KeySync KeySync是一种高分辨率口型同步工具,由帝国理工学院和弗罗茨瓦夫大学联合开发。其采用两阶段生成框架,结合掩码策略和视频分割模型,实现音频与唇部动作的精准对齐。支持高清视频生成,具备遮挡处理、减少表情泄露等功能,在视觉质量、时间连贯性和同步精度上优于现有方法,适用于自动配音、虚拟形象、视频会议等多场景应用。 AI项目与工具 2025年06月11日 32 点赞 0 评论 671 浏览
YOLOv9 YOLOv9是一款先进的目标检测系统,由台北中研院和台北科技大学的研究团队开发。该系统在YOLO算法系列基础上进行了优化,引入了可编程梯度信息(PGI)和泛化高效层聚合网络(GELAN),显著提升了模型的准确性、参数效率、计算复杂度和推理速度。YOLOv9在多个应用场景中表现出色,包括视频监控、自动驾驶、机器人视觉和野生动物监测。 AI项目与工具 2024年01月01日 91 点赞 0 评论 672 浏览
WorldCraft WorldCraft是一款基于大型语言模型的3D世界创建系统,支持用户通过自然语言交互快速生成和调整虚拟场景。其核心模块包括物体定制、场景布局优化和轨迹控制,具备高精度的几何与纹理控制能力。系统兼容多种3D生成工具,适用于建筑设计、影视娱乐、教育等多个领域,为非专业人士提供高效、直观的创意设计解决方案。 AI项目与工具 2025年06月12日 80 点赞 0 评论 672 浏览
NeMo NeMo 是一款基于 NVIDIA 技术的端到端云原生框架,专为生成式 AI 模型的设计与部署而打造。它具备模块化架构、多模态支持、优化算法及分布式训练能力,可应用于语音识别、自然语言处理、文本到语音转换、对话式 AI 等多个领域,同时支持预训练模型微调和端到端开发流程,为企业提供高效灵活的解决方案。 AI项目与工具 2025年06月12日 38 点赞 0 评论 674 浏览
Suno AI Suno AI 是由 Anthropic 公司开发的一款 AI 音乐和语音生成工具。 仅使用文本提示即可生成高质量的歌声、乐器和完整的音乐作品。 Ai语音工具 2025年06月05日 34 点赞 0 评论 677 浏览
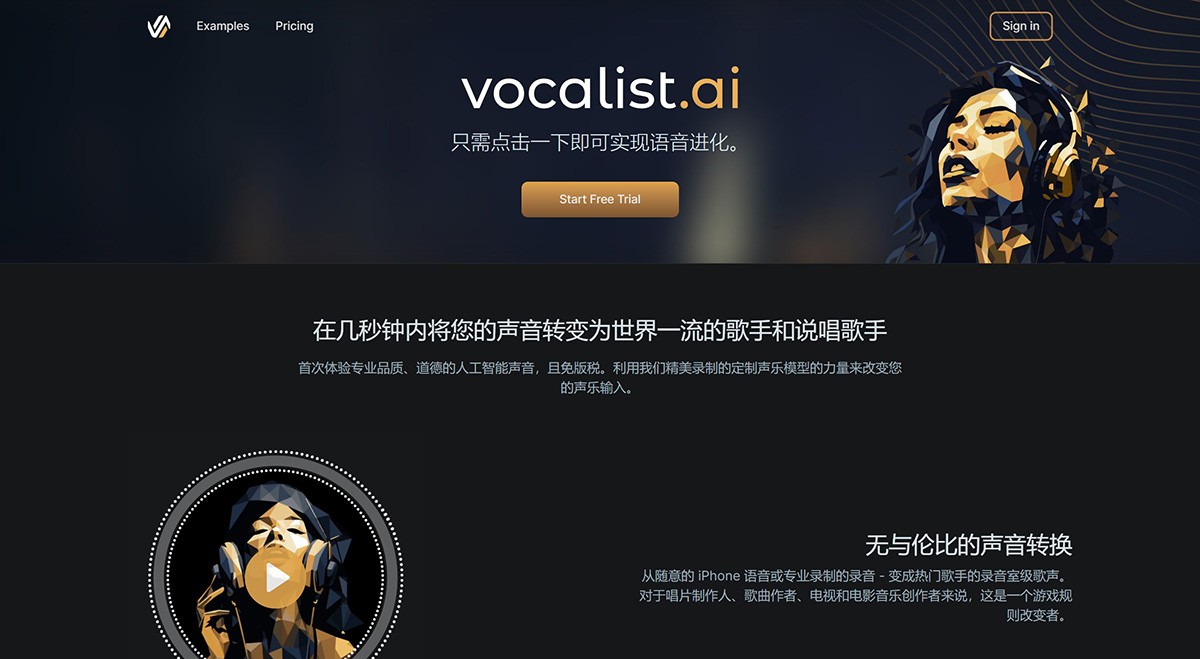
Vocalist.ai 一款可以使用定制的声乐模型将人声录音转换为专业品质的歌唱和说唱表演的录音室级AI声音转换工具,在几秒钟内将您的声音转变为世界一流的歌手和说唱歌手。 Ai语音工具 2025年06月05日 96 点赞 0 评论 678 浏览
DeepWiki DeepWiki是一款由Devin团队开发的AI代码阅读助手,基于自然语言处理技术,帮助用户理解GitHub代码库并提供详细的文档级解答。支持深度研究、交互式图表生成、私有仓库文档创建等功能,适用于开源项目学习、代码审查、团队协作及教育培训等场景。目前已索引超3万仓库,处理超40亿行代码,对开源项目免费开放。 AI项目与工具 2025年06月11日 36 点赞 0 评论 678 浏览
析易 析易是一款面向科研人员的智能平台,提供0代码数据分析、AI论文写作、文献解析、数据清洗与建模等功能,助力科研工作高效开展。平台涵盖医学、工学等多领域支持,适合高校和医院研究人员使用,简化科研流程,提升成果产出质量。 AI项目与工具 2025年03月27日 54 点赞 0 评论 678 浏览
Voice Voice-Pro是一款开源的多功能音频处理工具,集成了语音转文字、文本转语音、实时翻译、YouTube视频下载和人声分离等功能,支持超过100种语言,广泛应用于教育、娱乐和商业领域,显著提升音频处理效率和便捷性。 AI项目与工具 2025年06月12日 33 点赞 0 评论 679 浏览
QwQ QwQ-32B-Preview是一款由阿里巴巴开发的开源AI推理模型,具有325亿参数,擅长处理数学与编程领域的复杂任务。它能在多个基准测试中超越同类产品,并提供透明化的推理流程。然而,该模型在语言切换及跨领域应用上存在一定局限性。 AI项目与工具 2025年06月12日 99 点赞 0 评论 680 浏览