Copilot Actions Copilot Actions是微软推出的一款基于AI的自动化工具,隶属于Microsoft 365 Copilot。它支持用户通过简单提示完成日常重复性任务,如会议总结、报告生成及邮件分类等。通过预设模板和规则,AI能自动执行任务,提升工作效率,帮助用户集中精力处理高价值工作。目前该功能处于私人预览阶段。 AI项目与工具 2025年06月12日 19 点赞 0 评论 651 浏览
Voice Engine Voice Engine是由OpenAI开发的AI语音合成和声音克隆技术。该技术能够通过15秒的音频样本和文本输入生成自然语音。它已在OpenAI的文本到语音API和ChatGPT的语音功能中应用。Voice Engine广泛应用于教育、翻译、远程服务提供、支持言语残障者以及帮助恢复患者声音等方面。为了确保技术安全,OpenAI实施了严格的使用政策和安全措施。 AI项目与工具 2024年01月01日 59 点赞 0 评论 651 浏览
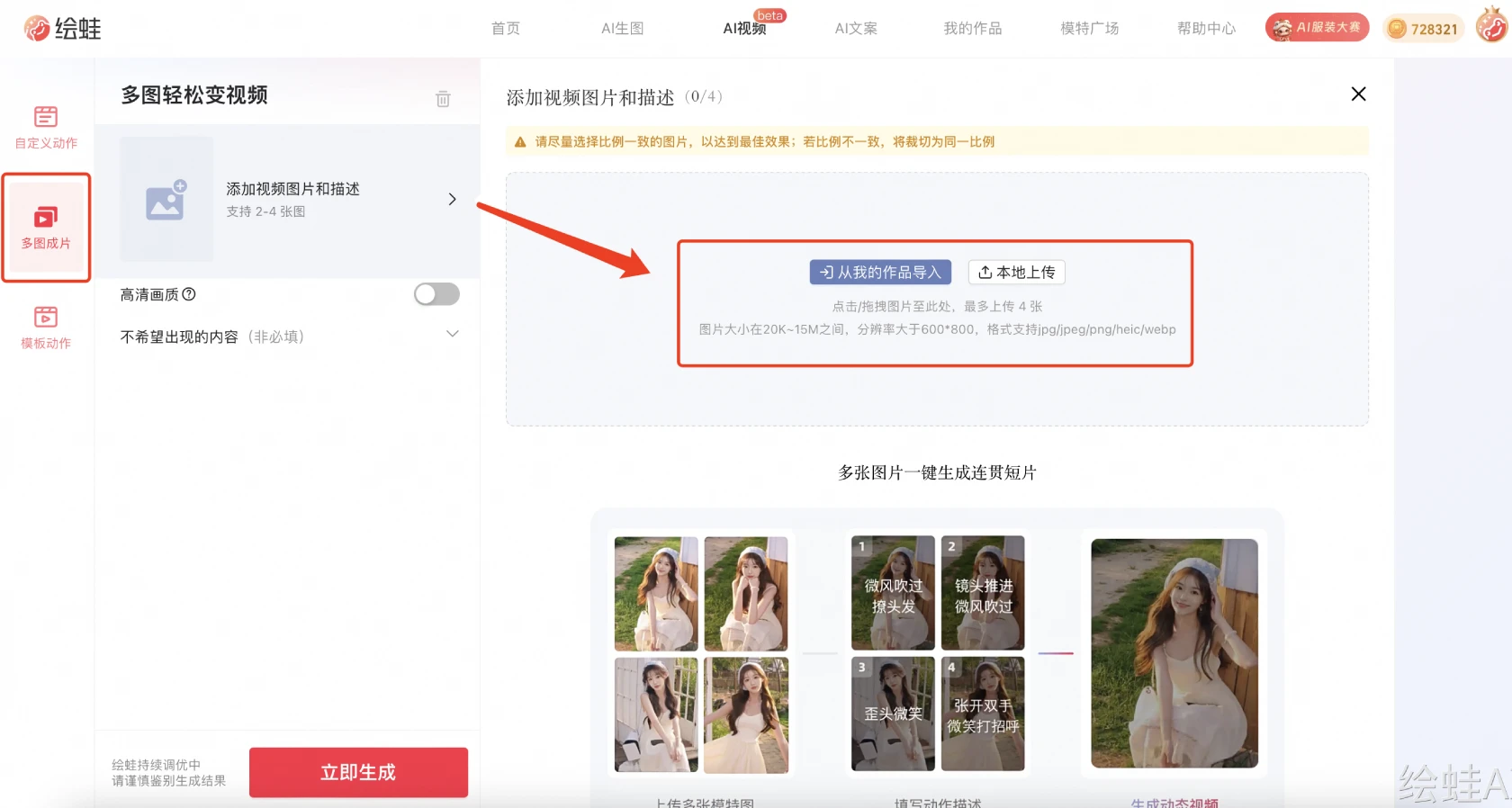
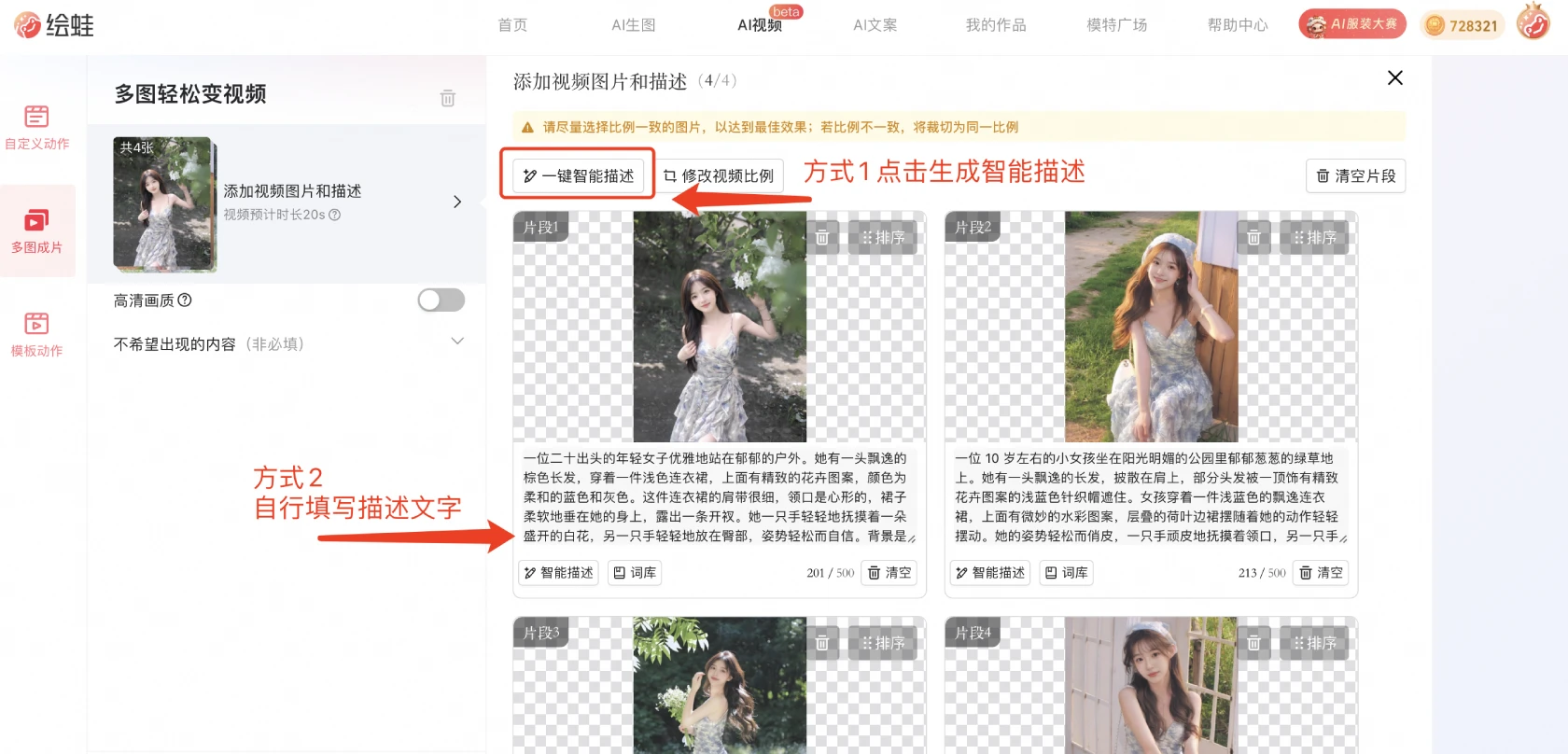
绘蛙AI多图成片 阿里巴巴推出的一款AI图生视频工具,只需上传2-4张连贯的图片并结合文字描述,就可快速生成一段流畅自然的视频。 Ai视频生成 2025年06月05日 48 点赞 0 评论 651 浏览
WebThinker WebThinker是一款由多家科研机构联合开发的AI工具,旨在增强大型推理模型在复杂任务中的表现。它支持自主搜索、网页导航与实时报告生成,结合深度网页探索器和强化学习策略,提升信息获取与内容创作的效率与质量。适用于科学研究、数据分析、教育辅助等多种场景,显著增强了模型在知识密集型任务中的可靠性与实用性。 AI项目与工具 2025年06月11日 60 点赞 0 评论 651 浏览
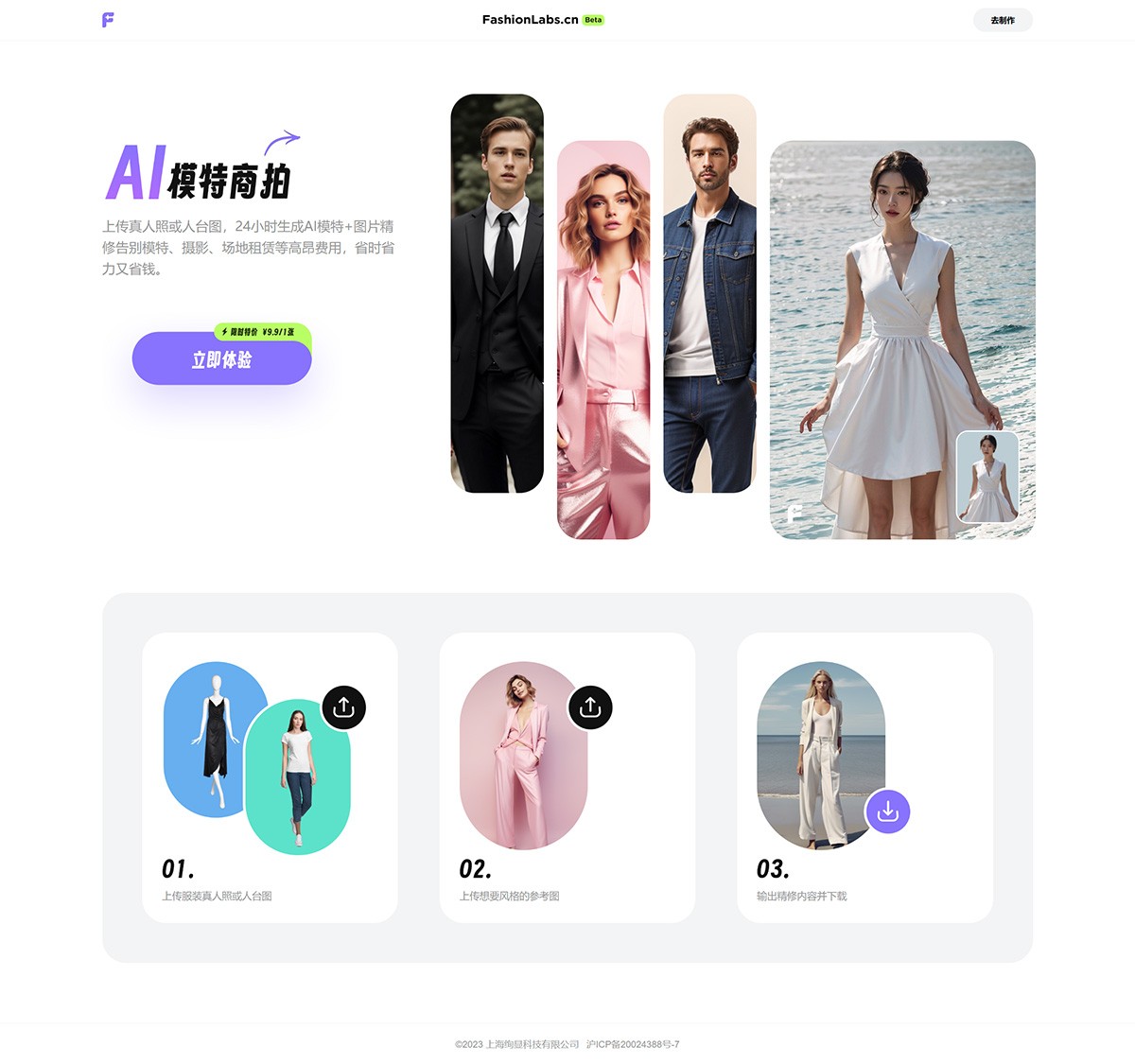
