扩散模型



谷歌DeepMind推出V2A技术,可为无声视频添加逼真音效
DeepMind推出的V2A(Video-to-Audio)模型能够将视频内容与文本提示相结合,生成包含对话、音效和音乐的详细音频轨道。它不仅能够与DeepMind自身的视频生成模型Veo协同工作,还能与其他视频生成模型,如Sora、可灵或Gen 3等,进行集成,从而为视频添加戏剧性的音乐、逼真的音效或与视频中角色和情绪相匹配的对话。V2A的强大之处在于其能够为每个视频输入生成无限数量的音轨。该模



FramePainter
FramePainter 是一款基于AI的交互式图像编辑工具,结合视频扩散模型与草图控制技术,支持用户通过简单操作实现精准图像修改。其核心优势包括高效训练机制、强泛化能力及高质量输出。适用于概念艺术、产品展示、社交媒体内容创作等场景,具备低训练成本和自然的图像变换能力。

MakeAnything
MakeAnything是由新加坡国立大学Show Lab团队开发的多领域程序性序列生成框架,能够根据文本或图像生成高质量的分步教程。它采用扩散变换器和ReCraft模型,支持从文本到过程和从图像到过程的双向生成。覆盖21个领域,包含超24,000个标注序列,具备良好的逻辑连贯性和视觉一致性,适用于教育、艺术、工艺传承及内容创作等多种场景。
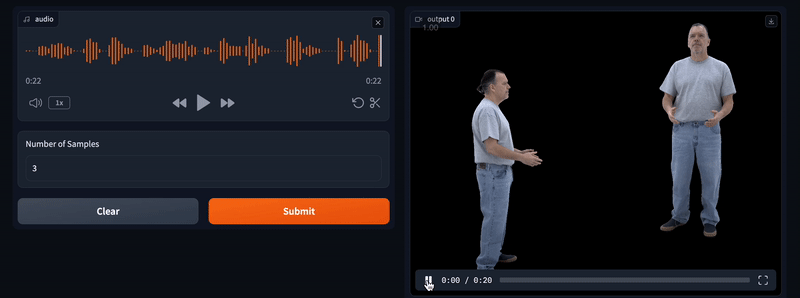

VideoCrafter2
VideoCrafter2 是一款由腾讯AI实验室开发的视频生成模型,通过将视频生成过程分解为运动和外观两个部分,能够在缺乏高质量视频数据的情况下,利用低质量视频保持运动的一致性,同时使用高质量图像提升视觉质量。该工具支持文本到视频的转换,生成高质量、具有美学效果的视频,能够理解和组合复杂的概念,并模拟不同的艺术风格。

DynamicFace
DynamicFace是由小红书团队开发的视频换脸技术,结合扩散模型与时间注意力机制,基于3D面部先验知识实现高质量、一致性的换脸效果。通过四种精细的面部条件分解和身份注入模块,确保换脸后的人脸在不同表情和姿态下保持一致性。该技术适用于视频与图像换脸,广泛应用于影视制作、虚拟现实、社交媒体等内容创作领域,具备高分辨率生成能力和良好的时间连贯性。
