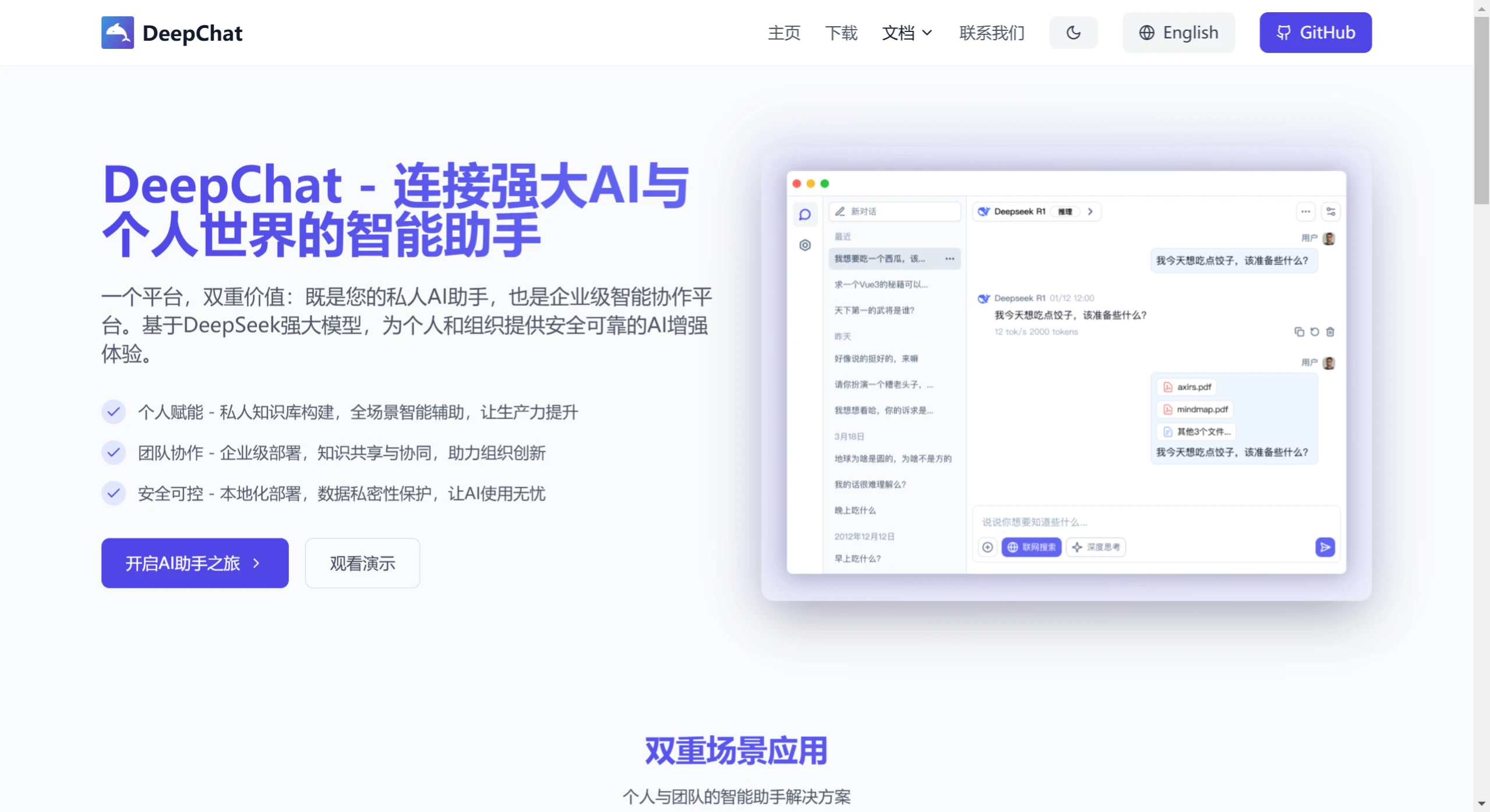
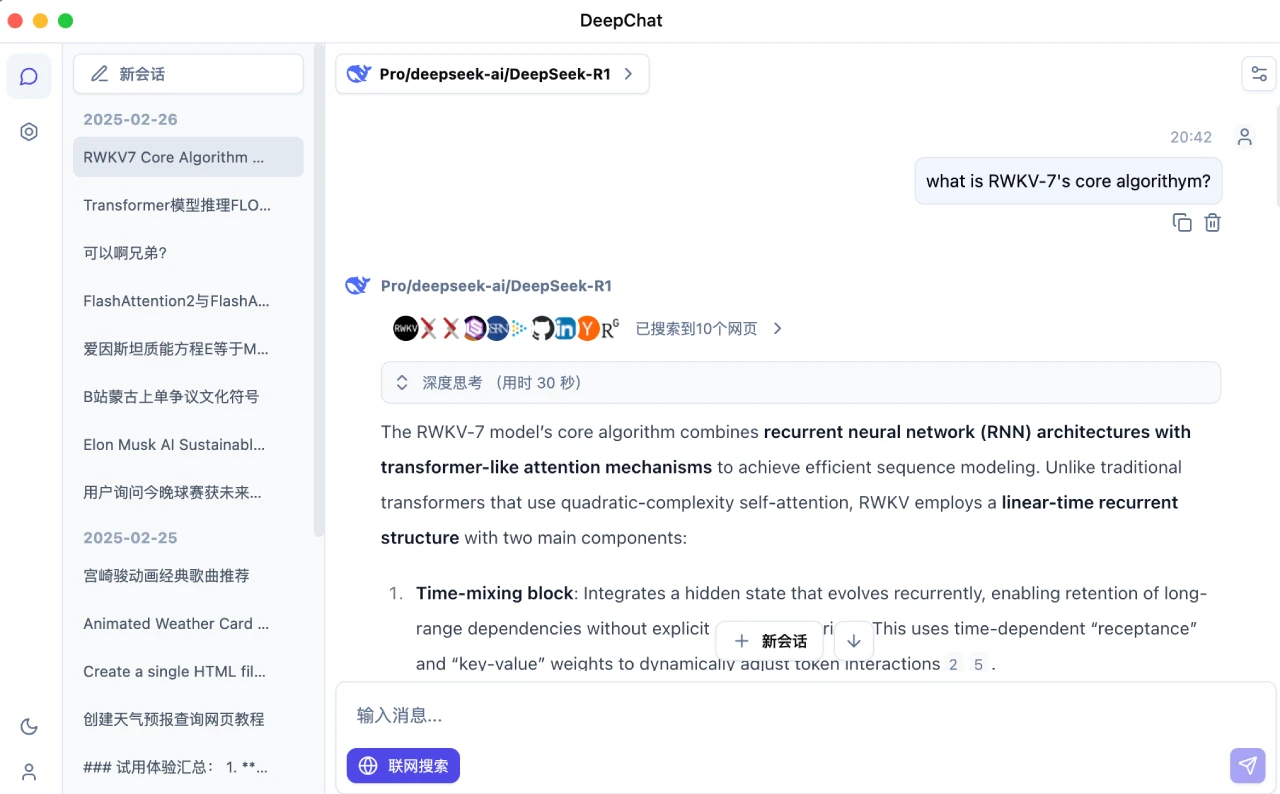
模型





Speech Studio
Speech Studio是一套用于构建和集成Azure认知服务语音服务功能到应用程序中的工具。它为创建项目提供了一种无需代码的方法,可以访问诸如实时语音到文本、自定义语音识别模型、发...

Promptriever
Promptriever是一款基于自然语言处理的新型检索模型,融合了大型语言模型提示技术与信息检索优势。它通过双编码器架构及指令训练集优化,实现了对复杂查询的高度适应性与鲁棒性,适用于搜索引擎优化、智能助手、企业内部搜索及学术研究等多个领域。