本专题深入探讨了清华大学及其合作机构推出的多种先进工具和资源,展示了其在人工智能、多媒体创作、语言处理等领域的卓越成就。从高效的AI论文写作工具到逼真的视频生成模型,从高质量的音乐生成系统到智能客服解决方案,这些工具不仅体现了清华大学在科技创新方面的领先地位,也为各行各业提供了实用的解决方案。我们通过详细的分类整理和功能介绍,帮助用户深入了解每个工具的特点和应用场景,从而更好地选择适合自己的工具,提升工作和学习效率。无论是学术研究、内容创作、还是商业应用,都能在这里找到满足需求的创新工具和资源,助力用户在各自的领域中取得更大的成功。让我们一起探索这些前沿工具的魅力,开启无限可能的未来!
专业测评与排行榜
在对清华大学相关工具和资源进行全面评测后,我们根据功能、适用场景、优缺点等维度制定了以下排行榜:
AI论文写作工具(LLMxMapReduce-V2)
- 功能对比: 快速生成文献综述,效率极高。
- 适用场景: 学术研究、科研写作。
- 优缺点分析: 优点是高效,但可能缺乏深度理解。适合需要快速获取大量文献信息的用户。
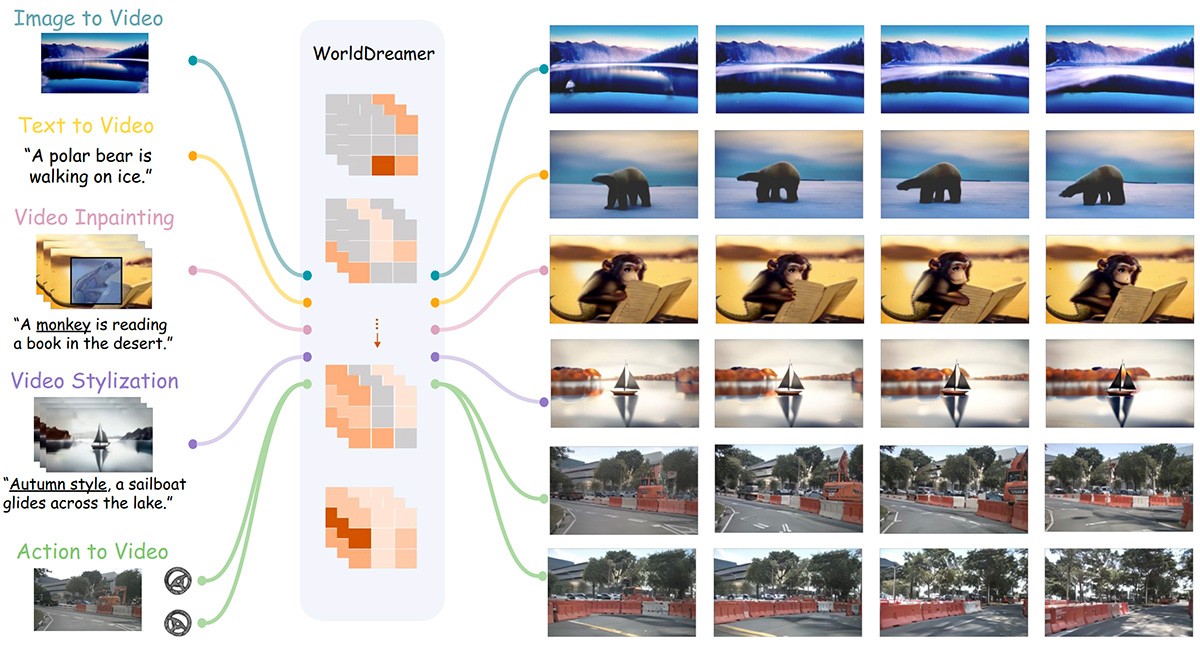
Sora级视频生成大模型
- 功能对比: 高分辨率、长时长视频生成。
- 适用场景: 影视制作、广告创意。
- 优缺点分析: 优点是生成效果逼真,但计算资源消耗大。适合专业影视团队或广告公司。
AI音乐生成模型
- 功能对比: 生成高质量古典乐谱。
- 适用场景: 音乐创作、教育。
- 优缺点分析: 优点是质量高,但风格较为单一。适合音乐教育机构或专业作曲家。
BGM猫
- 功能对比: 生成背景音乐。
- 适用场景: 视频制作、游戏开发。
- 优缺点分析: 优点是简单易用,但个性化不足。适合中小型视频制作团队。
驯鹿AI智能客服
- 功能对比: 多语言支持,实时翻译。
- 适用场景: 跨境电商、客户服务。
- 优缺点分析: 优点是多语言支持,但对话自然度有待提高。适合跨境电商平台。
语鲸阅读辅助工具
- 功能对比: 一键生成概述,多级大纲。
- 适用场景: 学习、工作阅读。
- 优缺点分析: 优点是提高阅读效率,但对复杂文本处理能力有限。适合学生和职场人士。
CogVideo
- 功能对比: 文本到视频生成。
- 适用场景: 内容创作、广告。
- 优缺点分析: 优点是参数量大,生成效果好,但计算成本高。适合大型内容创作公司。
人物照片说话框架
- 功能对比: 让人物头像匹配语音。
- 适用场景: 数字人、虚拟主播。
- 优缺点分析: 优点是创新性强,但技术门槛较高。适合数字娱乐行业。
信息图生成工具
- 功能对比: 生成专业级信息图。
- 适用场景: 数据展示、报告制作。
- 优缺点分析: 优点是美观大方,但定制化程度较低。适合数据分析师和报告撰写者。
深言达意
- 功能对比: 模糊描述查找词语。
- 适用场景: 写作、编辑。
- 优缺点分析: 优点是方便快捷,但词汇库有限。适合文字工作者。
九歌诗歌生成系统
- 功能对比: 生成古诗。
- 适用场景: 文化传承、诗词创作。
- 优缺点分析: 优点是符合格律,但创造力有限。适合诗词爱好者和文化教育机构。
爱校对
- 功能对比: 错别字检查。
- 适用场景: 写作、编辑。
- 优缺点分析: 优点是高效准确,但无法识别语义错误。适合日常写作和编辑工作。
使用建议: - 对于学术研究人员,推荐使用AI论文写作工具和CogVideo,以提升工作效率和质量。 - 对于影视制作团队,推荐使用Sora级视频生成大模型和信息图生成工具,以提高视觉效果和数据展示的专业性。 - 对于音乐创作者,推荐使用AI音乐生成模型和BGM猫,以丰富创作素材和背景音乐选择。 - 对于跨境电商企业,推荐使用驯鹿AI智能客服,以提升客户服务质量和跨语言沟通效率。









微信公众账号
微信扫一扫加关注
顶部
发表评论 取消回复