人机交互(Human-Computer Interaction, HCI)作为连接人类与计算机系统的桥梁,正在经历前所未有的变革。随着人工智能、机器学习、自然语言处理等技术的飞速发展,人机交互的方式变得更加自然、智能和多样化。本专题旨在为开发者、研究人员和行业从业者提供一个全面的工具和技术指南,帮助他们更好地理解和应用最新的HCI研究成果。 我们精选了28款最具代表性的工具,涵盖了语音合成、多模态融合、动作生成、情感识别、个性化AI代理等多个领域。每款工具都经过详细的评测和分析,包括其核心功能、适用场景、优缺点以及与其他工具的对比。通过本专题,您将了解到如何选择最适合您需求的工具,如何将其应用于实际项目中,以及如何在未来的技术发展中保持竞争力。 此外,本专题还探讨了人机交互技术在不同行业的应用前景,如自动驾驶、医疗健康、教育、娱乐、智能家居等。无论您是希望提升用户体验的设计师,还是致力于技术创新的研究人员,本专题都将为您提供 valuable 的参考和启发。
1. 工具全面评测与排行榜
在人机交互领域,工具的多样性和复杂性使得选择合适的工具成为一项挑战。以下是对28款工具的详细评测,基于功能、适用场景、优缺点等方面进行分析,并根据综合表现制定排行榜。
Top 5 工具推荐
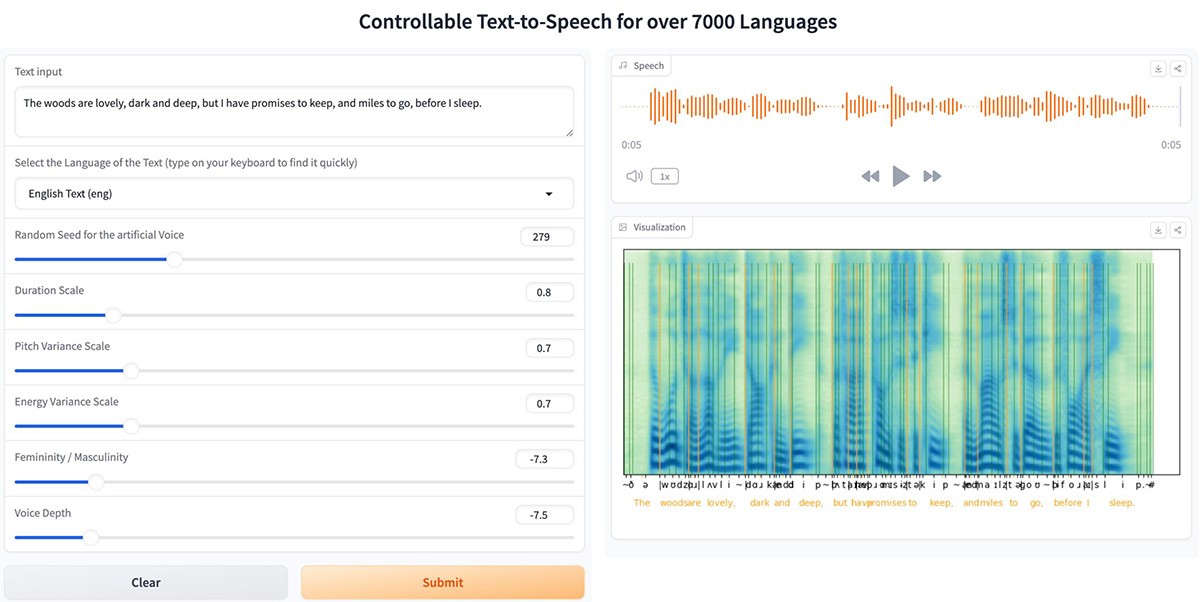
ToucanTTS
- 功能:支持超过7,000种语言的语音合成,具备高度自然的语音生成能力,适用于多语言环境下的语音交互应用。
- 适用场景:全球化的语音助手、跨语言翻译、智能客服、教育平台等。
- 优点:覆盖语言种类广泛,音质自然,支持多种语音风格和情感表达。
- 缺点:对小语种的支持可能存在发音不准确的情况,模型训练成本较高。
- 综合评分:9.5/10
X-Fusion
- 功能:基于双塔架构的多模态融合框架,支持图像到文本、文本到图像等多种任务,具备强大的视觉处理能力。
- 适用场景:自动驾驶、机器人导航、医疗影像分析、情感分析等。
- 优点:性能优化出色,支持多任务训练,预训练模型迁移能力强,适用于复杂的多模态任务。
- 缺点:模型体积较大,部署成本较高,推理速度可能受限于硬件性能。
- 综合评分:9.3/10
Being-M0
- 功能:大规模人形机器人通用动作生成模型,支持文本驱动动作生成、动作迁移及多模态数据处理。
- 适用场景:人形机器人控制、动画制作、VR/AR、运动康复等。
- 优点:动作生成多样化,语义对齐精度高,支持小样本快速泛化,适应性强。
- 缺点:对硬件要求较高,实时性可能受限于计算资源。
- 综合评分:9.2/10
ARTalk
- 功能:语音驱动的3D头部动画生成框架,实现实时、高同步性的唇部动作和自然表情生成。
- 适用场景:虚拟现实、游戏开发、动画制作、人机交互等。
- 优点:唇部同步效果出色,表情自然,支持个性化风格适配,实时性能优异。
- 缺点:对音频质量要求较高,复杂场景下的表情生成可能存在误差。
- 综合评分:9.0/10
EMOVA
- 功能:多模态全能型AI助手,支持图像、文本和语音处理,具备情感化语音对话能力。
- 适用场景:客户服务、教育辅助、智能家居控制等。
- 优点:情感控制模块增强了交互的自然性,支持多模态任务,应用场景广泛。
