ID ID-Animator是一款由腾讯光子工作室、中科大和中科院合肥物质科学研究院联合开发的零样本人类视频生成技术。它能够根据单张参考面部图像生成个性化视频,并根据文本提示调整视频内容。ID-Animator通过结合预训练的文本到视频扩散模型和轻量级面部适配器,实现高效的身份保真视频生成。其主要功能包括视频角色修改、年龄和性别调整、身份混合以及与ControlNet等现有条件模块的兼容性。 AI项目与工具 2024年01月01日 67 点赞 0 评论 691 浏览
Vace AI Vace AI 是一款集成视频生成与编辑功能的 AI 工具,支持文本到视频、参考图像生成视频等功能,并提供风格转换、主体移除、画面扩展等编辑选项。基于先进模型技术,可精准保留关键视觉元素,生成高质量视频,适用于短视频制作、创意内容生成及广告设计等多种场景。 AI项目与工具 2025年06月12日 92 点赞 0 评论 698 浏览
Phantom Phantom是由字节跳动研发的视频生成框架,支持从参考图像中提取主体并生成符合文本描述的视频内容。它采用跨模态对齐技术,结合文本和图像提示,实现高质量、主体一致的视频生成。支持多主体交互、身份保留等功能,适用于虚拟试穿、数字人生成、广告制作等多种场景。模型基于文本-图像-视频三元组数据训练,具备强大的跨模态理解和生成能力。 AI项目与工具 2025年06月12日 72 点赞 0 评论 701 浏览
腾讯混元文生视频 腾讯混元文生视频是一款利用AI技术生成高质量视频内容的工具,可根据文本提示生成具有大片质感的视频。它支持多语言输入,涵盖高清画质、流畅镜头切换及自然场景模拟等功能,适用于电影制作、广告设计、教育培训等多种应用场景。 AI项目与工具 2025年06月12日 22 点赞 0 评论 717 浏览
ConsisID ConsisID是一款由北京大学和鹏城实验室开发的文本到视频生成工具,其核心技术在于通过频率分解保持视频中人物身份的一致性。该模型具备高质量视频生成能力、无需微调的特点以及强大的可编辑性,同时拥有优秀的泛化性能。其主要功能包括身份保持、高质量视频生成、文本驱动编辑以及跨领域人物处理,广泛应用于个性化娱乐、虚拟主播、影视制作、游戏开发及教育模拟等领域。 AI项目与工具 2025年06月12日 18 点赞 0 评论 728 浏览
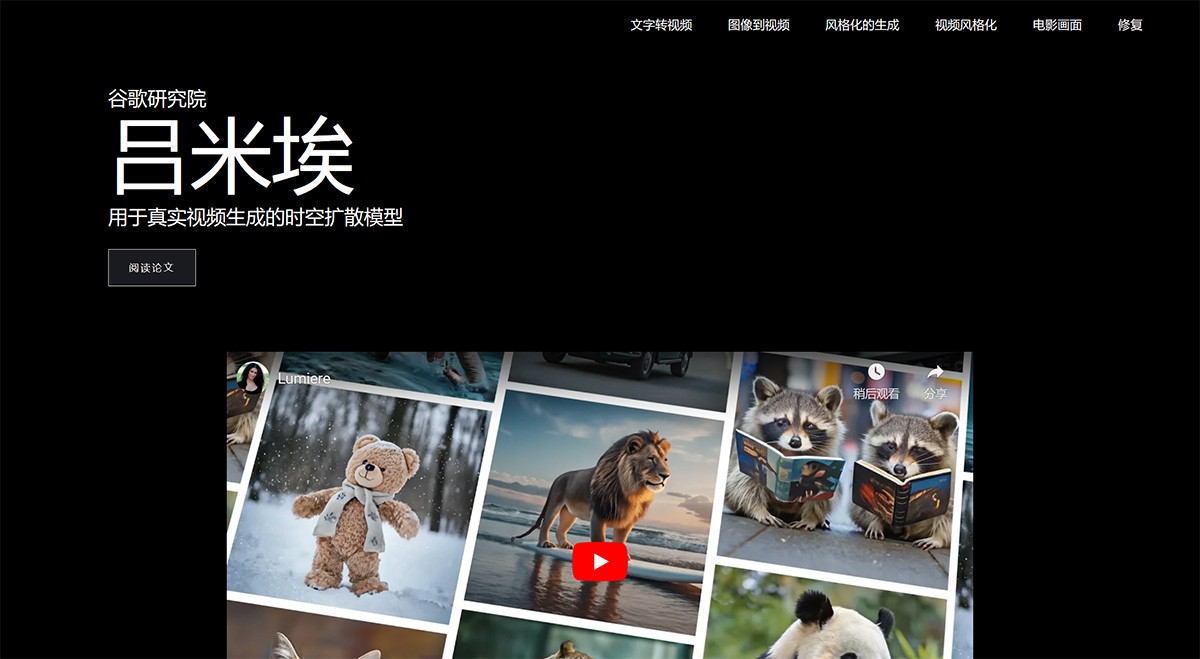
Lumiere 谷歌研究院开发的基于空间时间的文本到视频扩散模型。采用了创新的空间时间U-Net架构,能够一次性生成整个视频的时间长度,确保了生成视频的连贯性和逼真度。 Ai开源项目 2025年06月05日 74 点赞 0 评论 732 浏览
Mora Mora是一个多智能体框架,专为视频生成任务设计,通过多个视觉智能体的协作实现高质量视频内容的生成。主要功能包括文本到视频生成、图像到视频生成、视频扩展与编辑、视频到视频编辑以及视频连接。尽管在处理大量物体运动场景时性能稍逊于Sora,Mora仍能在生成高分辨率视频方面表现出色。 AI项目与工具 2024年01月01日 75 点赞 0 评论 740 浏览
CogVideo 目前最大的通用领域文本生成视频预训练模型,含94亿参数。CogVideo将预训练文本到图像生成模型(CogView2)有效地利用到文本到视频生成模型,并使用了多帧率分层训练策略。 Ai平台模型 2025年06月05日 16 点赞 0 评论 740 浏览
Genmoai Genmoai-smol 是一款专为单 GPU 设备设计的开源视频生成模型,能够将文本描述转化为高质量视频内容。其核心优势在于高保真度运动表现、强大的文本提示遵循能力及显存优化技术,支持用户在资源受限条件下开展视频创作。该工具提供了 Gradio UI 和命令行界面两种操作方式,并广泛应用于视频内容创作、超现实效果视频制作和技术研究等领域。 AI项目与工具 2025年06月12日 26 点赞 0 评论 746 浏览