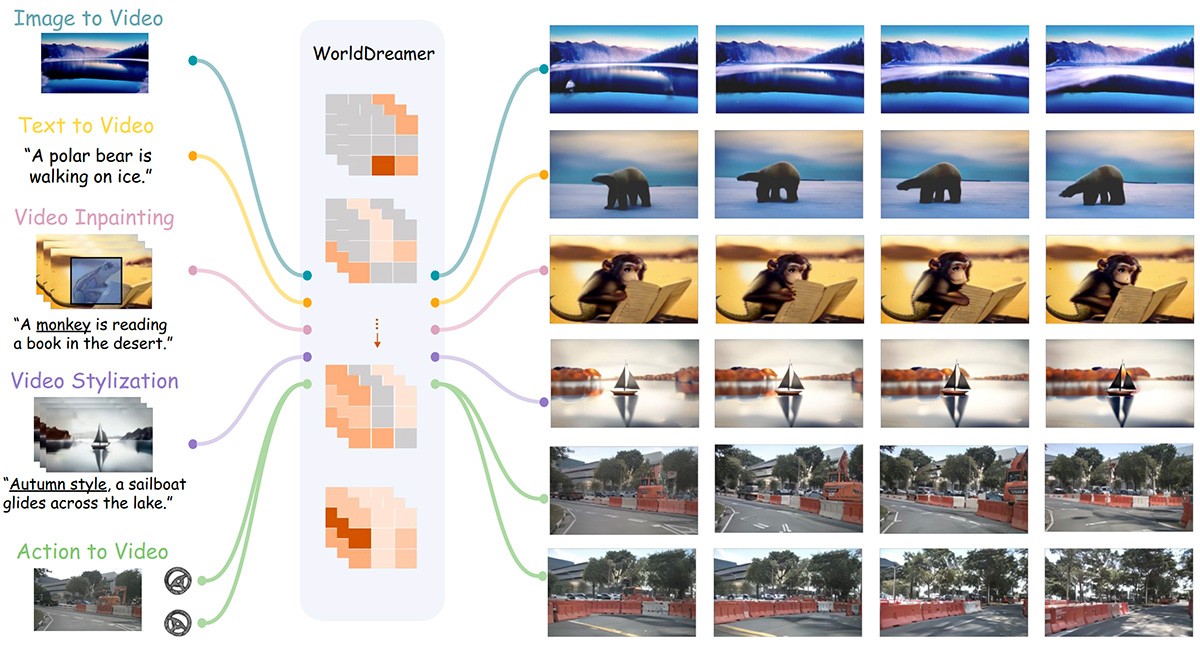
AI模型

DeepSeek R1
DeepSeek R1-Zero 是一款基于纯强化学习训练的推理模型,无需监督微调即可实现高效推理。在 AIME 2024 竞赛中 Pass@1 分数达到 71.0%,展现强大逻辑与数学推理能力。支持长上下文处理,具备自我进化、多任务泛化等特性,并通过开源和蒸馏技术推动模型应用与优化。



Claude 3.5 Haiku
Claude 3.5 Haiku 是 Anthropic 推出的高性能人工智能模型,具备强大的编码能力和低延迟特性,适合复杂推理与问题解决任务。它通过“Unstructured Generalization”算法优化非结构化数据处理,并引入“宪法 AI”确保行为符合道德规范。此外,该模型支持“计算机使用”功能,能够模拟人类与计算机交互,广泛应用于自动化桌面任务、虚拟助手构建、医疗决策支持、教育及客

Transfusion
Transfusion是由Meta公司开发的多模态AI模型,能够同时生成文本和图像,并支持图像编辑功能。该模型通过结合语言模型的下一个token预测和扩散模型,在单一变换器架构上处理混合模态数据。Transfusion在预训练阶段利用了大量的文本和图像数据,表现出强大的扩展性和优异的性能。其主要功能包括多模态生成、混合模态序列训练、高效的注意力机制、模态特定编码、图像压缩、高质量图像生成、文本生成


PaliGemma 2 mix
PaliGemma 2 Mix 是谷歌 DeepMind 推出的多任务视觉语言模型,支持图像描述、目标检测、OCR、文档理解等功能。模型提供多种参数规模和分辨率选项,适用于不同场景。其基于开源框架开发,易于扩展,可通过简单提示切换任务。适用于科学问题解答、文档分析、电商内容生成等多个领域。