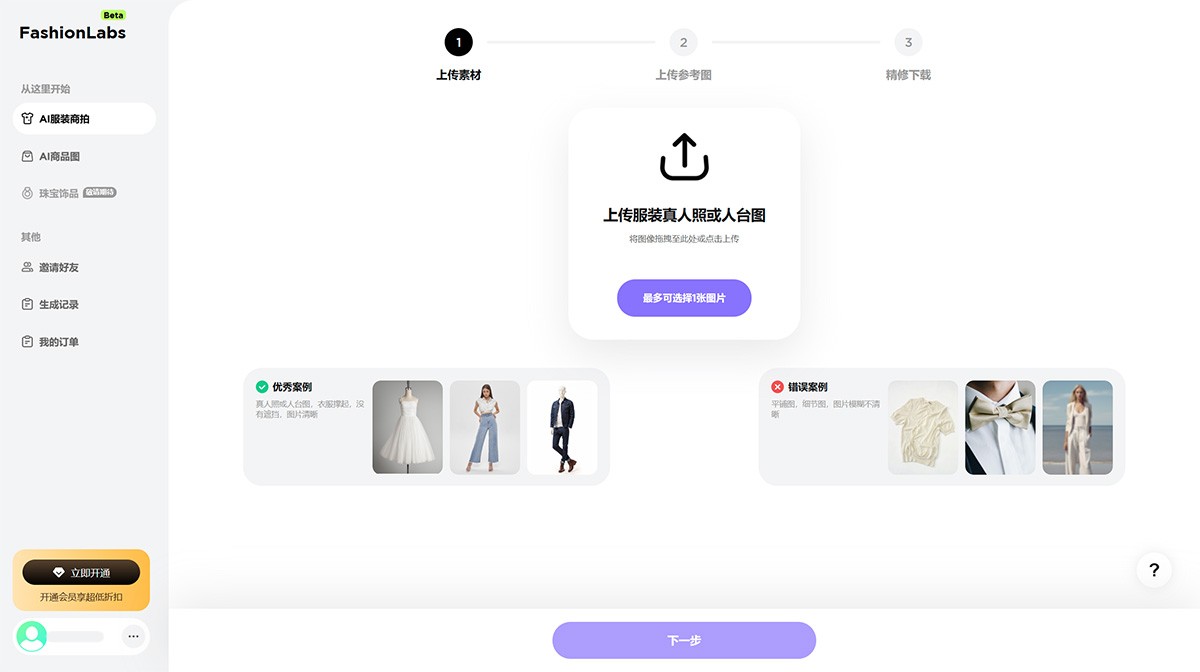
FashionLabs FashionLabs,AI服装模特商拍,为商家和品牌打造独特的AI商品图片,提供高品质的AI服装模特,为用户展现服装的魅力,提升品牌形象和销售。 Ai绘画生成 2025年06月05日 59 点赞 0 评论 651 浏览
Singify Fineshare Singify是一款在线AI歌曲翻唱生成工具,提供超过1000种声音模型,支持多种输入方式,如搜索、上传或录音,并允许用户调整音调、节奏等参数。其生成音乐免版税,适用于个人娱乐、社交媒体分享、音乐教学及广告制作等多个场景。平台界面友好,适合各类音乐创作者和爱好者使用。 AI项目与工具 2025年06月12日 67 点赞 0 评论 652 浏览
Mercury Coder Mercury Coder 是 Inception Labs 推出的扩散型大语言模型,专为代码生成设计。它采用“从粗到细”机制,支持并行生成,每秒可处理超过 1000 个 token,效率显著高于传统模型。具备代码生成、补全、优化、多语言支持及可控生成等功能,适用于开发效率提升、教育辅助、代码优化及低代码平台集成等场景。 AI项目与工具 2025年06月12日 24 点赞 0 评论 652 浏览
DistilQwen2.5 DistilQwen2.5-R1 是阿里巴巴推出的基于知识蒸馏技术的轻量级深度推理模型,包含多种参数量级,适用于资源受限环境。它具备高效计算、深度推理和高度适应性,支持文本生成、机器翻译、客户服务等多种任务。通过双阶段训练和认知轨迹适配框架,提升了小模型的推理能力,性能优于同类开源模型。 AI项目与工具 2025年06月12日 92 点赞 0 评论 652 浏览
Recraft ai Recraft 是一个强大的 AI 设计工具,它通过提供直观易用的功能,使用户能够快速从文本或视觉输入转化为复杂的设计作品。 创作工具 1970年01月01日 0 点赞 0 评论 652 浏览