CityDreamer4D CityDreamer4D是由南洋理工大学S-Lab开发的4D城市生成模型,通过分离动态与静态元素,结合模块化架构生成逼真城市环境。支持无边界扩展、风格化处理、局部编辑及多视角一致性,适用于城市规划、自动驾驶和虚拟现实等领域。采用高效鸟瞰图表示法与神经场技术,提升生成效率与质量。 AI项目与工具 2025年06月12日 55 点赞 0 评论 598 浏览
VMB VMB是一个由多机构合作研发的多模态音乐生成框架,可从文本、图像和视频等多样化输入生成音乐。它通过文本桥接和音乐桥接优化跨模态对齐与可控性,显著提高了音乐生成的质量和定制化程度。VMB具有增强模态对齐、提升可控性、显式条件生成等特点,适用于电影、游戏、虚拟现实等多个领域。 AI项目与工具 2025年06月12日 84 点赞 0 评论 609 浏览
ACE++ ACE++ 是阿里巴巴通义实验室推出的图像生成与编辑工具,支持指令化操作和上下文感知内容填充。其包含多个专用模型,如 ACE++ Portrait 用于人物肖像生成,ACE++ Subject 保证主题一致性,ACE++ LocalEditing 实现局部图像修改。支持虚拟试穿、风格化编辑、照片修复等多种任务,适用于艺术创作、广告设计及影视制作等领域。技术上采用改进的 LCU++ 架构与两阶段训练 AI项目与工具 2025年06月12日 56 点赞 0 评论 614 浏览
Pika Twists Pika Twists 是 Pika Labs 推出的 AI 视频编辑工具,支持用户精准操控视频中的主体动作和场景,实现创意效果。通过简单描述即可完成角色或物体的动作修改,同时保持画面自然。功能包括主体操控、元素调整、风格化处理、逼真渲染等,适用于短视频、广告、教学等多种场景,提高视频创作效率和表现力。 AI项目与工具 2025年06月11日 85 点赞 0 评论 635 浏览
LATTE3D LATTE3D 是由英伟达多伦多AI实验室开发的一种高效生成高质量3D对象的模型。它基于文本描述,能在约400毫秒内生成逼真的3D内容。LATTE3D采用摊销优化方法,增强了对新提示的适应能力。该模型支持文本到3D合成、快速生成、高质量渲染及3D风格化功能,适用于多种应用场景。 AI项目与工具 2024年01月01日 41 点赞 0 评论 655 浏览
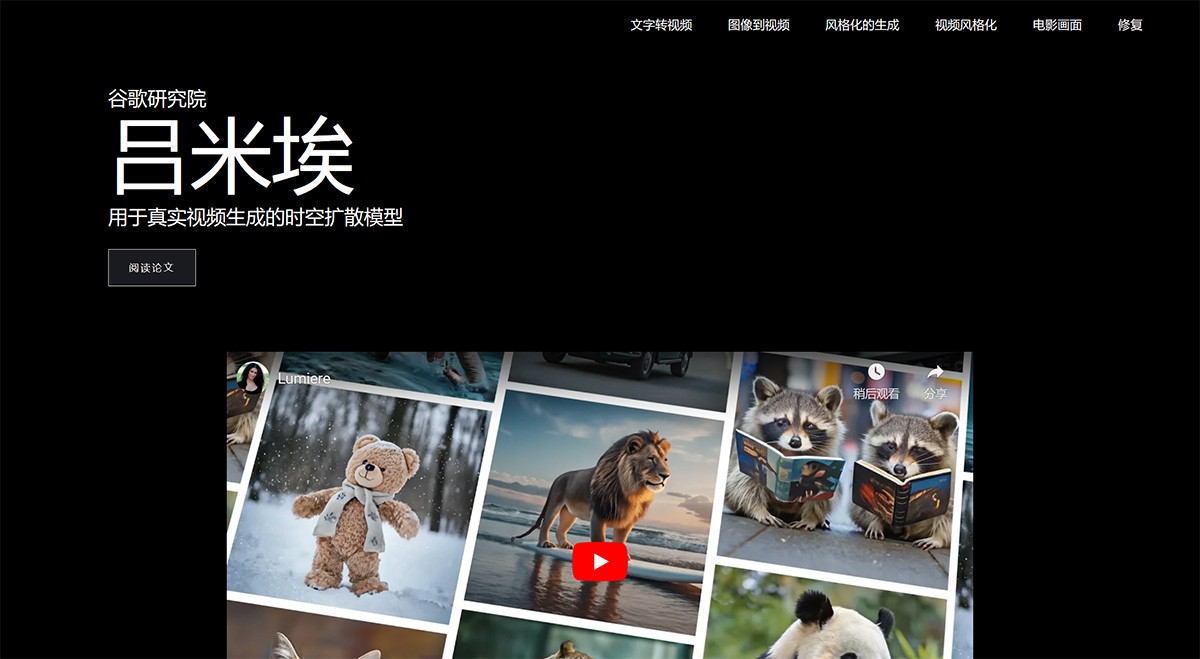
Lumiere 谷歌研究院开发的基于空间时间的文本到视频扩散模型。采用了创新的空间时间U-Net架构,能够一次性生成整个视频的时间长度,确保了生成视频的连贯性和逼真度。 Ai开源项目 2025年06月05日 74 点赞 0 评论 657 浏览
Omni Reference Omni Reference 是 Midjourney V7 提供的一项图像生成辅助功能,允许用户将特定人物、物体或场景嵌入生成图像中。通过 `--oref` 和 `--ow` 参数,用户可灵活控制参考图像的权重与风格融合程度,提升创作精度与多样性。支持 Web 和 Discord 两种平台操作,适用于角色嵌入、产品展示、场景构建等多种应用场景。 AI项目与工具 2025年06月11日 48 点赞 0 评论 668 浏览
Genspark AI幻灯片 一款能够快速将如PDF、Excel、Word等数据格式转化为专业PPT幻灯片的工具,支持一句话交互修改、艺术风格化设计,并可导出为PPTX、PDF等格式 PPT资源 2025年06月05日 71 点赞 0 评论 670 浏览
Still Still-Moving是一款由DeepMind开发的AI视频生成框架,主要功能包括通过轻量级的空间适配器将用户定制的文本到图像(T2I)模型特征适配至文本到视频(T2V)模型,实现无需特定视频数据即可生成定制视频。其核心优势在于结合T2I模型的个性化和风格化特点与T2V模型的运动特性,从而生成高质量且符合用户需求的视频内容。 AI项目与工具 2025年06月12日 49 点赞 0 评论 687 浏览