Seedance 1.0 lite Seedance 1.0 lite 是火山引擎推出的轻量级AI视频生成工具,支持文生视频和图生视频,可生成5秒或10秒、480p/720p分辨率的视频。具备精细的人物控制和丰富的运镜方式,画质清晰、风格多样,广泛应用于电商、影视、娱乐等领域,有效提升制作效率并降低成本。 AI项目与工具 2025年06月11日 66 点赞 0 评论 791 浏览
可灵2.0 可灵2.0是快手推出的AI视频生成模型,支持文生视频和图生视频,具备复杂动态生成、动作流畅性和多模态编辑能力。它能根据用户输入的文字或图片生成高质量视频,提升视频的真实感和沉浸感,适用于影视、广告、教育、游戏等领域,提高创作效率与灵活性。 AI项目与工具 2025年06月11日 70 点赞 0 评论 790 浏览
Dawn AI Dawn AI是一款基于AI技术的图像生成工具,支持文本转图像、多种绘画风格选择以及头像生成等功能。用户可通过输入文字或上传图片,快速生成艺术作品。界面简洁易用,适合各类用户,适用于社交媒体、创意内容制作及角色定制等多种场景,提升创作效率与个性化表达。 AI项目与工具 2025年06月12日 39 点赞 0 评论 788 浏览
SketchVideo SketchVideo是一款基于草图和文本提示的视频生成与编辑框架,由多所高校与企业联合研发。它利用DiT模型和草图控制网络,实现对视频内容的精细控制,支持动态调整与细节保留。该工具适用于多种场景,如影视制作、教育、游戏开发等,具备高效生成与高质量输出能力。 AI项目与工具 2025年06月11日 83 点赞 0 评论 788 浏览
ProductScope Ai 一种基于AI,旨在帮助小型企业所有者和营销人员在几分钟内创建令人惊叹的AI商品图照片并优化产品列表的工具。 电商运营 2025年06月05日 21 点赞 0 评论 786 浏览
Make-A-Character 创新的3D角色生成框架,它通过文本描述快速创建逼真的3D角色,具有高度的定制性和逼真度。它结合了最新的人工智能技术,提供了一个直观、灵活且高效的角色创建解决方案,适用于多... Ai平台模型 1970年01月01日 0 点赞 0 评论 785 浏览
Long Long-VITA是一款由腾讯优图实验室、南京大学和厦门大学联合开发的多模态AI模型,支持处理超长文本(超过100万tokens)及多模态输入(图像、视频、文本)。通过分阶段训练提升上下文理解能力,结合动态分块编码器与并行推理技术,实现高效处理长文本和高分辨率图像。模型基于开源数据训练,适用于视频分析、图像识别、长文本生成等场景,性能在多个基准测试中表现突出。 AI项目与工具 2025年06月12日 65 点赞 0 评论 784 浏览
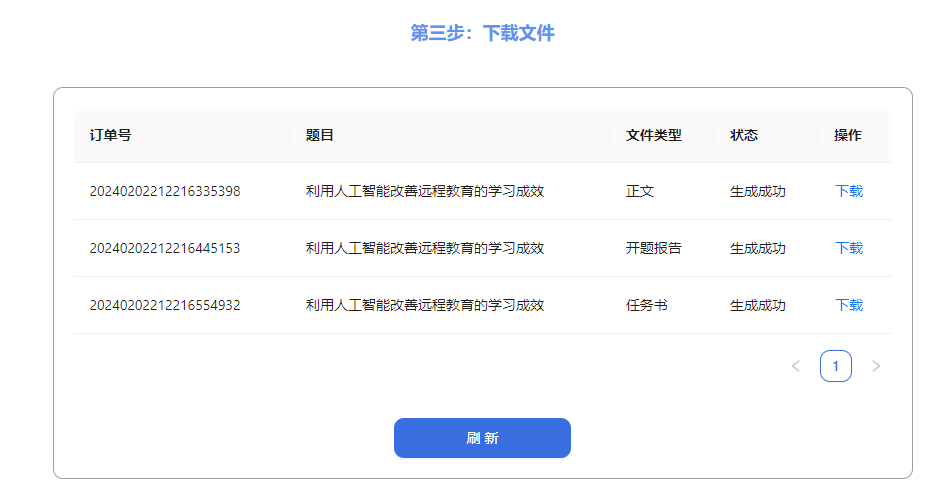
千言万象AI论文 一款专为学生和研究者设计的论文黑科技产品,支持个性化生成论文大纲与万字长文生成,提升学术写作效率。三步快速生成贴合专业和个人需求的论文开题报告、任务书、万字初稿! 教育学习 2025年06月05日 90 点赞 0 评论 783 浏览