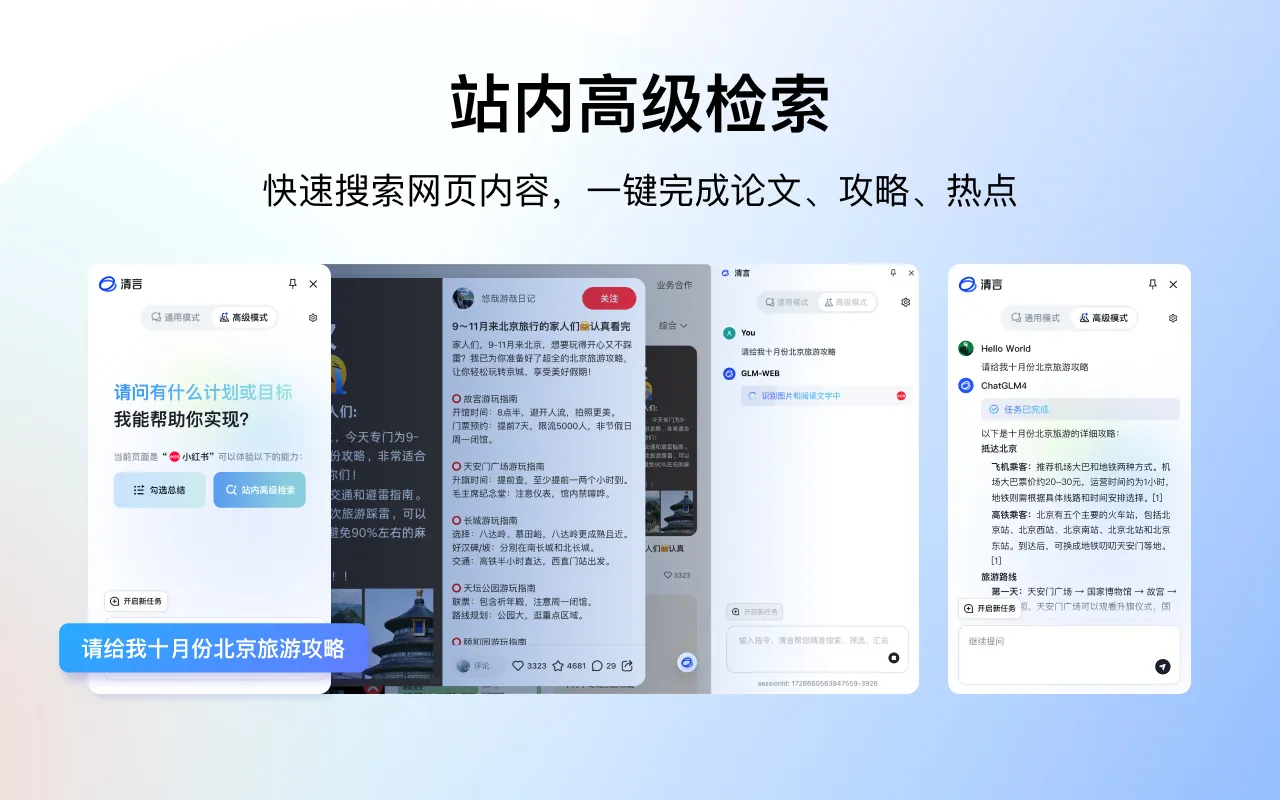
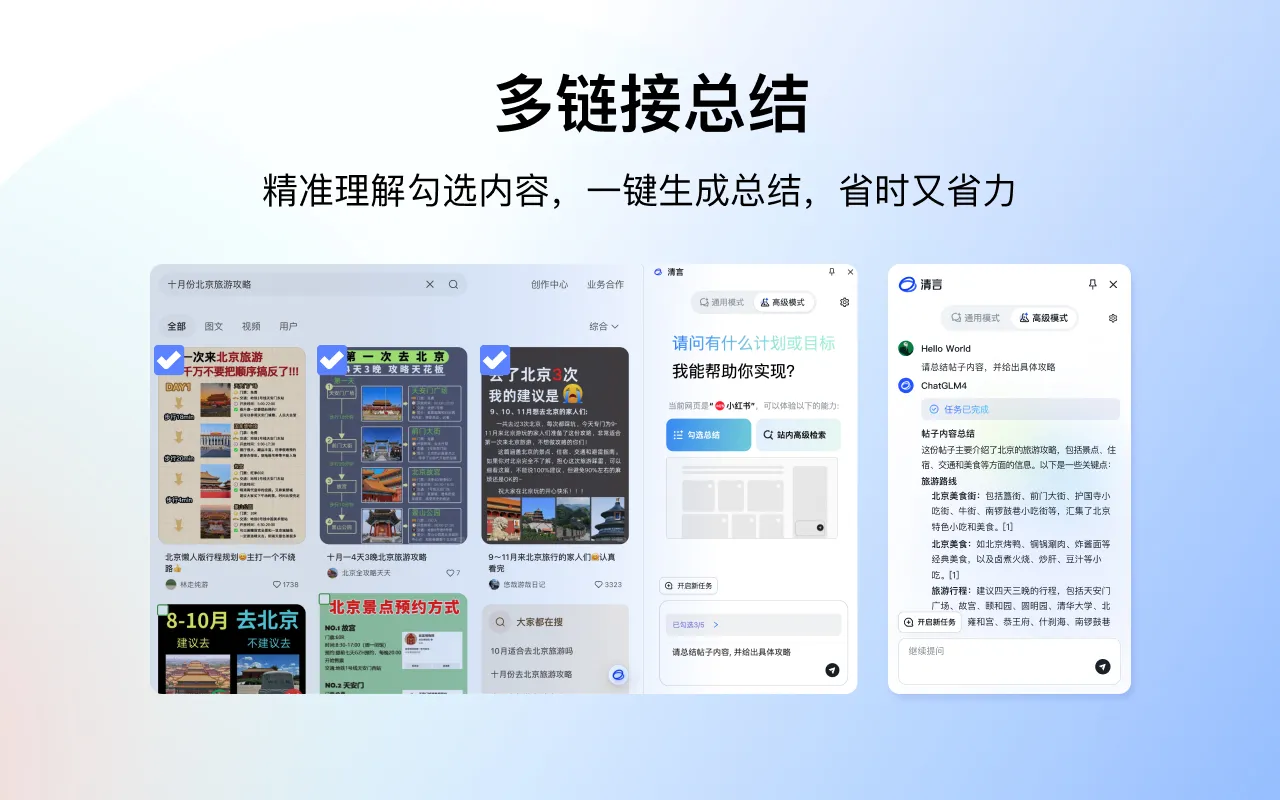
多模态



Finedefics
Finedefics是由北京大学彭宇新教授团队开发的细粒度多模态大模型,专注于提升多模态大语言模型在细粒度视觉识别任务中的表现。该模型通过引入对象的细粒度属性描述,结合对比学习方法,实现视觉对象与类别名称的精准对齐。在多个权威数据集上表现出色,准确率达76.84%。其应用场景涵盖生物多样性监测、智能交通、零售管理及工业检测等领域。

Gemini 2.0 Flash
Gemini 2.0 Flash是Google推出的多模态AI模型,支持文本与图像生成及对话式编辑,能根据自然语言生成连贯图像,并保持上下文一致性。其在长文本渲染方面表现优异,适用于广告、社交媒体、教育等领域。开发者可通过Google AI Studio或Gemini API进行测试和集成,广泛应用于创意插图、互动故事、设计辅助等场景。





Learn About
Learn About是一款由谷歌开发的对话式AI学习助手,基于Gemini模型,通过问答形式为用户提供简明答案并引导深入学习。它具备知识点梳理、参考资料推荐、内容大纲生成等功能,覆盖多学科领域,支持多模态学习资源,旨在提升用户的理解深度和学习效率。适合学术研究、备考复习、技能学习、家庭教育及终身学习等多种应用场景。