动画生成
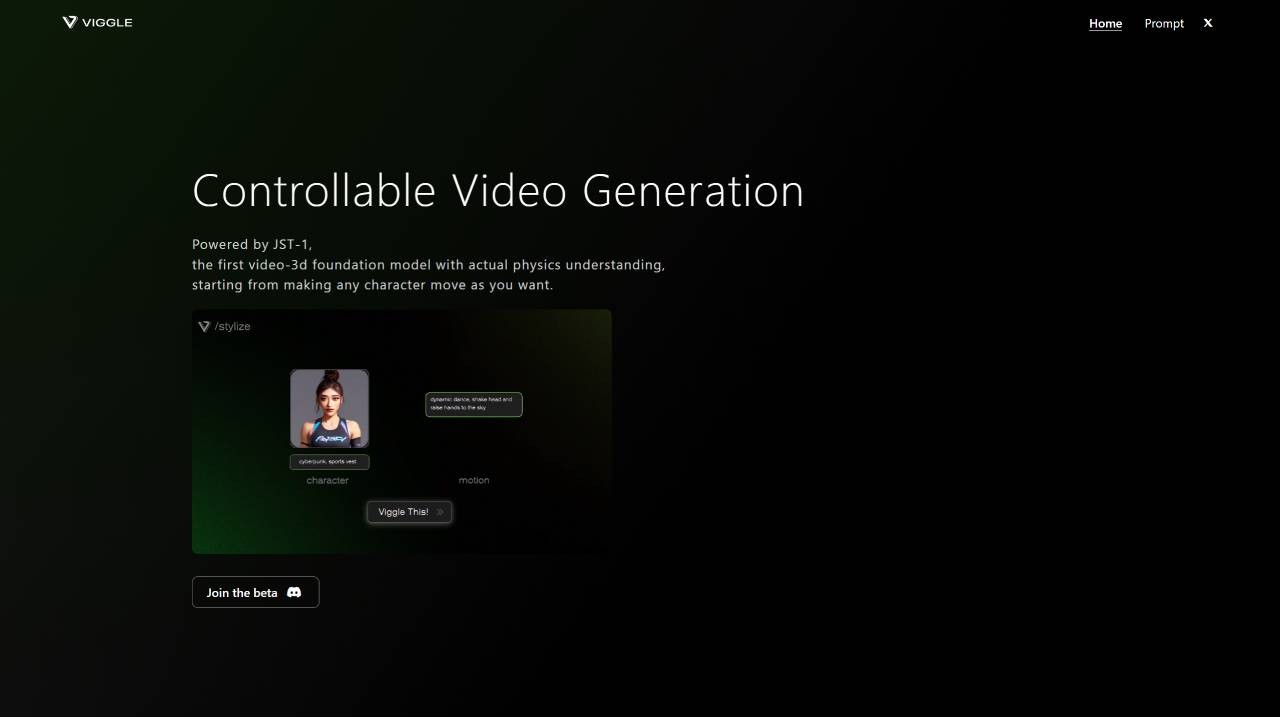




AnimateDiff
AnimateDiff是一款由上海人工智能实验室、香港中文大学和斯坦福大学的研究人员共同开发的框架,旨在将文本到图像模型扩展为动画生成器。该框架利用大规模视频数据集中的运动先验知识,允许用户通过文本描述生成动画序列,无需进行特定的模型调优。AnimateDiff支持多种领域的个性化模型,包括动漫、2D卡通、3D动画和现实摄影等,并且易于与现有模型集成,降低使用门槛。

EchoMimicV2
EchoMimicV2是一款由阿里巴巴蚂蚁集团研发的AI数字人动画生成工具,能够基于参考图片、音频剪辑及手部姿势序列生成高质量的半身动画视频。它支持多语言(中英双语)输入,并通过音频-姿势动态协调、头部局部注意力及特定阶段去噪损失等技术手段显著提高了动画的真实度与细节表现力,适用于虚拟主播、在线教育、娱乐游戏等多个领域。


neural frames
Neural Frames 是一款基于人工智能的文本转视频工具,能够将文本描述转换为动态视频内容,支持多种神经网络模型的选择与自定义训练。它具备音频反应动画、帧级编辑控制和高分辨率输出等功能,适用于音乐视频制作、数字艺术创作、广告设计、教育视频开发等多个领域,为创意工作者提供高效且灵活的解决方案。

MTVCrafter
MTVCrafter是由中国科学院深圳先进技术研究院计算机视觉与模式识别实验室、中国电信人工智能研究所等机构推出的新型人类图像动画框架,基于4D运动标记化(4DMoT)和运动感知视频扩散Transformer(MV-DiT)实现高质量动画生成。该工具直接对3D运动序列建模,支持泛化到多种角色和风格,保持身份一致性,并在TikTok基准测试中取得优异成绩。其应用场景包括数字人动画、虚拟试穿、沉浸式内

