Project DIGITS Project DIGITS 是 NVIDIA 推出的高性能 AI 计算设备,基于 Grace Blackwell 架构,配备 GB10 Superchip,提供高达 1 万万亿次的 AI 计算能力,支持运行 2000 亿参数的大模型。其具备 128GB 统一内存和 4TB NVMe 存储,支持本地开发与云端部署,适配多种 AI 应用场景,如研究、数据分析、教育及医疗等。 AI项目与工具 2025年06月12日 52 点赞 0 评论 585 浏览
FlashMLA FlashMLA 是 DeepSeek 开发的开源 MLA 解码内核,针对 NVIDIA Hopper 架构 GPU 优化,提升可变长度序列处理效率。支持 BF16 精度、页式 KV 缓存及分块调度,内存带宽达 3000 GB/s,算力达 580 TFLOPS。适用于大语言模型推理和 NLP 任务,具备高性能与低延迟特性,支持快速部署与性能验证。 AI项目与工具 2025年06月12日 12 点赞 0 评论 634 浏览
DeepEP DeepEP 是 DeepSeek 开发的开源 EP 通信库,专为混合专家模型(MoE)的训练和推理设计。它提供高吞吐、低延迟的 GPU 内核,支持 NVLink 和 RDMA 通信,优化了组限制门控算法,兼容 FP8 等低精度数据格式。适用于大规模模型训练、推理解码及高性能计算场景,具有良好的系统兼容性和网络优化能力。 AI项目与工具 2025年06月12日 43 点赞 0 评论 754 浏览
DeepGEMM DeepGEMM是DeepSeek开发的高效FP8矩阵乘法库,专为NVIDIA Hopper架构优化,支持普通与分组GEMM操作。采用即时编译技术,实现运行时动态优化,提升计算性能与精度。通过细粒度缩放和双级累加技术解决FP8精度问题,结合TMA特性提升数据传输效率。代码简洁,仅约300行,适用于大规模AI推理、MoE模型优化及高性能计算场景。 AI项目与工具 2025年06月12日 61 点赞 0 评论 781 浏览
3FS 3FS是DeepSeek推出的高性能分布式文件系统,专为AI训练和推理优化。采用SSD与RDMA技术,提供高达6.6 TiB/s的读取吞吐量,支持强一致性及通用文件接口。