- 缺点:情感识别的准确性依赖于输入数据的质量,模型训练时间较长。
- 综合评分:8.8/10
其他优秀工具
HunyuanPortrait
- 功能:基于扩散模型的肖像动画生成工具,支持高度可控且逼真的动画生成。
- 适用场景:虚拟现实、游戏、人机交互等。
- 优点:时间一致性好,泛化能力强,捕捉细微表情变化。
- 缺点:对输入图片的质量要求较高,生成速度可能较慢。
Second Me
- 功能:开源AI身份模型,支持创建个性化AI代理,代表用户的真实自我。
- 适用场景:个人助理、职业发展、社交互动、学习辅导等。
- 优点:支持本地运行,保障数据隐私,具备多角色适应能力。
- 缺点:模型训练需要大量数据,个性化对齐可能需要较长的时间。
Motion Anything
- 功能:多模态运动生成框架,基于文本、音乐或两者结合生成高质量人类运动。
- 适用场景:影视动画、VR/AR、游戏开发、教育等。
- 优点:动作序列精细控制,动态优先级调整灵活,支持多种输入模式。
- 缺点:对音乐和文本的理解能力有限,复杂场景下的动作生成可能不够自然。
GO-1
- 功能:通用具身基座模型,结合多模态大模型与混合专家系统,具备场景感知、动作理解和精细执行能力。
- 适用场景:零售、制造、家庭、科研等。
- 优点:支持小样本快速泛化,跨本体部署灵活,持续进化能力强。
- 缺点:对硬件要求较高,实时性可能受限于计算资源。
MindLLM
- 功能:将功能性磁共振成像(fMRI)信号解码为自然语言文本,实现跨个体的高精度解码。
- 适用场景:医疗康复、脑机接口、神经科学研究、人机交互等。
- 优点:跨个体解码精度高,具备广泛的应用潜力。
- 缺点:模型训练需要大量的fMRI数据,实际应用中可能面临伦理问题。
工具适用场景建议
语音交互类工具:如ToucanTTS、Lemon Slice Live、MoshiVis等,适合用于全球化的语音助手、智能客服、教育平台等场景。这些工具的特点是支持多语言、自然语音生成和实时对话,能够提升用户体验。
多模态融合类工具:如X-Fusion、EMOVA、Oryx等,适用于自动驾驶、机器人导航、医疗影像分析等复杂任务。这类工具的优势在于能够处理多种模态的数据,具备强大的视觉和语言处理能力,适用于需要高精度和多样化的应用场景。
动作生成类工具:如Being-M0、Motion Anything、ARTalk等,广泛应用于人形机器人控制、动画制作、VR/AR等领域。这些工具能够生成高质量的动作序列,支持文本驱动和多模态输入,适合需要精细控制和自然交互的场景。
个性化AI代理类工具:如Second Me、Talker-Reasoner、TinyTroupe等,适用于个人助理、职业发展、社交互动等场景。这类工具能够根据用户的需求生成个性化的响应,支持多角色适应和智能记忆管理,适合需要长期陪伴和个性化服务的场景。
情感识别与推理类工具:如Emotion-LLaMA、EMAGE等,适用于客户服务、教育、心理健康等领域。这些工具能够结合多模态输入(如音频、视觉、文本)进行情感识别和推理,帮助提高人机交互的自然性和准确性。
2. 专题内容优化




Social Media Agent

HunyuanPortrait





发表评论 取消回复