Evo 2 Evo 2 是一款基于 StripedHyena 2 架构的 DNA 语言模型,可处理长达 100 万个碱基对的基因序列,支持长序列建模、DNA 生成、嵌入向量提取及零样本预测等功能。其基于大规模基因组数据训练,适用于基因治疗、合成生物学和进化研究等多个领域,为基因组学研究提供强大支持。 AI项目与工具 2025年06月12日 71 点赞 0 评论 685 浏览
代悟AI搜索 一款专为开发者打造的 AI 搜索引擎,代悟AI搜索基于专业的开发知识图谱和 RAG 技术,帮助您快速、精准地获取技术答案。 AI搜索问答 2025年06月05日 73 点赞 0 评论 685 浏览
3DIS 3DIS-FLUX是一种基于深度学习的多实例图像生成框架,采用两阶段流程:先生成场景深度图,再进行细节渲染。通过注意力机制实现文本与图像的精准对齐,无需额外训练即可保持高生成质量。适用于电商设计、创意艺术、虚拟场景构建及广告内容生成等领域,具备良好的兼容性和性能优势。 AI项目与工具 2025年06月12日 32 点赞 0 评论 684 浏览
Candy.AI Candy.AI是一个创新的AI伴侣平台,它通过个性化定制和深度学习技术,为用户提供了一个高度互动和情感丰富的虚拟女友体验。 创作工具 1970年01月01日 0 点赞 0 评论 684 浏览
SynthID SynthID是一款由DeepMind研发的技术工具,通过在AI生成的内容中嵌入数字水印来验证其真实性与原创性。它支持多种内容形式,包括文本、音乐、图像和视频,并具备良好的抗修改性和检测稳定性。SynthID不仅不影响内容质量,还提升了信息可信度,广泛应用于新闻、版权保护、教育、法律及社交媒体等领域。 AI项目与工具 2025年06月12日 43 点赞 0 评论 683 浏览
Ev Ev-DeblurVSR是一款由多所高校联合开发的视频增强模型,利用事件相机数据提升视频去模糊和超分辨率效果。通过互惠特征去模糊模块和混合可变形对齐模块,实现高精度视频恢复。适用于监控、体育、自动驾驶等多个领域,支持快速部署与研究。 AI项目与工具 2025年06月11日 52 点赞 0 评论 682 浏览
QwQ QwQ-32B-Preview是一款由阿里巴巴开发的开源AI推理模型,具有325亿参数,擅长处理数学与编程领域的复杂任务。它能在多个基准测试中超越同类产品,并提供透明化的推理流程。然而,该模型在语言切换及跨领域应用上存在一定局限性。 AI项目与工具 2025年06月12日 99 点赞 0 评论 680 浏览
EasyOCR EasyOCR是一款基于深度学习技术的开源OCR工具,支持超过80种语言及多种书写系统。它提供高精度的文字识别能力,用户可通过简单的API轻松地将图像中的文本转换为可编辑的文本。EasyOCR易于安装和使用,支持跨平台操作,并具备批量处理能力。该工具在图像质量有一定要求的情况下,能够高效处理大量图像文件。 AI项目与工具 2025年06月12日 89 点赞 0 评论 680 浏览
Voice Voice-Pro是一款开源的多功能音频处理工具,集成了语音转文字、文本转语音、实时翻译、YouTube视频下载和人声分离等功能,支持超过100种语言,广泛应用于教育、娱乐和商业领域,显著提升音频处理效率和便捷性。 AI项目与工具 2025年06月12日 33 点赞 0 评论 679 浏览
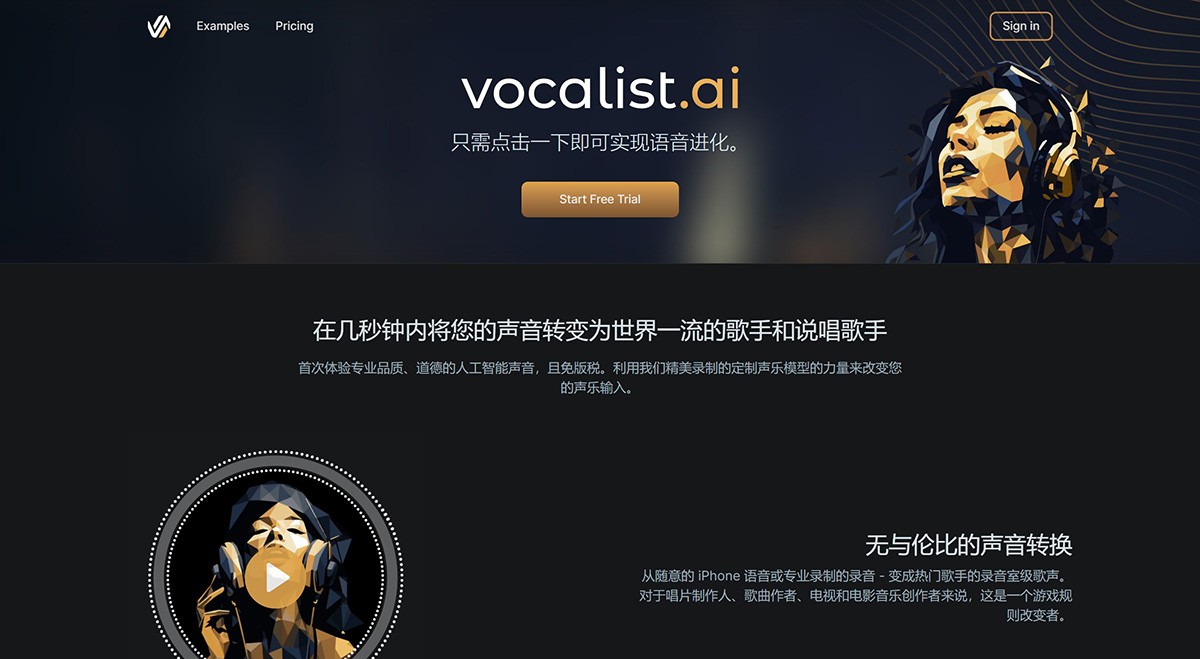
Vocalist.ai 一款可以使用定制的声乐模型将人声录音转换为专业品质的歌唱和说唱表演的录音室级AI声音转换工具,在几秒钟内将您的声音转变为世界一流的歌手和说唱歌手。 Ai语音工具 2025年06月05日 96 点赞 0 评论 678 浏览