在当今数字化时代,视频数据的爆炸式增长使得视频理解技术成为人工智能领域的研究热点。本专题致力于收集和整理最前沿的视频理解工具和资源,涵盖从基础模型到高级应用的各个层面。每个工具都经过专业的评测,包括功能对比、适用场景和优缺点分析,确保用户能够根据具体需求做出最佳选择。无论是进行复杂的三维场景生成,还是简单的视频问答,都能在这里找到合适的解决方案。我们不仅提供详尽的技术介绍,还结合实际案例展示这些工具在不同行业中的应用效果,帮助用户更好地理解和利用视频理解技术,推动各行业的智能化发展。通过本专题,用户不仅能掌握最新的技术动态,还能获得实用的操作指南,全面提升工作和学习效率。
工具测评、排行榜和使用建议
功能对比
- 字节跳动的LVLM系列:专注于视频理解任务,功能全面但模型较为庞大,适合大规模数据处理。
- Ming-Lite-Omni:多模态支持能力强,适用于多种应用场景,尤其在OCR和知识问答方面表现优异。
- Pixel Reasoner:通过像素空间推理增强视觉分析能力,特别适合需要细节捕捉的任务。
- BAGEL:参数量大,性能优越,适用于复杂任务如三维场景生成和跨模态检索。
- StreamBridge:端侧实时处理能力强,适合自动驾驶和智能监控等实时应用。
- Seed1.5-VL:长视频理解能力强,适合自动驾驶和机器人视觉领域。
- ViLAMP:专为长视频设计,适合教育、直播等需要长时间视频处理的场景。
- Qwen2.5-Omni-3B:轻量级模型,适合资源受限环境下的多模态任务。
- Kimi-VL:轻量且高效,适合智能客服和内容创作。
- Qwen2.5-Omni:多模态支持广泛,适合多种应用场景。
- AVD2:专注于事故视频理解,适合自动驾驶安全优化。
- Ovis2:结构化嵌入对齐技术提升融合效果,适合多语言处理。
- Magma:覆盖数字与物理环境,适合复杂任务如机器人控制。
- Long-VITA:支持超长文本和多模态输入,适合长视频分析。
- InternVideo2.5:细粒度时空感知强,适合视频编辑和监控。
- Qwen2.5-VL:强大的视觉理解能力,适合文档处理和智能助手。
- Baichuan-Omni-1.5:全模态支持,适合医疗和教育领域。
- VideoLLaMA3:深度理解和分析能力强,适合视频内容分析。
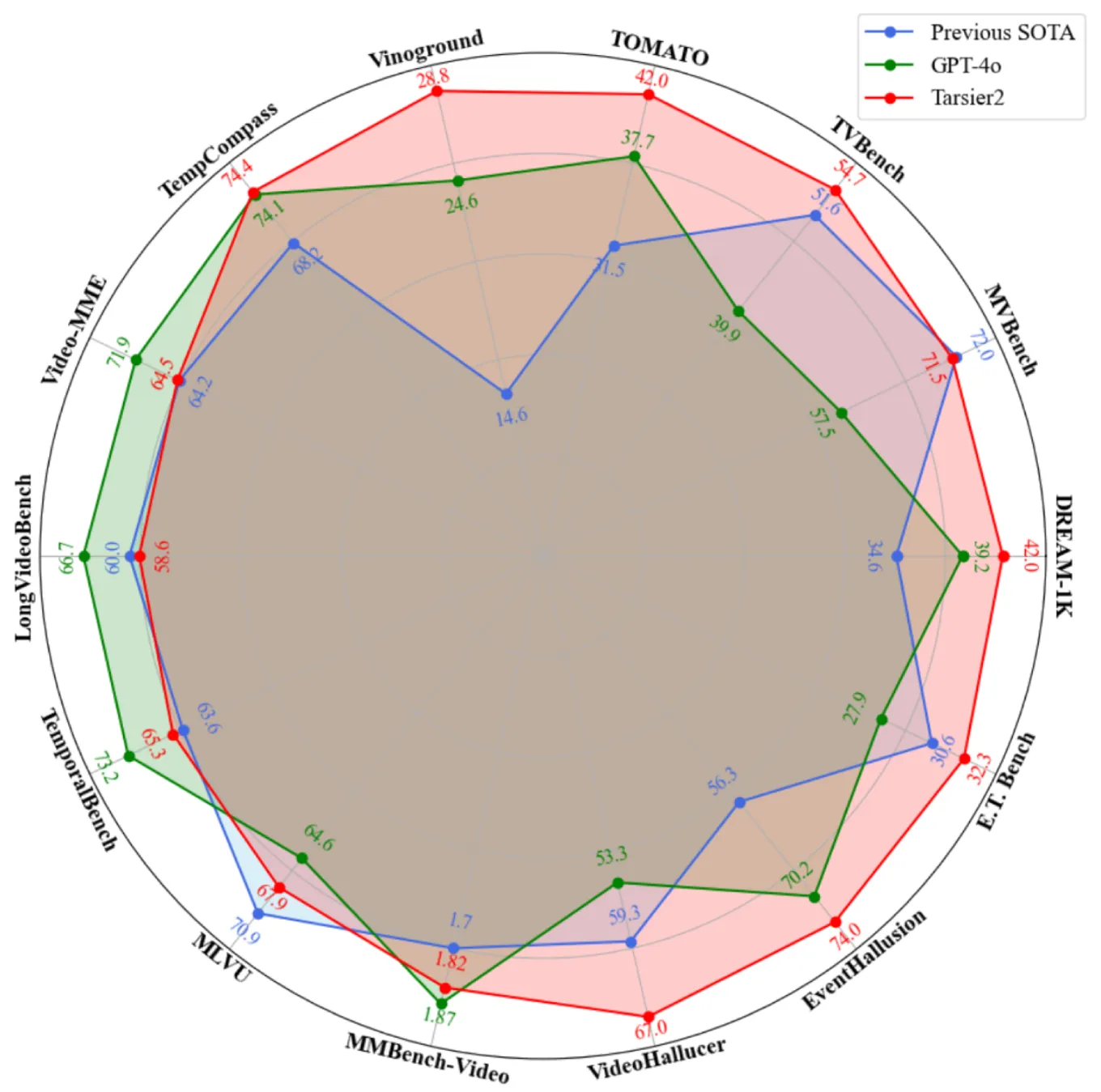
- Tarsier2:高精度视频描述,适合多语言视频理解任务。
