LiberSonora 是一个开源的有声书工具集,其名称寓意“自由的声音”。LiberSonora 工具集能够提供多种功能,包括智能字幕提取、AI 标题生成和多语言翻译。

LiberSonora 主要功能:
智能字幕提取:LiberSonora 可以从音频文件中自动提取字幕,极大地简化了有声书的制作过程。
AI 标题生成:LiberSonora 能自动为音频内容生成适当的标题,帮助用户更好地组织和管理他们的作品。
多语言翻译:LiberSonora 支持多种语言的翻译功能。
GPU 加速:LiberSonora 支持 GPU 加速,处理速度更快。
多模型选择:灵活的模型选择,支持本地 Ollama、DeepSeek 和 OpenAI 等多种大模型。
批量处理有声书:强大的批量处理功能,轻松处理大量有声书。
本地音频处理:离线处理服务器本地音频文件,省去文件传输步骤。
手动检查输出结果:便捷的手动检查功能,可手动命名也可让 AI 重新生成。
LiberSonora 亮点:
开源自由:采用 MIT 许可证,真正的开源免费,音频处理与大模型推理全程本地离线运行,自主可控,数据安全有保障。
功能创新:提供独特的 AI 技术处理音频与文本生成能力。
便捷部署:项目容器化,开发与部署便利,支持 API,轻松集成到个人工作流。
模块化设计:各功能模块独立,可单独启动特定服务(如音频增强、字幕识别等)
灵活定制:支持自定义大模型,针对特定任务提升效果,配置灵活多样,满足不同需求
LiberSonora 使用场景:
LiberSonora 非常适合内容创作用户、小型出版社、视频博主、播客以及任何对制作有声内容感兴趣的群体。
如何使用?
1. 克隆项目仓库:
首先,您需要克隆 LiberSonora 的 GitHub 仓库到本地。打开终端或命令提示符,运行以下命令:
git clone https://github.com/LiberSonora/LiberSonora
2. 进入项目目录:
cd LiberSonora
3. 启动 Docker 容器:
docker-compose -f docker-compose.gpu.yml up -d
4. 查看容器运行日志:
docker-compose -f docker-compose.gpu.yml logs -f
5. 访问界面:
打开浏览器,访问 xxx.xxx.xxx.xxx:8651(将 xxx.xxx.xxx.xxx 替换为您的服务器 IP 地址),您将看到 LiberSonora 的 Web 界面。您可以通过这个界面管理有声书文件,提取字幕,生成标题,进行多语言翻译等。
6. 使用 API:
如果您希望通过 API 集成 LiberSonora,可以参考项目文档中的 API 接口说明。您可以使用 HTTP 请求与 LiberSonora 进行交互,实现自动化处理。
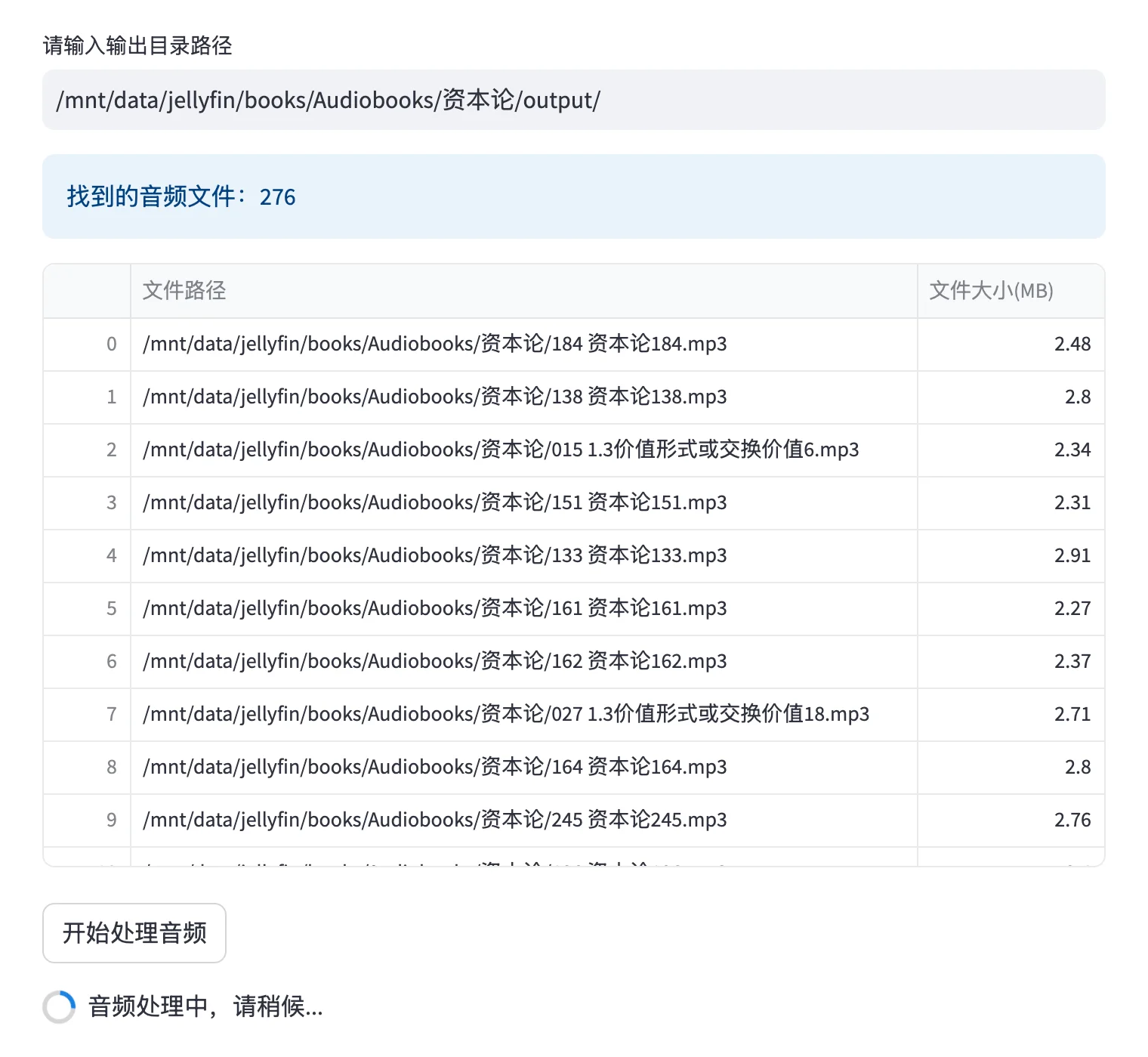
7. 处理音频文件:
将您的有声书音频文件放入指定的目录,LiberSonora 会自动处理这些文件,生成字幕和标题,并支持多语言翻译。
GitHub:https://github.com/LiberSonora/LiberSonora



发表评论 取消回复