GroundingBooth GroundingBooth 是一种创新的文本到图像定制框架,通过结合文本-图像对齐模块和遮罩交叉注意力层,实现了前景主体与背景对象的空间精准对齐。其核心功能包括单主题与多主题定制、身份保留、文本-图像一致性保障及复杂场景下的高精度生成。该工具广泛应用于个性化商品定制、艺术创作、游戏设计、广告营销等多个领域,为视觉内容创作提供了强大的技术支持。 AI项目与工具 2025年06月12日 20 点赞 0 评论 513 浏览
Upscayl Upscayl 是一款效果非常出众的图片放大变清晰图片处理软件,通过使用高级的 AI 模型来升级低分辨率图像,使得模糊的图片即使放大也同样清晰。 Ai图片处理 2025年06月05日 97 点赞 0 评论 513 浏览
AI Ease AI Ease是一款基于人工智能的在线照片编辑工具,提供背景移除、水印消除、图像生成、艺术风格转换、肖像美化等多种功能。支持移动设备使用,操作简便,适用于电商、社交媒体、个人美化及创意设计等场景。提供免费与专业订阅方案,保障用户数据安全。 AI项目与工具 2025年06月11日 44 点赞 0 评论 513 浏览
MIP MIP-Adapter是一种基于IP-Adapter模型开发的个性化图像生成技术,能够高效处理多参考图像并生成高质量的定制化图像。通过解耦交叉注意力机制和加权合并方法,解决了多图像输入中的对象混淆问题,提升了生成图像的质量。该技术无需测试时微调,具有高效训练的特点,广泛应用于社交媒体、广告、游戏设计等多个领域。 AI项目与工具 2025年06月12日 80 点赞 0 评论 512 浏览
HART HART是一种由麻省理工学院研究团队开发的自回归视觉生成模型,能够生成1024×1024像素的高分辨率图像,质量媲美扩散模型。通过混合Tokenizer技术和轻量级残差扩散模块,HART实现了高效的图像生成,并在多个指标上表现出色,包括重构FID、生成FID以及计算效率。 AI项目与工具 2025年06月12日 93 点赞 0 评论 512 浏览
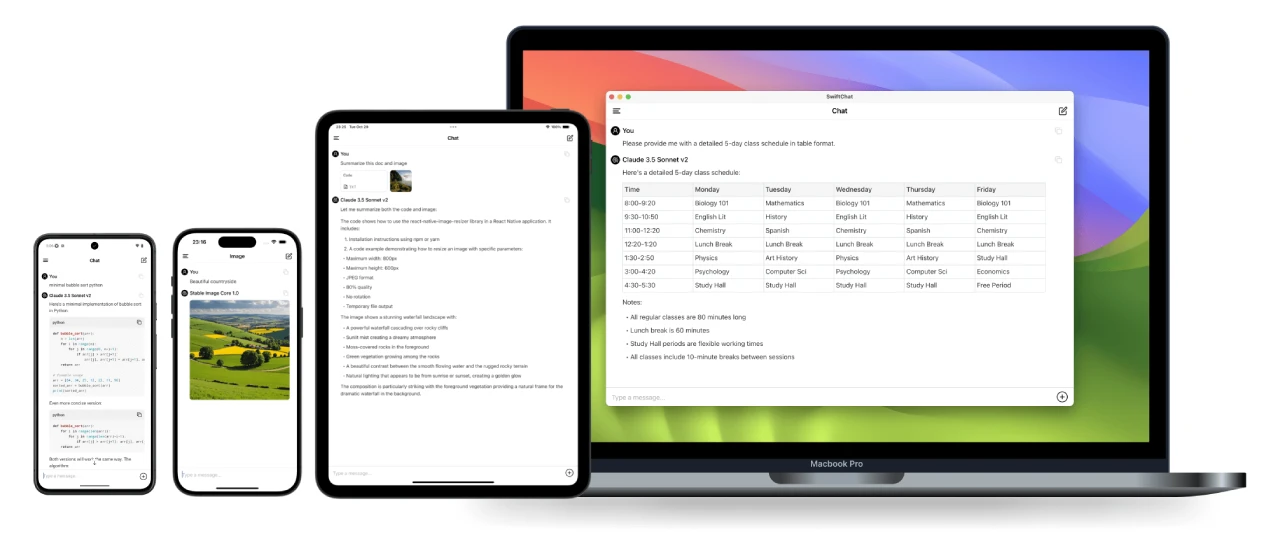
SwiftChat 一款基于React Native开发的快速、安全、跨平台聊天应用,支持实时流式聊天功能和Markdown语法,还可以生成AI图像,兼容DeepSeek、Amazon Bedrock、Ollama和OpenAI等模型。 Ai开源项目 2025年06月05日 44 点赞 0 评论 511 浏览
Remaker AI 一款AI图像生成器、AI换脸器和AI图像编辑器。能让用户能够无缝替换图像和视频中的脸部,除此之外,Remaker AI 还拥有对象移除器、图像放大器和各种其他AI工具。 Ai图片处理 2025年06月05日 19 点赞 0 评论 511 浏览