本专题聚焦于视频扩散模型领域的最新进展,整理并介绍了各类前沿工具和资源。这些工具不仅代表了当前技术的最高水平,还展示了未来发展的潜力。我们从专业的角度对每个工具进行了详细的测评,包括功能对比、适用场景、优缺点分析等,并制定了科学合理的排行榜。无论您是从事影视制作、游戏开发、广告营销还是教育科研,都能在这里找到满足需求的最佳工具。此外,专题还提供了丰富的案例和应用场景,帮助用户更好地理解和应用这些工具,提高工作和学习效率。通过本专题,您可以深入了解视频扩散模型的技术原理、发展趋势以及实际应用,为您的项目提供有力的支持和参考。
工具测评与排行榜
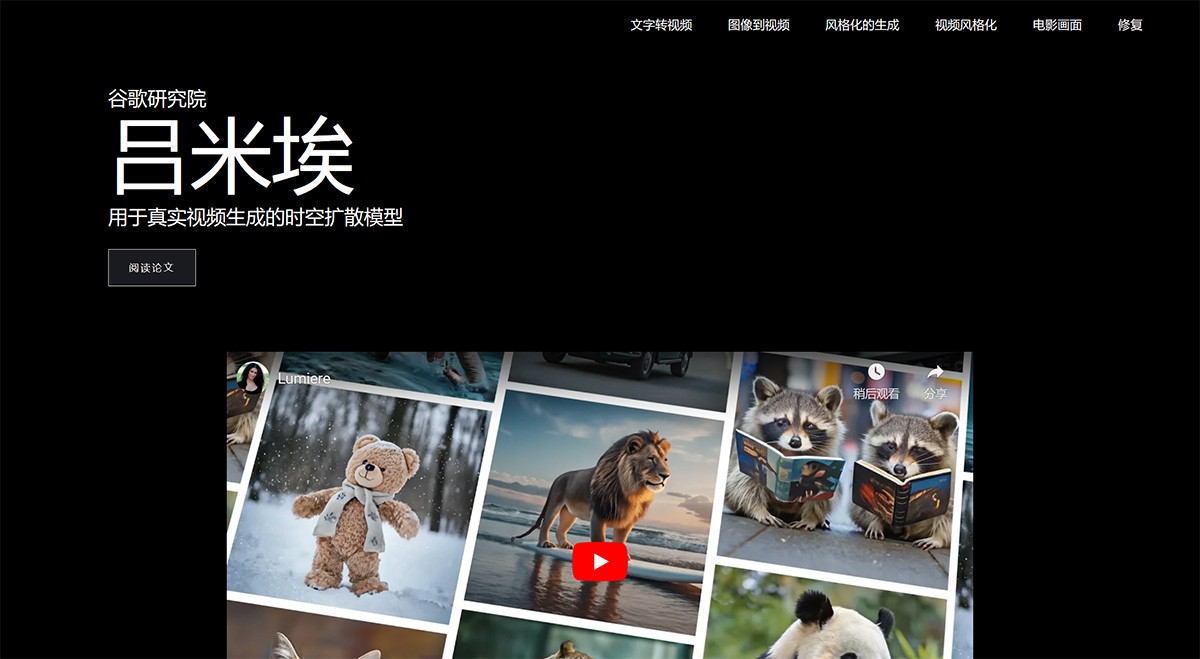
谷歌研究院的时空文本到视频扩散模型:该工具在生成连贯性和逼真度方面表现卓越,适用于需要高质量、长时间视频生成的任务。其创新的空间时间U-Net架构使其在处理复杂场景时具有优势。
MultiTalk:特别适合需要音频驱动的多人对话视频生成,尤其是卡通和歌唱等娱乐场景。L-RoPE方法确保了多声道音频与人物的精准绑定,但可能在复杂背景或高动态场景中表现不佳。
Vid2World:适用于需要自回归生成和动作条件化的复杂环境,如机器人操作和游戏模拟。其核心技术解决了传统VDM的不足,但在实时应用中可能存在延迟问题。
VPP:在高频预测和跨机器人本体学习方面表现出色,适用于家庭、工业等多个领域。开源特性促进了技术的发展,但可能需要较高的计算资源。
HoloTime:全景4D场景生成框架,支持VR/AR应用,尤其适合虚拟旅游和影视制作。其训练数据集的质量决定了最终效果。
FantasyTalking:适用于需要从静态肖像生成高质量虚拟形象的场景,如游戏和影视制作。其双阶段视听对齐策略确保了口型同步和表情丰富性。
ACTalker:端到端生成高质量说话人头部视频,适合远程会议和在线教育。并行Mamba结构提升了音频同步性和视频质量。
AnimeGamer:基于多模态大语言模型,适合动漫生活模拟系统,支持自然语言指令操控。适用于创意激发和个性化娱乐。
OmniCam:结合大型语言模型和视频扩散模型,适用于高质量、时空一致的视频内容生成,尤其适合影视和广告制作。
TrajectoryCrafter:单目视频相机轨迹重定向工具,适用于沉浸式娱乐和自动驾驶。其解耦视图变换与内容生成技术提升了场景泛化能力。
排行榜(按综合性能排序)
- 谷歌研究院的时空文本到视频扩散模型
- Vid2World
- VPP
- HoloTime
- MultiTalk
- FantasyTalking
- ACTalker
- AnimeGamer
- OmniCam
TrajectoryCrafter
使用建议
- 高质量视频生成:推荐使用谷歌研究院的时空文本到视频扩散模型。 - 音频驱动视频生成:推荐使用MultiTalk。 - 复杂环境生成:推荐使用Vid2World和VPP。 - 全景4D场景生成:推荐使用HoloTime。 - 虚拟形象生成:推荐使用FantasyTalking和ACTalker。
功能对比、适用场景及优缺点分析 - 功能对比:各工具在生成质量和应用场景上有显著差异,需根据具体需求选择。 - 适用场景:不同工具适用于不同的应用场景,需结合实际需求进行选择。 - 优缺点分析:各工具在性能和资源消耗上各有优劣,需权衡利弊。


One Shot, One Talk









发表评论 取消回复