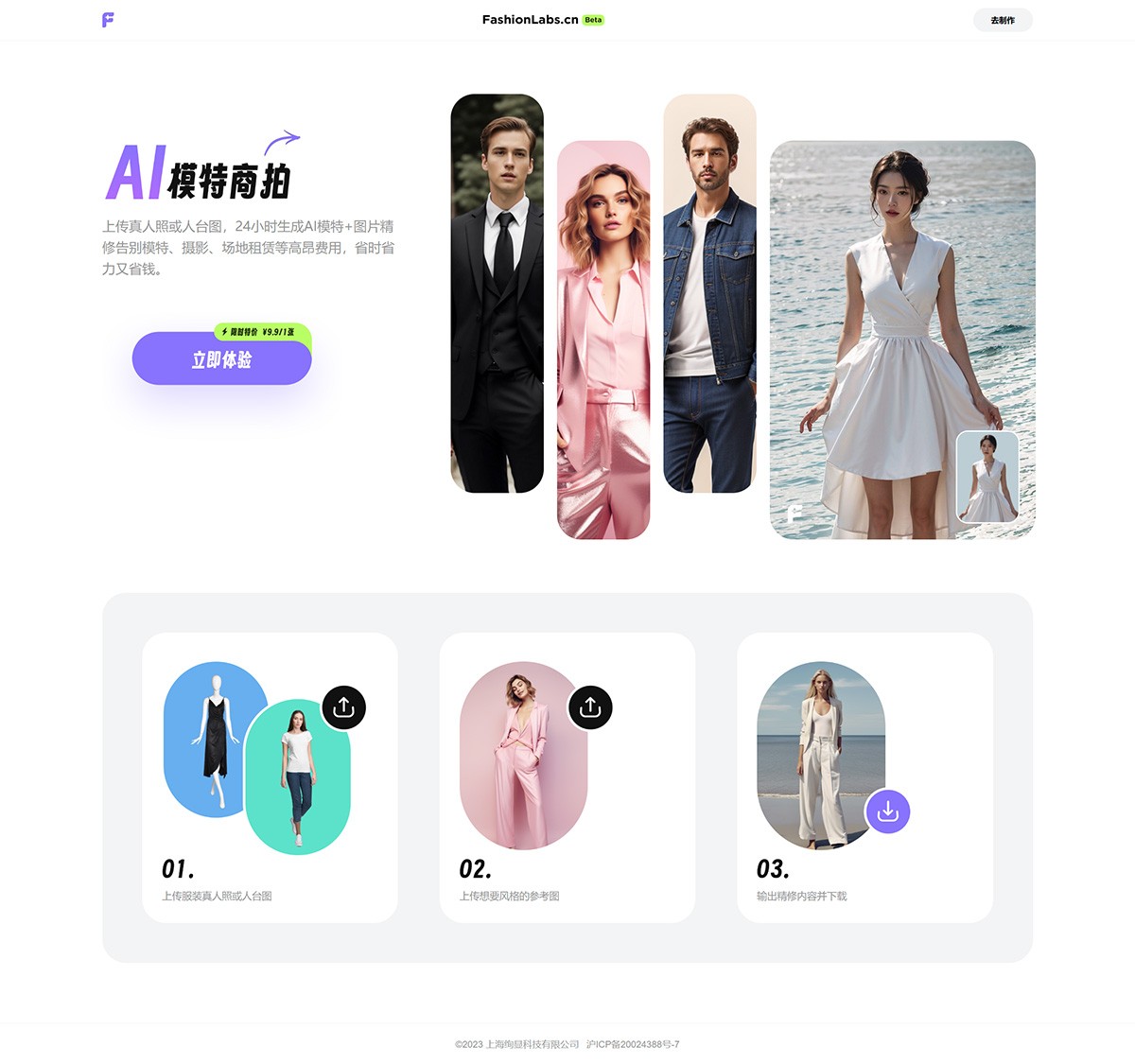
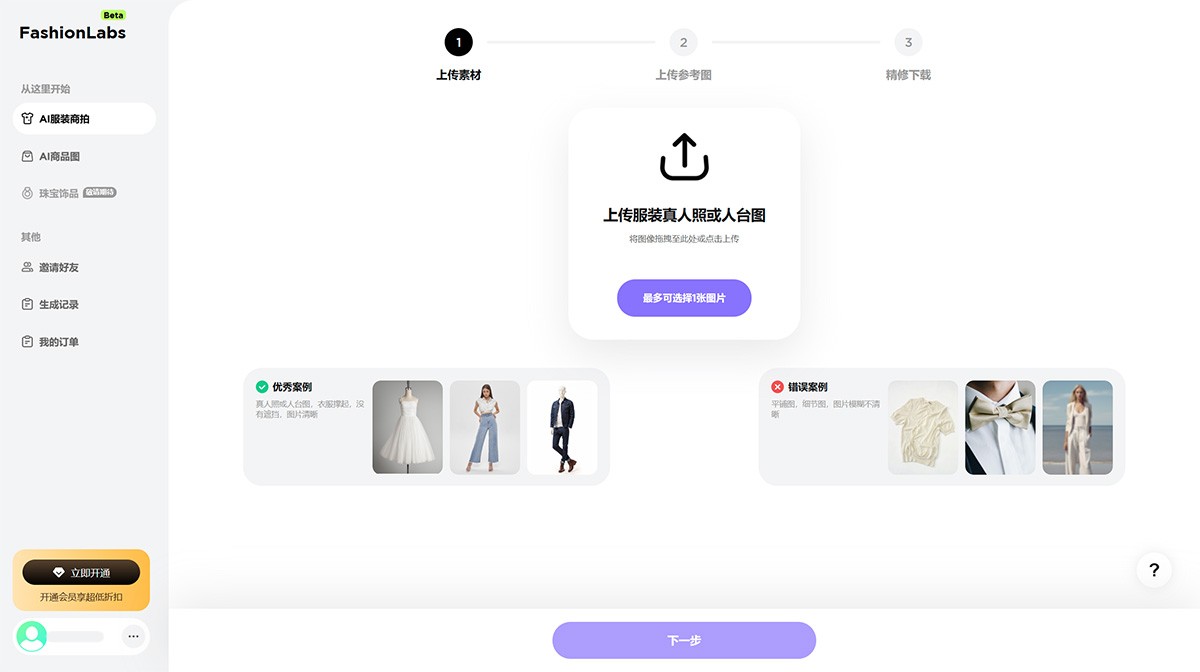
FashionLabs FashionLabs,AI服装模特商拍,为商家和品牌打造独特的AI商品图片,提供高品质的AI服装模特,为用户展现服装的魅力,提升品牌形象和销售。 Ai绘画生成 2025年06月05日 59 点赞 0 评论 652 浏览
理想同学 理想同学是一款基于AI技术打造的智能助手,集成了知识问答、视觉识别、绘画创作和播客等多种功能。它支持多领域的信息查询、语言翻译、文本生成及视觉分析,通过跨平台协作实现数据同步与连续对话。此外,用户可根据需求选择不同模型以优化推理能力,广泛适用于日常生活、学习和工作场景。 AI项目与工具 2025年06月12日 96 点赞 0 评论 652 浏览
Singify Fineshare Singify是一款在线AI歌曲翻唱生成工具,提供超过1000种声音模型,支持多种输入方式,如搜索、上传或录音,并允许用户调整音调、节奏等参数。其生成音乐免版税,适用于个人娱乐、社交媒体分享、音乐教学及广告制作等多个场景。平台界面友好,适合各类音乐创作者和爱好者使用。 AI项目与工具 2025年06月12日 67 点赞 0 评论 653 浏览
