高分辨率




Logo Mockup
Logo Mockup是一个在线样机生成工具,用户通过上传他们的logo生成高分辨率的样机效果图并可以下载。

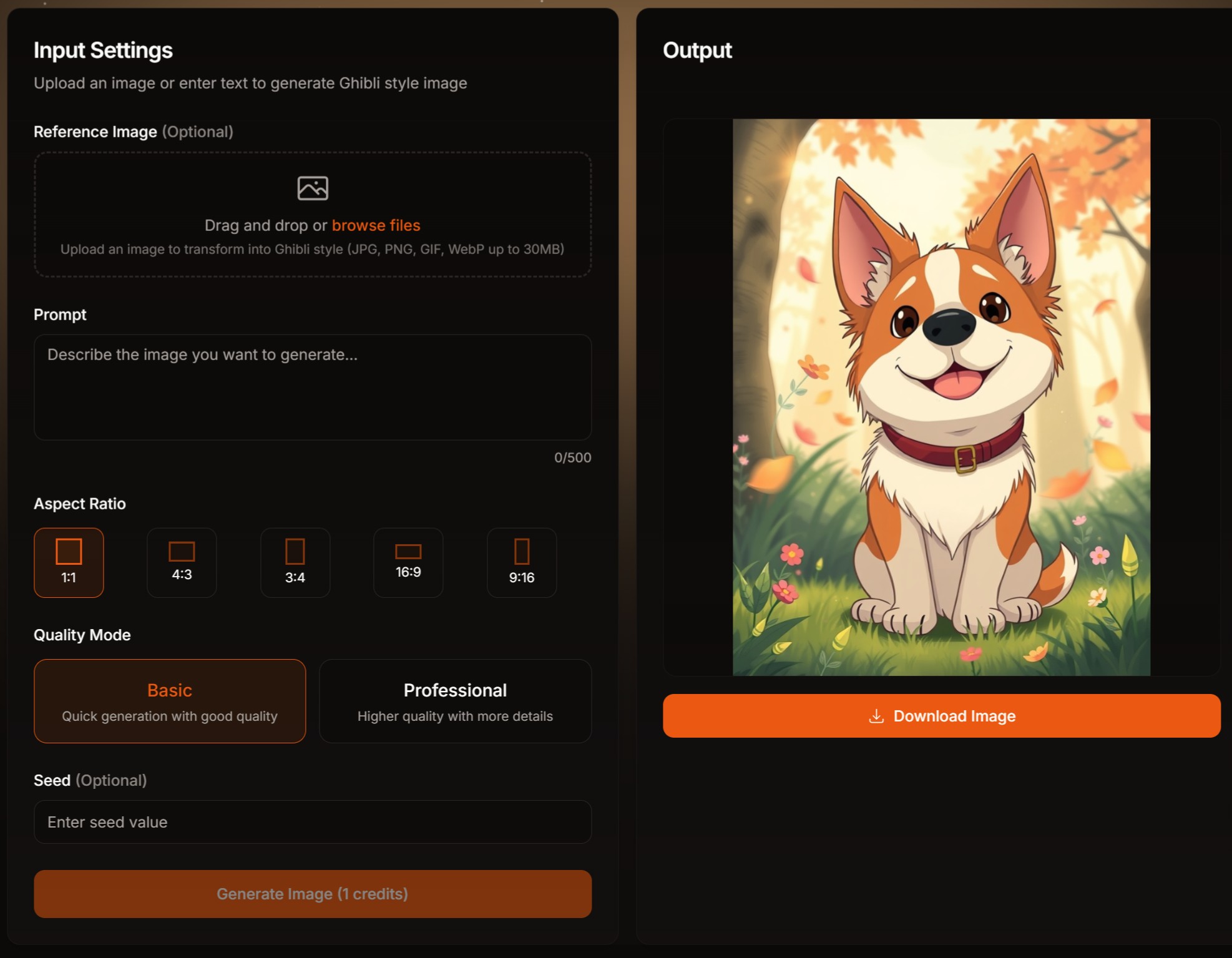

Seedream 3.0
Seedream 3.0是字节跳动推出的AI图像生成模型,支持2K高清输出,3秒内生成高品质图像。优化了小字排版与结构准确性,具备商业级设计能力,适用于海报、插画、电商设计等多场景。支持中英文双语输入,提供高效、精准的图像生成解决方案,适用于设计师与创作者。