语音识别



Subtitle Edit
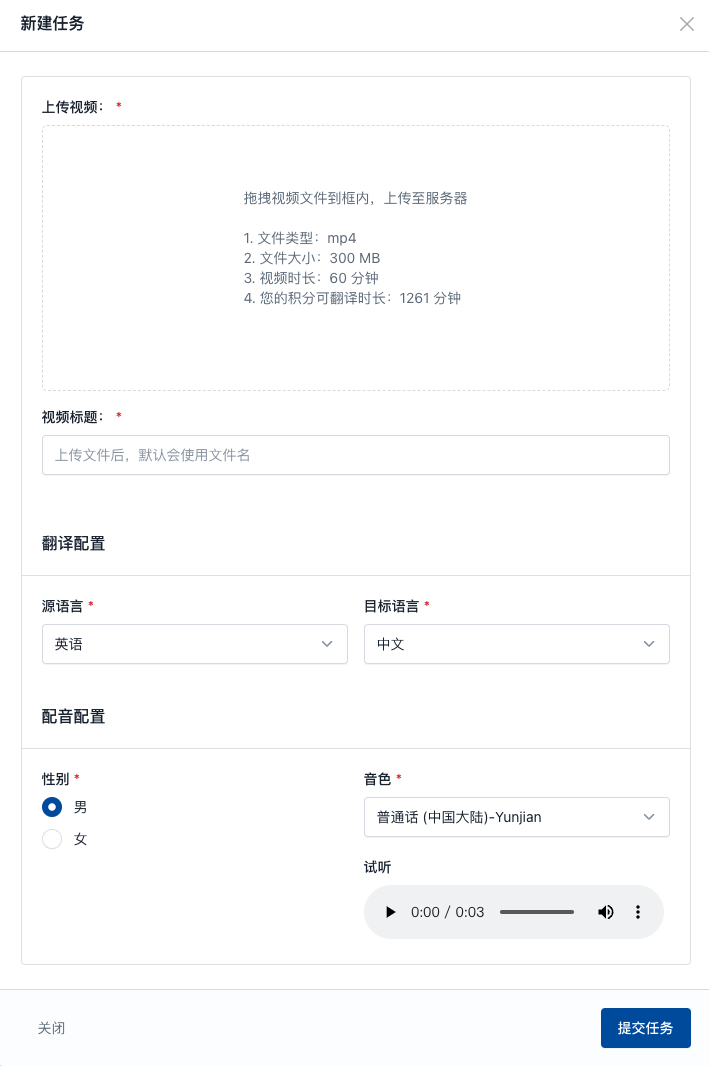
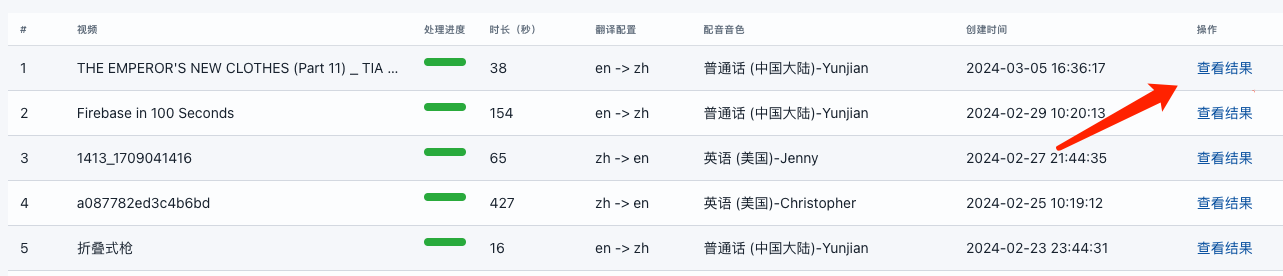
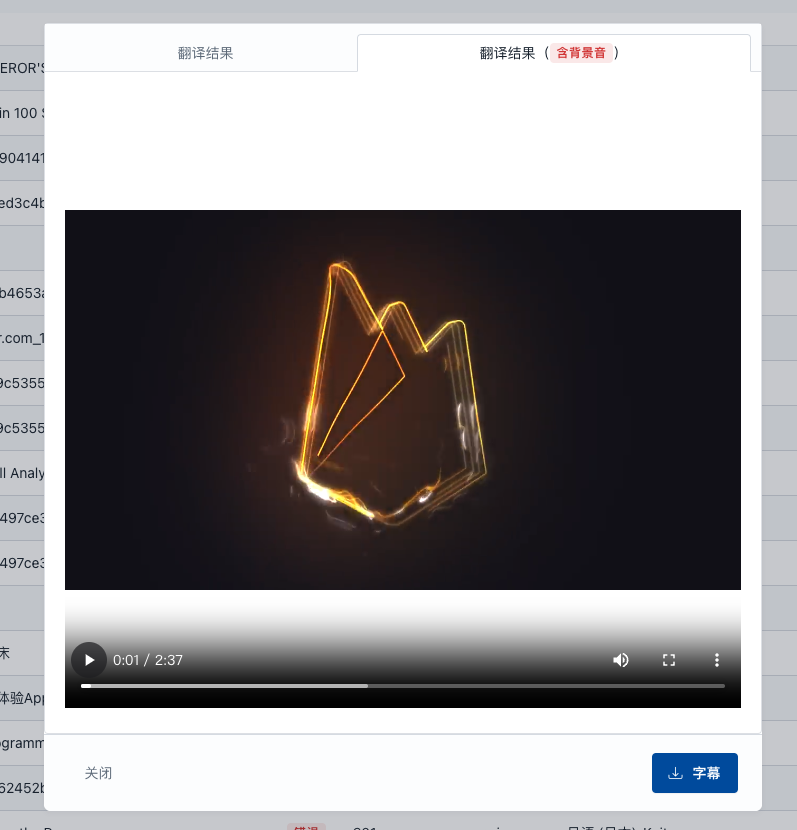
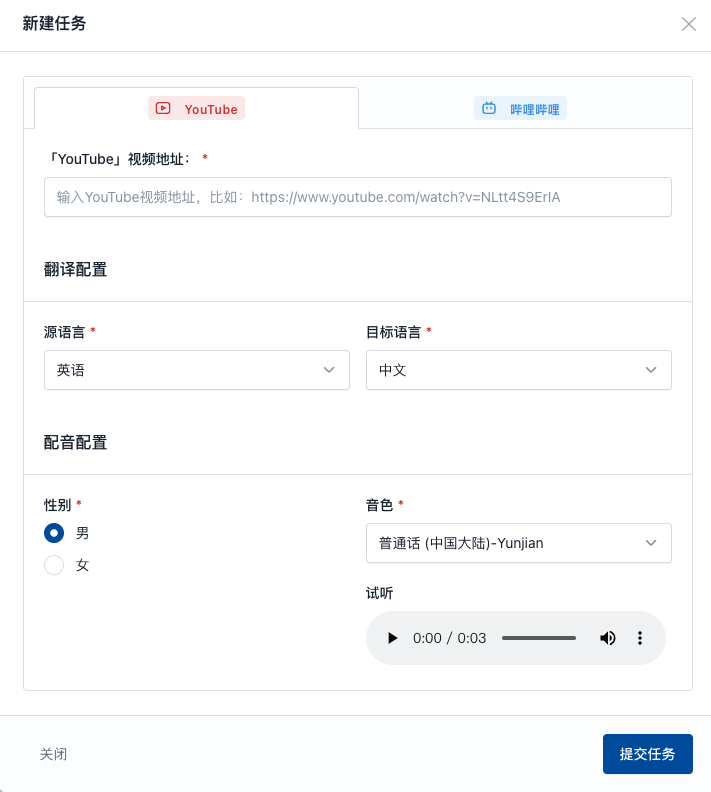
Subtitle Edit 是一款免费开源的多功能字幕编辑器,支持超过300种字幕格式。它具备字幕同步、创建、翻译、音频波形可视化、视频播放、AI语音识别、AI自动翻译和OCR技术等功能,适用于影视后期、多语言内容创作、教育培训及辅助听力障碍者等场景。其界面友好,操作简便。



TTS-Voice-Wizard
TTS语音向导是一种工具,允许用户通过微软Azure语音识别和TTS将语音转换为文本,然后再转换回语音。它还向VRChat发送OSC消息以在头像上显示文本。该工具有许多自定义选项,包括100...

FireRedASR
FireRedASR是小红书推出的工业级自动语音识别(ASR)模型系列,支持普通话、中文方言和英语,具备高精度和高效推理能力。其包含FireRedASR-LLM和FireRedASR-AED两个版本,分别聚焦于极致精度和计算效率。模型在多个场景如智能助手、视频字幕生成、歌词识别和语音输入中表现出色,且已开源,推动语音识别技术的发展。