具备数据准备、加载、检查点和KVCache缓存功能,适用于大规模AI应用。在GraySort测试中表现优异,吞吐量达3.66 TiB/min,KVCache读取峰值达40 GiB/s,适用于多节点计算环境。 AI项目与工具 2025年06月12日 74 点赞 0 评论 706 浏览
Smallpond Smallpond是DeepSeek推出的轻量级数据处理框架,基于DuckDB和3FS构建,支持PB级数据的高效处理。具备高性能、易用性、快速上手和分布式处理能力,适用于大规模数据预处理、实时查询、机器学习训练等场景。 AI项目与工具 2025年06月12日 40 点赞 0 评论 679 浏览
赤兔Chitu Chitu(赤兔)是清华大学与清程极智联合开发的高性能大模型推理引擎,支持多种GPU及国产芯片,打破对特定硬件的依赖。其具备全场景部署能力,支持低延迟、高吞吐、小显存优化,并在性能上优于部分国外框架。适用于金融风控、智能客服、医疗诊断、交通优化和科研等领域,提供高效、稳定的推理解决方案。 AI项目与工具 2025年06月12日 25 点赞 0 评论 552 浏览
RightNow AI RightNow AI 是一款专注于 CUDA 代码优化的 AI 工具,能够自动分析并提升 GPU 性能。它支持多种 NVIDIA GPU 架构,提供无服务器的性能分析服务,并允许用户通过自然语言指令生成高性能代码。适用于模型训练、科学计算、金融建模等多个领域,显著降低 GPU 编程门槛,提升计算效率。 AI项目与工具 2025年06月11日 46 点赞 0 评论 468 浏览
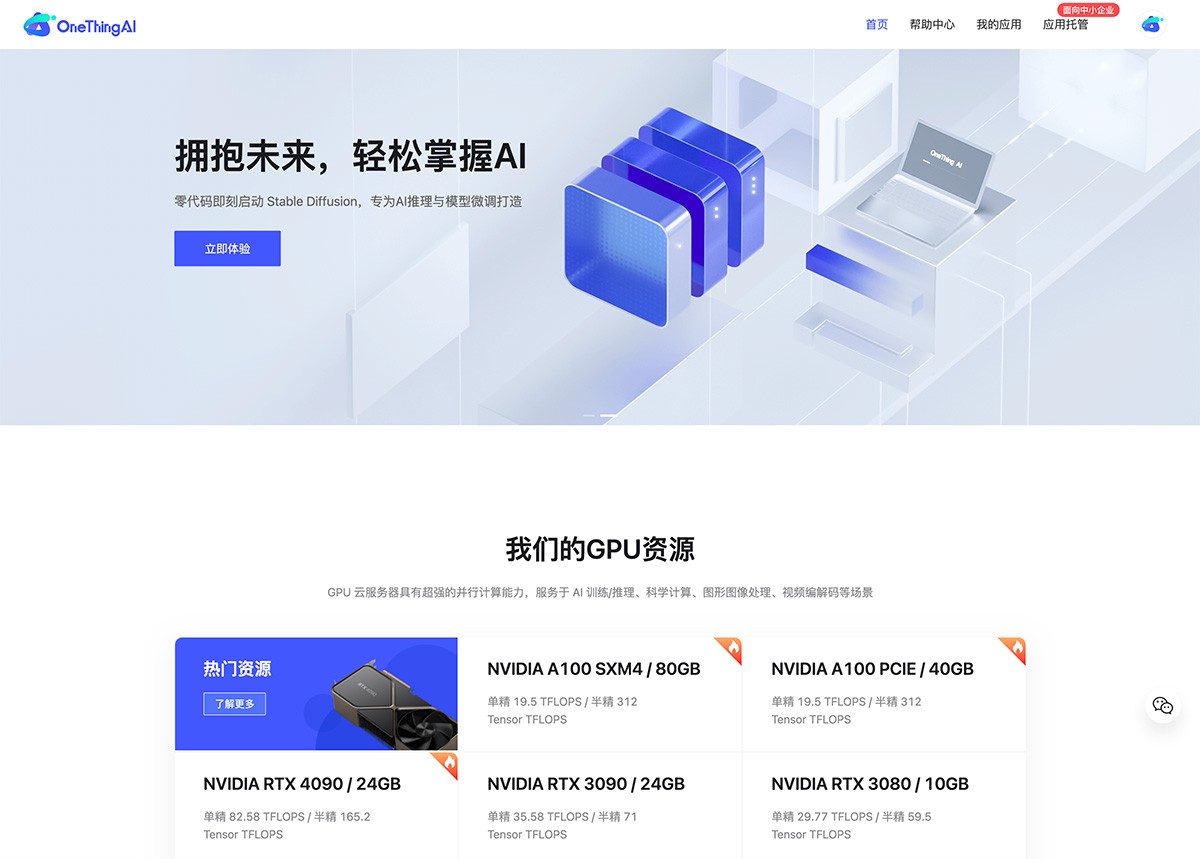
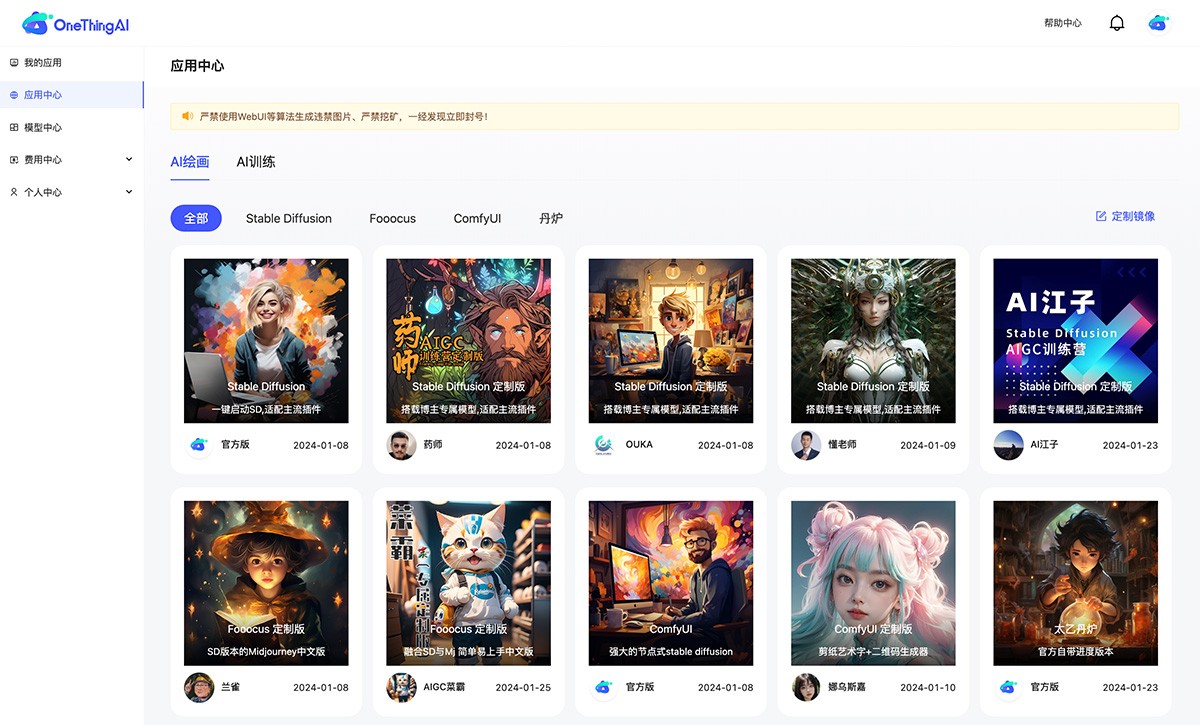
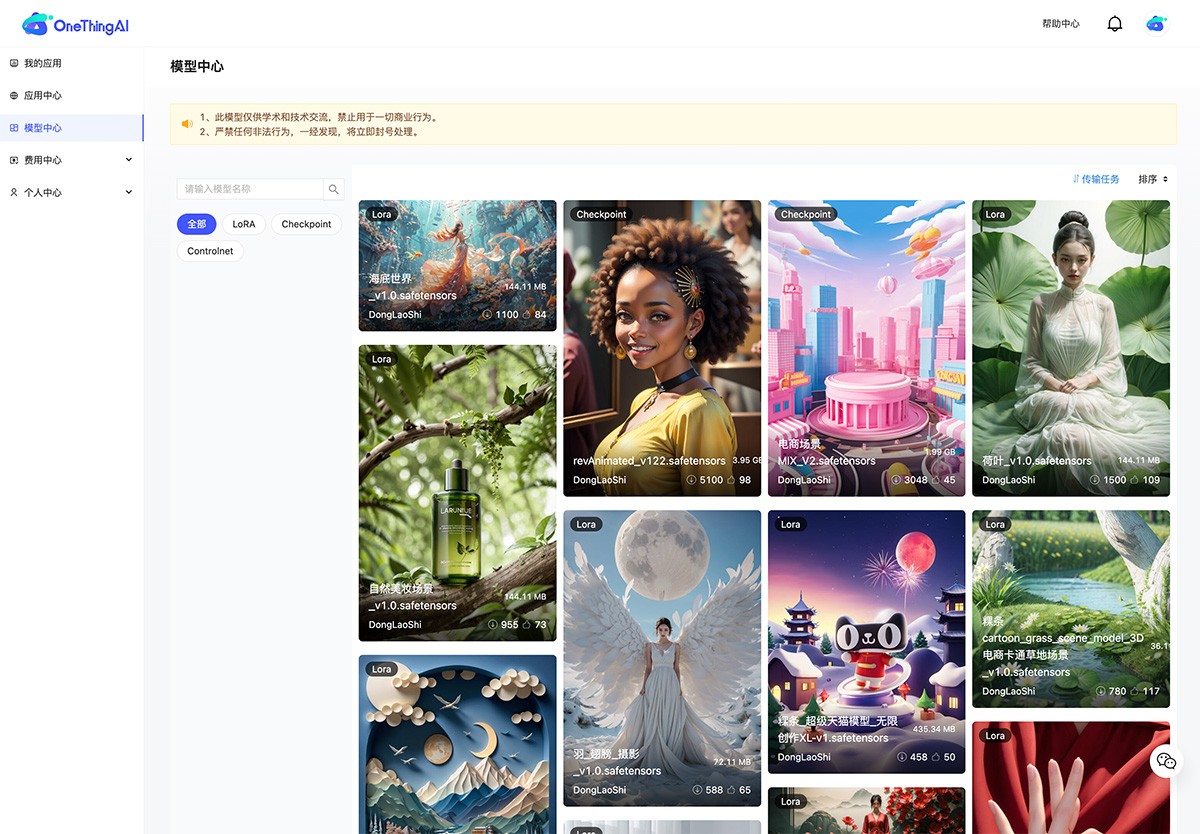
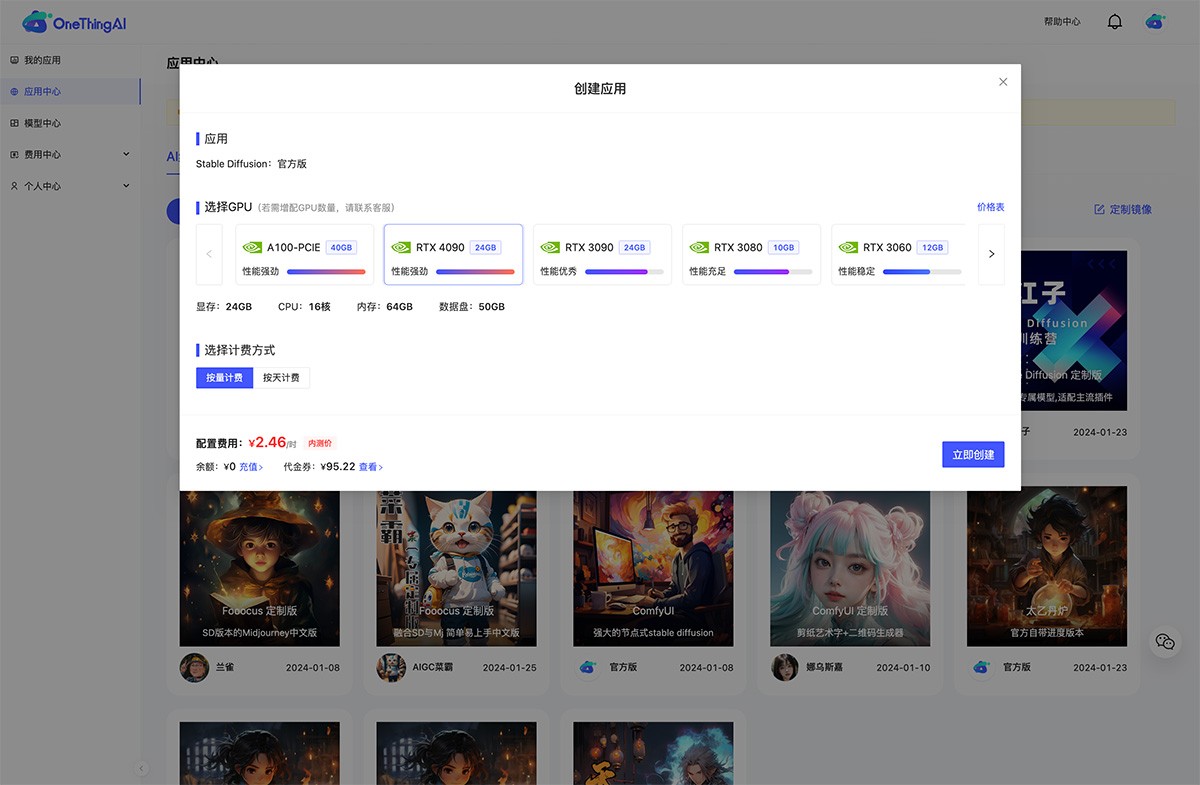
OneThingAI 面向丰富的业务场景,提供一站式、全方位的云服务解决方案。服务于AI 训练/推理、科学计算、图形图像处理、视频编解码等场景, AI服务商 2025年06月05日 66 点赞 0 评论 412 浏览