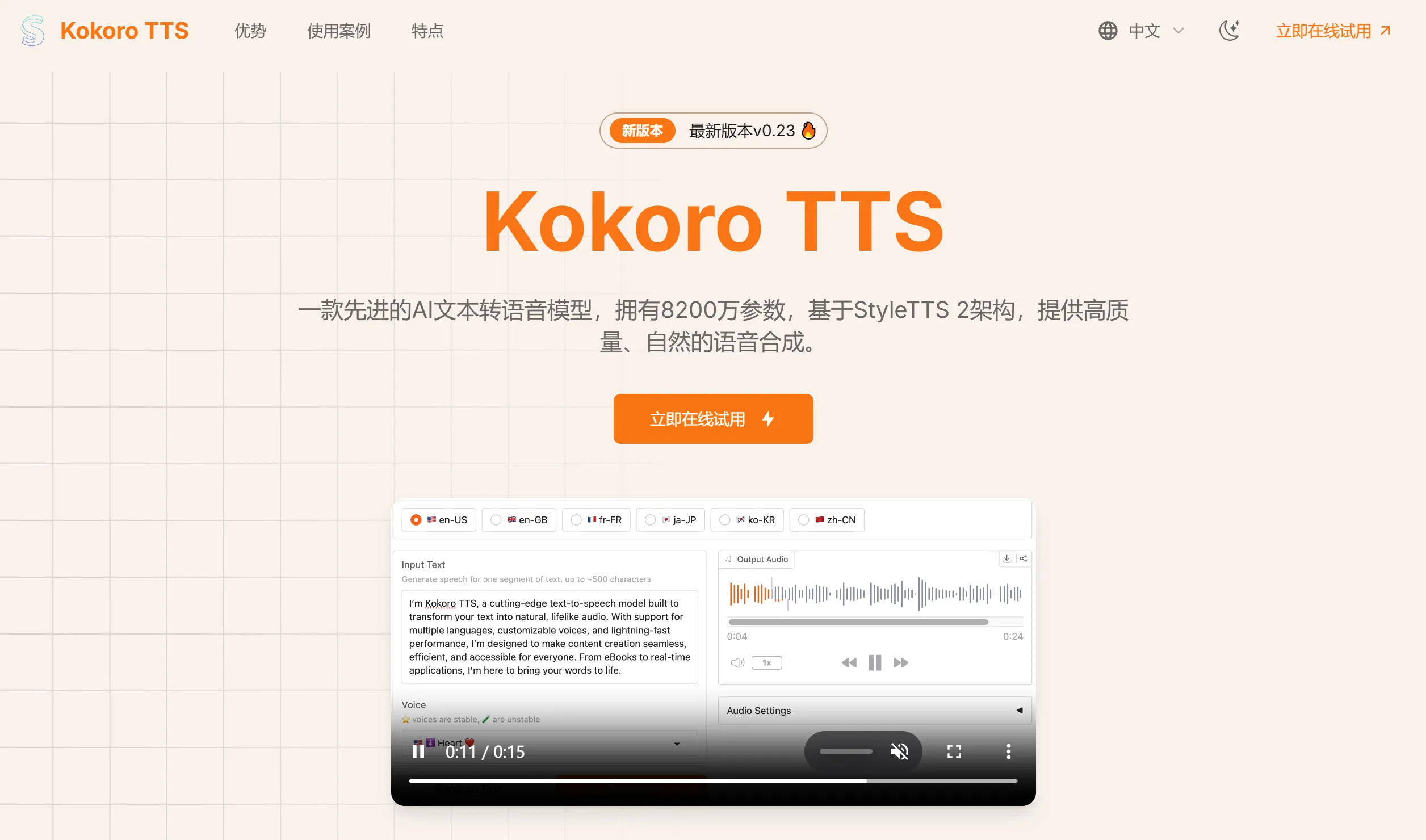
Kokoro TTS 是一款开源、轻量级且高性能的文本转语音(TTS)模型,拥有8200万参数,基于先进的StyleTTS 2架构。它能生成高质量、自然流畅的语音,广泛应用于有声书、播客等领域,已成为TTS领域的明星产品。
Kokoro TTS功能
高质量语音合成:支持多种语言,包括美式和英式英语、法语、日语、韩语和中文等,生成自然流畅的语音。
多语言支持:涵盖美式英语、英式英语、法语、韩语、日语和普通话等多种语言。
语音风格多样性:提供10种不同的语音包,覆盖不同性别和特征,并支持特殊风格如耳语。
低资源消耗:仅需8200万参数,资源消耗低,可在普通计算机上高效运行。
实时生成:支持实时语音生成,用户可即时获得语音输出。
多种输入格式:支持文本文件和电子书(如EPUB)等多种输入格式。
Kokoro TTS核心特点:
轻量化与高性能
Kokoro TTS 通过优化的 StyleTTS 2 和 ISTFTNet 混合架构,仅需8200万参数即可实现高质量语音合成,媲美数十亿参数的大型模型。其纯解码器设计降低计算复杂度,支持CPU近实时合成和GPU加速处理。
速度与效率:合成速度低于100ms,适合边缘计算和低资源设备部署。
多语言支持:目前主攻英语(美式/英式),未来可扩展至中文、法语、日语等多语言。
开源与商业
采用Apache 2.0许可证,允许免费商用和二次开发,适合个人开发者与企业集成。Hugging Face平台提供模型权重和部署文档,降低使用门槛。
多样化语音风格
提供10+预训练语音包(如Bella、Adam、Sarah),涵盖不同性别和口音,支持耳语等特殊风格。
Kokoro TTS技术优势:
架构创新:结合StyleTTS 2的韵律控制和ISTFTNet的高效频谱生成,无需依赖扩散模型,减少计算资源消耗,同时保持高保真音质。
训练与数据合规:基于100小时精选数据集,数据来源包括公共领域音频和合规合成内容,确保版权安全。
部署灵活性:支持ONNX运行时优化,可本地或云端部署,无需依赖GPU,兼容Docker、FastAPI等工具,提供REST API接口。
Kokoro TTS应用场景:
实时交互系统:如语音助手、客服应答,利用低延迟特性实现即时语音反馈。
内容创作:有声书、广告配音、游戏角色语音生成,支持个性化音色选择。
无障碍服务:为视障用户提供文本转语音支持,帮助他们获取信息。
教育与媒体:在线课程讲解、播客制作,生成多语言培训视频或教学音频内容。
游戏与虚拟现实:为游戏和虚拟现实应用中的角色提供自然语音。
电子书转有声书:轻松将电子书转化为高质量有声书,支持小众标题和多语言语音。
快速入门
从Github下载,通过pip或npm安装依赖项。
从Hugging Face克隆模型并加载语音包。
调用API生成24kHz音频,支持本地或边缘设备运行。
由于其开源和友好的商业许可,Kokoro TTS在市场上具有竞争优势,尤其适合需要高质量语音合成的商业应用。



发表评论 取消回复