DeepSeek百宝箱 DeepSeek百宝箱是DeepSeek官方维护的GitHub项目,集成了多种支持DeepSeek API的工具和应用,涵盖聊天、知识管理、开发等多个领域。提供开箱即用、详实文档、本地化支持及多平台兼容性,助力开发者高效使用语言模型,提升工作效率。支持模型训练、部署、监控全流程,具备低代码配置、智能上下文感知、毫秒级响应等特性,适用于办公、编程、内容创作等多种场景。 AI项目与工具 2025年06月12日 45 点赞 0 评论 946 浏览
VRAG VRAG-RL是阿里巴巴通义大模型团队推出的视觉感知驱动的多模态RAG推理框架,旨在提升视觉语言模型在处理视觉丰富信息时的检索、推理和理解能力。通过定义视觉感知动作空间,实现从粗粒度到细粒度的信息获取,并结合强化学习和综合奖励机制优化模型性能。该框架支持多轮交互推理,具备良好的可扩展性,适用于智能文档问答、视觉信息检索、多模态内容生成等多种场景。 AI项目与工具 2025年06月11日 84 点赞 0 评论 946 浏览
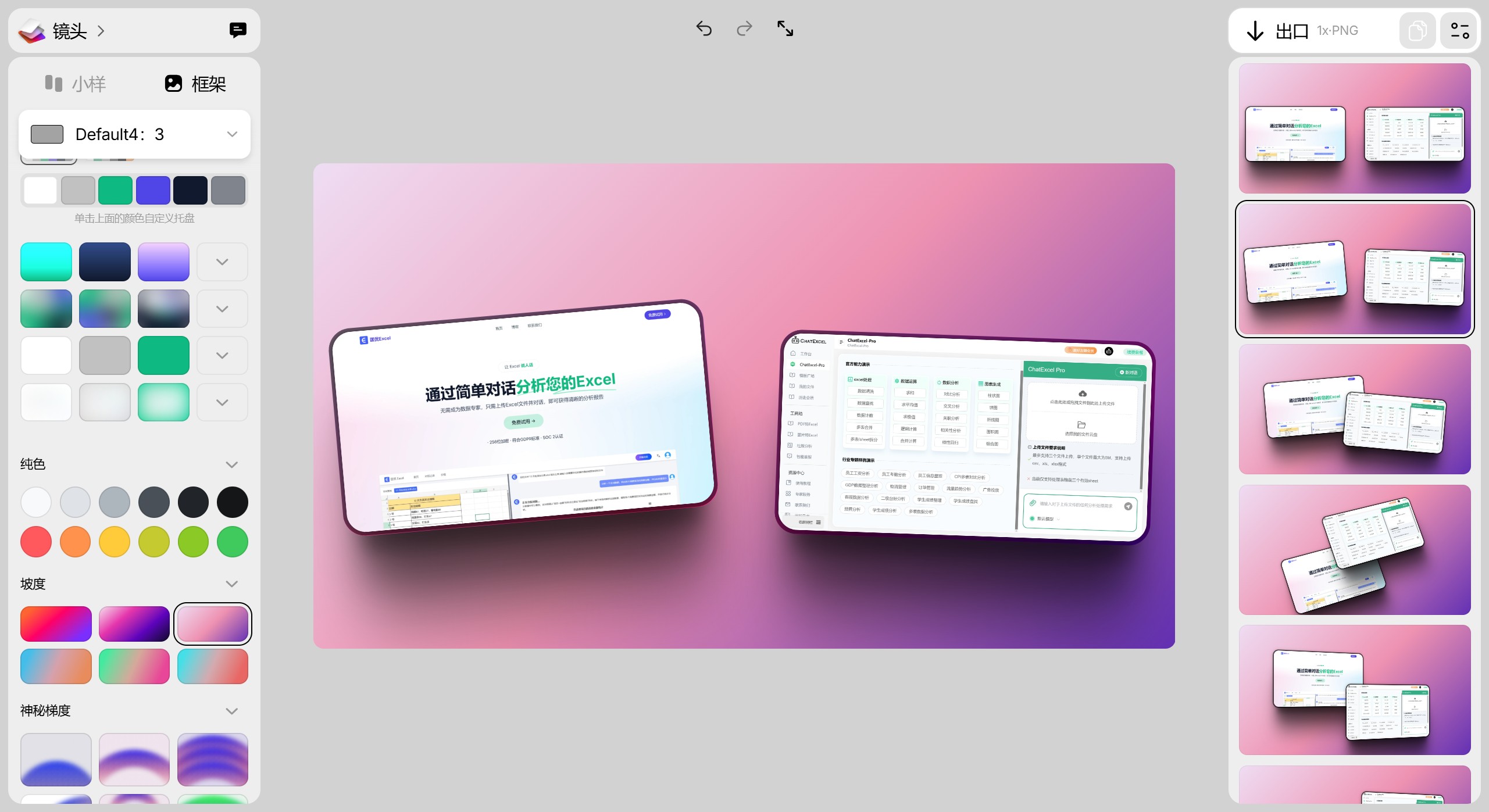
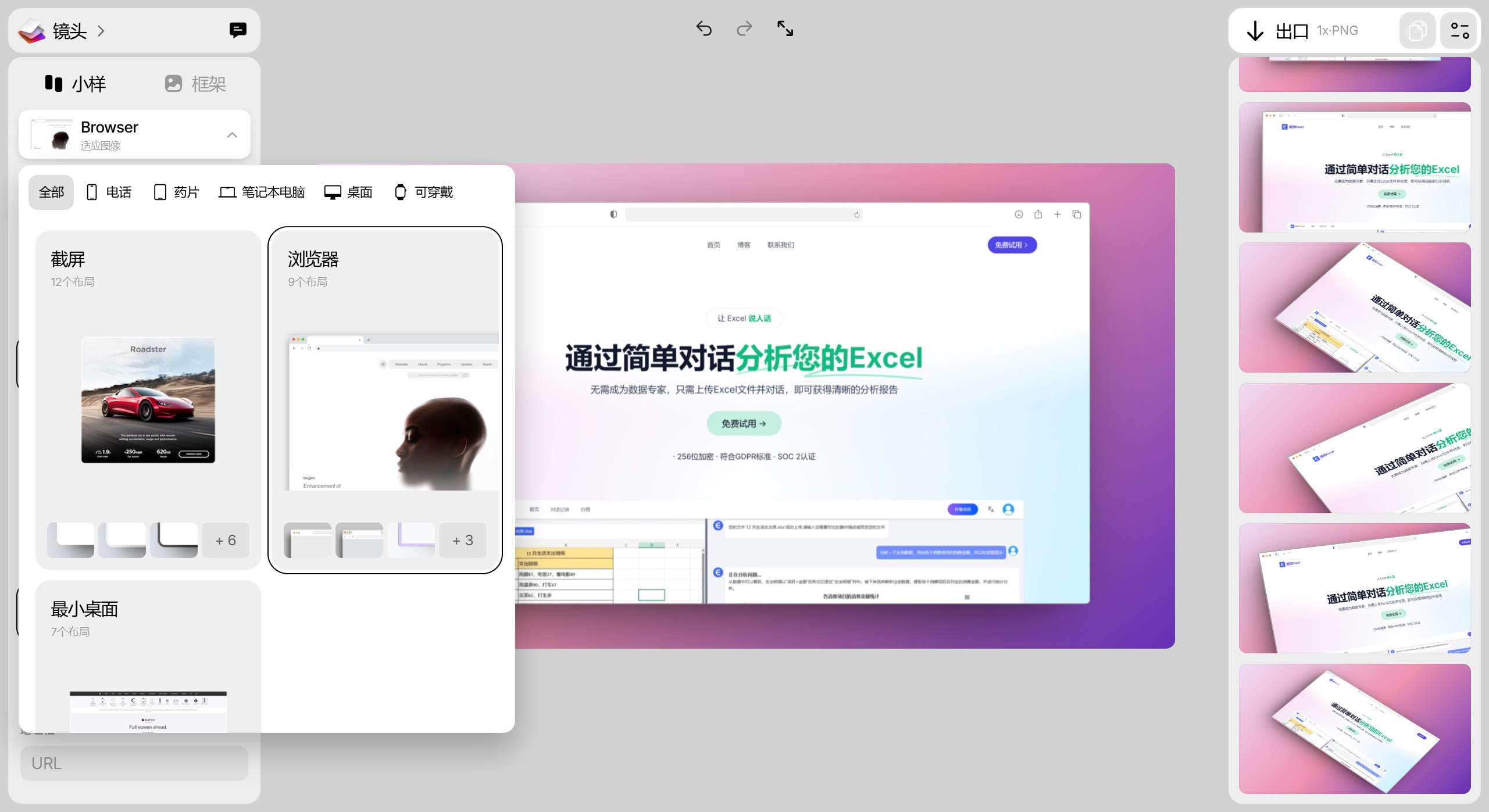
Shots.So 一个免费的在线工具,只需点击几下即可帮助您创建漂亮的样机模型。 Shots.so可以与背景框架和不同的模型(如浏览器、手机、笔记本电脑、手表等)产生很好的效果。 图片处理 2025年06月05日 26 点赞 0 评论 947 浏览