- VideoChat-Flash:长视频建模能力强,适合视频问答和监控分析。
- VideoWorld:自动生成复杂知识,适合围棋和机器人控制。
- Uni-AdaFocus:高效视频理解框架,适合视频推荐和监控。
- GLM-Realtime:低延迟视频理解,适合教育和客服。
- VideoRAG:基于检索增强生成,适合视频问答和内容分析。
- VideoRefer:对象感知与推理系统,适合视频剪辑和安防。
- VideoPhy:物理常识评估工具,适合视频生成模型开发。
- Valley:多模态数据处理高效,适合内容分析和电子商务。
- VSI-Bench:视觉空间智能评估工具,适合模型性能对比。
- 豆包视觉理解模型:视觉定位能力强,适合图片问答和医疗影像分析。
- Apollo:视频内容理解卓越,适合视频搜索推荐和自动驾驶。
排行榜
- BAGEL:综合性能最优,适合复杂任务。
- Ming-Lite-Omni:多模态支持最强,适用范围广。
- Pixel Reasoner:细节捕捉能力强,适合科研和工业质检。
- Seed1.5-VL:长视频理解优秀,适合自动驾驶。
- Qwen2.5-Omni:多模态支持广泛,适合多种场景。
使用建议
- 复杂任务(如三维场景生成):选择BAGEL或Ming-Lite-Omni。
- 实时应用(如自动驾驶):选择StreamBridge或Seed1.5-VL。
- 长视频处理:选择ViLAMP或Long-VITA。
- 资源受限环境:选择Qwen2.5-Omni-3B或Kimi-VL。
特定领域(如医疗、教育):选择Baichuan-Omni-1.5或Qwen2.5-VL。
专题内容优化

Pixel Reasoner
Pixel Reasoner是由多所高校联合开发的视觉语言模型,通过像素空间推理增强对视觉信息的理解和分析能力。它支持直接对图像和视频进行操作,如放大区域或选择帧,以捕捉细节。采用两阶段训练方法,结合指令调优和好奇心驱动的强化学习,提升视觉推理性能。在多个基准测试中表现优异,适用于视觉问答、视频理解等任务,广泛应用于科研、教育、工业质检和内容创作等领域。


StreamBridge
StreamBridge是一款由苹果与复旦大学联合开发的端侧视频大语言模型框架,支持实时视频流的理解与交互。通过内存缓冲区和轮次衰减压缩策略,实现长上下文处理与主动响应。项目配套发布Stream-IT数据集,包含60万样本,适用于多种视频理解任务,展现出在视频交互、自动驾驶、智能监控等领域的应用前景。




发表评论 取消回复