视频生成


StableAnimator
StableAnimator是一款由复旦大学、微软亚洲研究院、虎牙公司及卡内基梅隆大学联合开发的高质量身份保持视频生成框架。它能够根据参考图像和姿态序列,直接生成高保真度、身份一致的视频内容,无需后处理工具。框架集成了图像与面部嵌入计算、全局内容感知面部编码器、分布感知ID适配器以及Hamilton-Jacobi-Bellman方程优化技术,确保生成视频的流畅性和真实性。StableAnimato




ChatAnyone
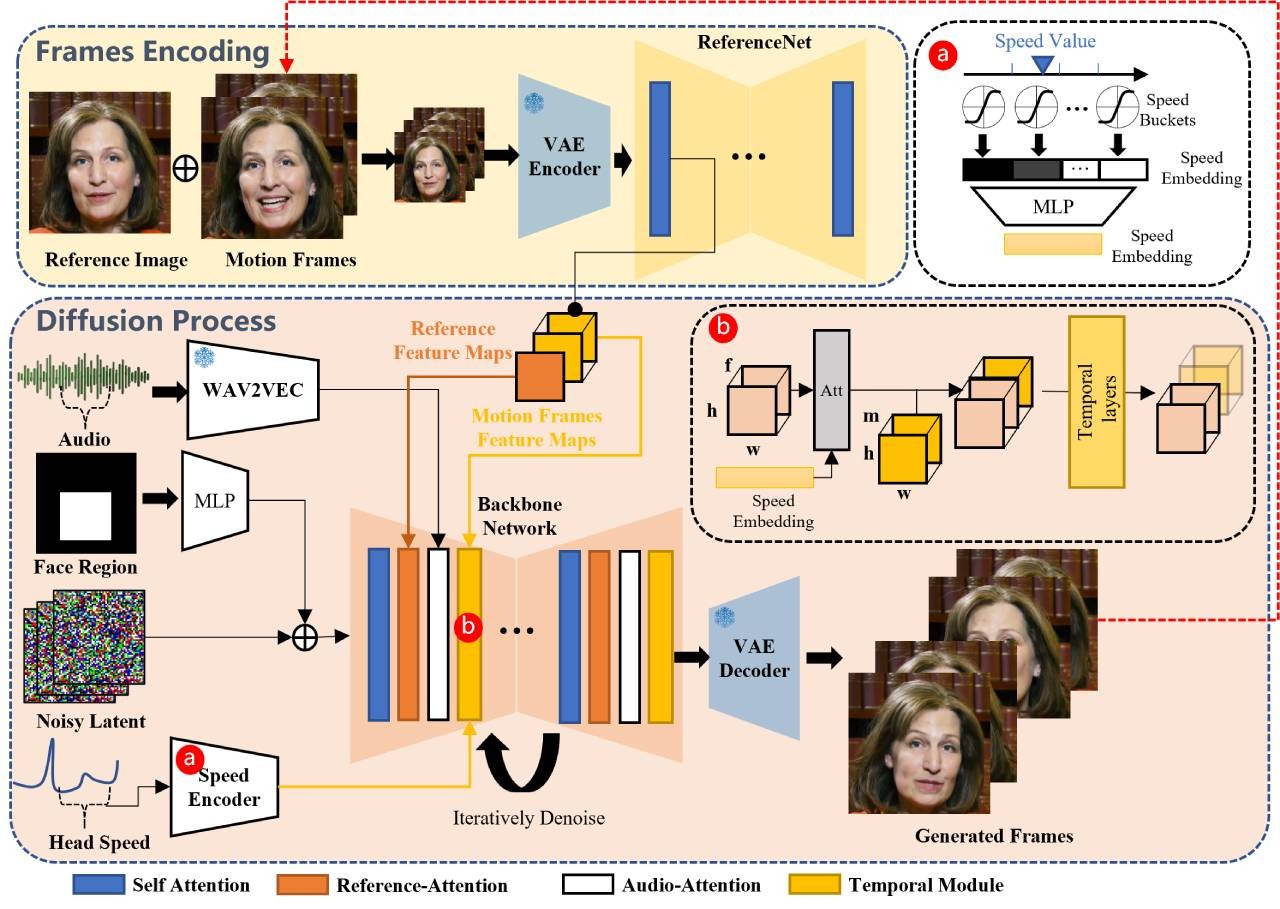
ChatAnyone是阿里巴巴通义实验室开发的实时风格化肖像视频生成工具,基于音频输入生成高保真、自然流畅的上半身动态视频。采用分层运动扩散模型和混合控制融合生成模型,支持实时交互与风格化控制,适用于虚拟主播、视频会议、内容创作等多种场景,具备高度可扩展性和实用性。


Video Alchemist
Video Alchemist是一款由Snap公司研发的视频生成模型,支持多主体和开放集合的个性化视频生成。它基于Diffusion Transformer模块,通过文本提示和参考图像生成视频内容,无需测试优化。模型引入自动数据构建和图像增强技术,提升主体识别能力。同时,研究团队提出MSRVTT-Personalization基准,用于评估视频个性化效果。该工具适用于短视频创作、动画制作、教育、剧