A2E A2E是一款基于AI技术的数字人视频创作平台,支持通过照片、视频或文本生成高度逼真的虚拟形象,具备声音克隆、多语言翻译、视频生成及形象换脸等功能。适用于内容创作、教育、营销等多个领域,帮助用户降低创作门槛,提升内容效率与表现力。 AI项目与工具 2025年06月11日 61 点赞 0 评论 653 浏览
LVCD LVCD是一款基于视频扩散模型的AI工具,专门用于动画视频线稿的自动上色。它通过参考注意力机制和创新的采样方法,确保视频颜色的一致性和时间连贯性,支持生成长时间序列动画。LVCD广泛应用于动漫制作、游戏开发、影视行业以及艺术创作等领域,显著提升动画制作效率。 AI项目与工具 2025年06月12日 98 点赞 0 评论 653 浏览
DeepSeek Engineer DeepSeek Engineer 是一款基于命令行的 AI 编程辅助工具,集成 DeepSeek API 提供文件操作功能。它通过 Pydantic 实现类型安全,支持 JSON 格式输出,可读取、创建和编辑本地文件,适用于代码审查、文档生成、实时协作和自动化测试等多种应用场景。 AI项目与工具 2025年06月12日 76 点赞 0 评论 653 浏览
Krea Stage Krea Stage 是一款基于 AI 技术的工具,能够将 2D 图像快速转换为可编辑的 3D 场景,并支持视频生成。用户可通过直观界面实时调整物体、光影和视角,无需专业建模知识。适用于影视、游戏、艺术、VR 和广告等多个领域,提升了 3D 内容创作的效率和灵活性。 AI项目与工具 2025年06月11日 16 点赞 0 评论 653 浏览