Goku Goku是由香港大学与字节跳动联合开发的AI视频生成模型,支持文本到图像、文本到视频、图像到视频等多种生成方式。其核心优势在于高质量的视频输出、低制作成本及多模态生成能力。Goku+作为扩展版本,专注于广告视频创作,具备稳定的动作表现和丰富的表情交互。模型基于大规模数据集和先进架构,适用于广告、教育、娱乐等多个领域,提升了内容创作效率与质量。 AI项目与工具 2025年02月11日 29 点赞 0 评论 948 浏览
Skywork Skywork-Reward 是昆仑万维推出的一系列高性能奖励模型,包括 Skywork-Reward-Gemma-2-27B 和 Skywork-Reward-Llama-3.1-8B,主要用于优化大语言模型的训练过程。这些模型通过提供奖励信号,帮助模型理解和生成符合人类偏好的内容。Skywork-Reward 在对话、安全性和推理任务中表现出色,并且在 RewardBench 评估基准上名列前 AI项目与工具 2025年06月12日 32 点赞 0 评论 949 浏览
MoE++ MoE++是一种基于混合专家架构的新型深度学习框架,通过引入零计算量专家、复制专家和常数专家,有效降低计算成本并提升模型性能。它支持Token动态选择FFN专家,并利用门控残差机制实现稳定路由,同时优化计算资源分配。该框架易于部署,适用于多种应用场景,包括自然语言处理、智能客服及学术研究。 AI项目与工具 2025年06月12日 40 点赞 0 评论 949 浏览
京言AI助手 京东京言AI助手,一款AI智能导购助手,可以为用户提供专业品类咨询、个性化送礼助手、产品对比助手和购物经验知识的功能。 电商运营 2025年06月05日 76 点赞 0 评论 950 浏览
OmniVision OmniVision是一款面向边缘设备的紧凑型多模态AI模型,参数量为968M。它基于LLaVA架构优化,能够处理视觉与文本输入,显著降低计算延迟和成本。OmniVision支持视觉问答、图像描述等功能,广泛应用于内容审核、智能助手、视觉搜索等领域。 AI项目与工具 2025年06月12日 37 点赞 0 评论 950 浏览
TIGER TIGER是由清华大学研发的轻量级语音分离模型,采用时频交叉建模策略与多尺度注意力机制,有效提升语音分离性能,同时显著降低计算和参数开销。模型通过频带切分优化资源利用,适应复杂声学环境,广泛应用于会议记录、视频剪辑、电影音频处理及智能语音助手等领域。 AI项目与工具 2025年06月12日 98 点赞 0 评论 950 浏览
rStar rStar-Math是由微软亚洲研究院研发的数学推理工具,采用蒙特卡洛树搜索(MCTS)驱动的深度思考机制,使小型语言模型在数学推理方面达到或超越大型模型水平。通过代码增强的推理轨迹生成、过程偏好模型(PPM)训练和四轮自我进化策略,显著提升了模型的准确率与自我反思能力。该工具已在多个数学基准测试中取得优异成绩,适用于教育、科研、金融、工程和数据分析等多个领域。 AI项目与工具 2025年06月12日 60 点赞 0 评论 951 浏览